标签:基础上 动态 lang 添加 第一个 一个 return 了解 分组
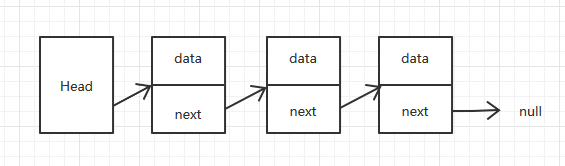
链表是一种常见的数据结构,链表是由一连串的结点组成,这个节点就是链结点,每个链结点都由数据域和指针域两部分组成。
使用链表结构可以克服数组结构需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
链表比较好的一种理解是:将链表看成一个火车,每个车厢之间都是相互连接的,只要找到火车头,就可以找到具体的车身。链表也是,我们只关心它的头。
单向链表的一个链结点包含数据域和下一个链结点的指针。头结点也包含数据域和指针域,但是一般为了方便查找,头节点不写数据,最后一个结点的指针指向空。
创建一个链结点的实体类
public class Node {
// 数据域
public long data;
// 指针域
public Node next;
public Node(long value){
this.data = value;
}
}
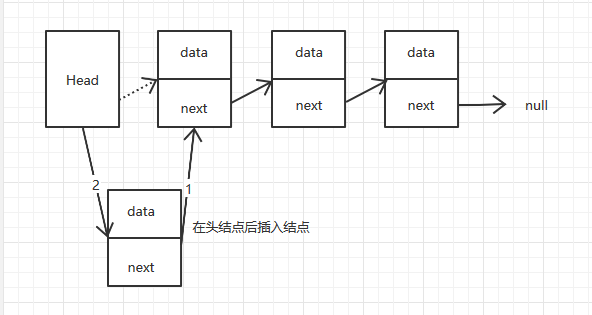
在头节点后插入一个结点,第一步需要将新插入的结点指向头结点指向的结点,第二部将头结点指向新插入的结点。插入结点只需要改变一个引用,所以复杂度为O(1)。
public class LinkList {
private Node head;
/**
* 在头节点之后插入一个节点
*/
public void insertFirst(long value){
Node node = new Node(value);
node.next = head;
head = node;
}
}
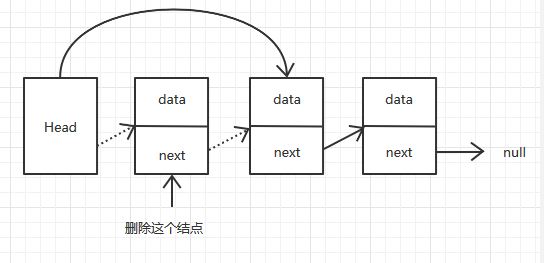
在头结点后删除一个结点,就是让头结点指向这个结点的下一个结点。复杂度也是O(1)。
public Node deleteFirst(){
Node tmp = head;
head = tmp.next;
return tmp;
}
查找需要比对每个结点的数据,理论上查找一个结点平均需要N/2次,所以复杂度为O(N)。
public Node find(long value){
Node current = head;
while (current.data != value){
if(current.next == null){
return null;
}
current = current.next;
}
return current;
}
查找需要比对每个结点的数据,理论上删除一个结点平均需要N/2次,所以复杂度为O(N)。
public Node delete(int value){
Node current = head;
// 当前结点的前一个结点
Node pre = head;
while (current.data != value){
if(current.next == null){
return null;
}
pre = current;
current = current.next;
}
if(current == head){
head = head.next;
}else{
pre.next = current.next;
}
return current;
}
双端链表是在单向链表的基础上,头结点增加了一个尾结点的引用。
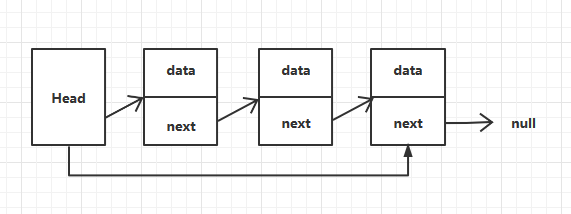
如果链表为空,则设置尾结点就是新添加的结点。复杂度为O(1)。
public class FirstLastLinkList {
private Node first;
private Node last;
/**
* 在头结点之后插入一个节点
*/
public void insertFirst(long value){
Node node = new Node(value);
if(first == null){
last = node;
}
node.next = first;
first = node;
}
}
如果链表为空,则设置头结点为新添加的结点,否则设置尾结点的后一个结点为新添加的结点。复杂度为O(1)。
public void insertLast(long value){
Node node = new Node(value);
if(first == null){
first = node;
}else{
