标签:style blog http io color ar sp 数据 on
感知机(Perceptron)是二类分类的线性分类模型。感知机以一个实数值向量作为输入,计算这些输入的线性组合,如果结果大于某个阈值就输出+1,否则输出-1。下面就从模型,策略和算法三方面来说说这个模型,最后会推导一下算法的收敛性。
感知机模型为:
$\Large h(\mathbf{x}) = \left \{ { +1 , \qquad \sum_{i=1}^{n}w_i x_i > \text{threshold} \atop -1 , \qquad \sum_{i=1}^{n}w_i x_i < \text{threshold}}\right. $
其中 $\mathbf{x}=(x_1,x_2,\ldots,x_n)$ 是输入,每一维输入的一个特征(性别,年龄,工作年限。。。)。
稍微整理得到:
$\large h(\mathbf{x}) = sign(\sum_{i=1}^{n}w_i x_i - \text{threshold }) $
其中 $sign(\mathbf{x})$是符号函数。
换一种我们常见的写法:
$\large h(\mathbf{x}) = sign(\sum_{i=1}^{n}w_i x_i + b) $
不同的$\mathbf{w}$就对应不同的 $h$,感知机模型的假设空间是定义在特征空间的所有线性分类模型,即所有线性函数的集合。
考虑线性方程 :
$\large \sum_{i=1}^{n}w_i x_i + b = 0$
它对应于特征空间的一个超平面,其中$\mathbf{w}$是超平面的法向量,$b$是超平面的截距。这个超平面把特征空间划分为两部分,一部分为正类,一部分为负类。(想想哪边是正,哪边是负?)这个平面我们叫分离超平面(separating hyperplane)。在二维空间,对应的就是直线,在三维空间,对应的就是平面。
如果存在某个超平面能将数据集的正类点和负类点完全正确地划分到超平面的两侧,即对所有标记为+1的实例,都有 $\mathbf{w}\cdot \mathbf{x}+b>0$,对所有标记为-1的实例,都有 $\mathbf{w}\cdot \mathbf{x}+b<0$。则称数据集线性可分,否则数据集线性不可分。
假设训练数据线性可分,感知机学习的目标是求得一个能够将训练集正例和负例完全正确分开的超平面,即求出$\mathbf{w}, b$,为此我们需要确定一个学习策略,即定义一个损失函数,然后将损失函数最小化。很容易想到的是选择误分类点的总数作为损失函数,但这样的损失函数不是$\mathbf{w}, b$的连续可到函数,不好优化,所以我们需要另辟蹊径。损失函数的另外一个选择是误分类点到分离超平面的距离。什么样的点是误分类点呢?对标记y=+1的实例,如果 $\mathbf{w}\cdot \mathbf{x}+b<0$,则会错误的将该点分为负例;对于标记为y=-1的实例,如果 $\mathbf{w}\cdot \mathbf{x}+b>0$,则会错误的将该点分类正例,无论哪种情况,都有 $y(\mathbf{w}\cdot \mathbf{x}+b) < 0$,即$ -y(\mathbf{w}\cdot \mathbf{x}+b) > 0$。
误分类点$(\mathbf{x}^i,y^i)$到超平面S的距离为:
$\large \frac {1}{||\mathbf{w}||} |\mathbf{w} \cdot \mathbf{x}^i+b| = -\frac {1}{||\mathbf{w}||}y^i(\mathbf{w} \cdot \mathbf{x}^i+b) $
假设超平面S的误分类点集合为M,那么所有误分类点到超平面S的总距离为:
$\large -\frac {1}{||\mathbf{w}||} \sum_{\mathbf{x}^i \in M}y^i(\mathbf{w} \cdot \mathbf{x}^i+b) $
不考虑$\frac {1}{||\mathbf{w}||}$,就得到了感知机的损失函数:
$\large L(\mathbf{w},b)= - \sum_{\mathbf{x}^i \in M}y_i(\mathbf{w} \cdot \mathbf{x}^i+b) $
我们采用随机梯度下降法来极小化损失函数,具体地,首先任意选取一个超平面 $\mathbf{w}^0, b^0$,然后利用梯度下降不断极小化目标函数,随机选取一个误分类点$(\mathbf{x}^i,y^i)$,对$\mathbf{w}, b$进行更新:
$\large \mathbf{w}^{k+1} := \mathbf{w}^k + \eta y^i \mathbf{x}^i $
$\large b^{k+1} := b^k + \eta y^i $
其中 $0 < \eta \leq 1 $ 是步长,又称学习率(Learning rate)。
注意,感知机学习算法由于采用不同的初值,或者选取不同的误分类点顺序