last.next = node;
}
last = node;
}
判断头结点是否有下一个结点,如果没有则设置尾结点为null,复杂度为O(1)。
public Node deleteFirst(){
Node tmp = first;
if(first.next == null){
last = null;
}
first = tmp.next;
return tmp;
}
每个结点除了保存对后一个结点的引用外,还保存着对前一个结点的引用。
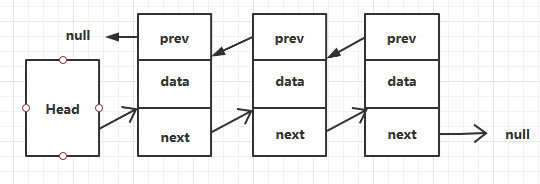
链结点实体类
public class Node {
// 数据域
public long data;
// 后一个结点指针域
public Node1 next;
// 前一个结点指针域
public Node prev;
public Node(long value){
this.data = value;
}
}
如果链表为空,则设置尾结点为新添加的结点,如果不为空,还需要设置头结点的前一个结点为新添加的结点。插入结点只需要改变两个结点的引用,所以复杂度为O(1)。
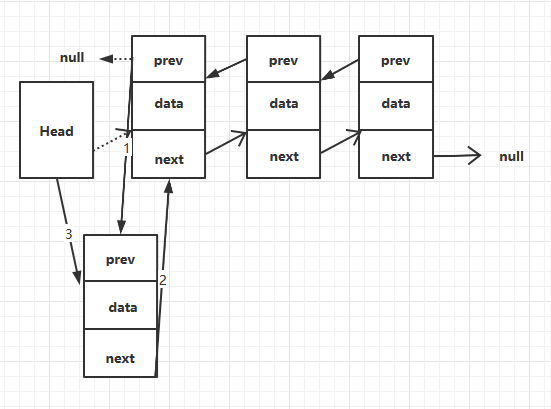
public class DoubleLinkList {
private Node first;
private Node last;
/**
* 在头结点之后插入一个节点
*/
public void insertFirst(long value){
Node node = new Node(value);
if(first == null){
last = node;
} else{
first.prev = node;
}
node.next = first;
first = node;
}
}
如果链表为空,则设置头结点为新添加的结点,否则设置尾结点的后一个结点为新添加的结点。同时设置新添加的结点的前一个结点为尾结点。插入结点只需要改变1个结点的引用,所以复杂度为O(1)。
public void insertLast(long value){
Node node = new Node(value);
if(first == null){
first = node;
}else{
last.next = node;
node.prev = last;
}
last = node;
}
判断头结点是否有下一个结点,如果没有则设置尾结点为null,否则设置头结点的下一个结点的prev为null。复杂度也为O(1)。
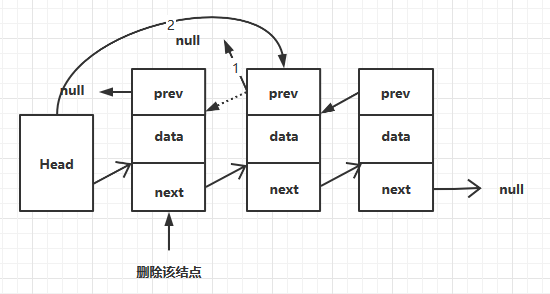
public Node deleteFirst(){
Node tmp = first;
if(first.next == null){
last = null;
}else{
first.next.prev = null;
}
first = tmp.next;
return tmp;
}
如果头结点后没有其他结点,则设置头结点为null,否则设置尾结点的前一个结点的next为null,设置尾结点为前一个结点。复杂度为O(1)。
public Node deleteLast(){
Node tmp = last;
if(first.next == null){
first = null;
}else{
last.prev.next = null;
}
last = last.prev;
return last;
}
链表包含一个头结点和多个结点,头结点包含一个引用,这个引用通常叫做first,它指向链表的第一个链结点。结点的next为null,则意味着这个结点时尾结点。与数组相比,链表更适合做插入、删除操作,而查找操作的复杂度更高。还有一个优势就是链表不需要初始化内存大小,不会造成内存溢出(数组中插入元素个数超过数组长度)或内存浪费(声明的数组长度比实际放的元素长)。
如果觉得文章不错,欢迎关注、点赞、收藏,你们的支持是我创作的动力,感谢大家。
如果文章写的有问题,请不要吝啬,欢迎留言指出,我会及时核查修改。
如果你还想更加深入的了解我,可以微信搜索「Java旅途」进行关注。回复「1024」即可获得学习视频及精美电子书。每天7:30准时推送技术文章,让你的上班路不在孤独,而且每月还有送书活动,助你提升硬实力!
标签:基础上 动态 lang 添加 第一个 一个 return 了解 分组
原文地址:https://www.cnblogs.com/zhixie/p/13594250.html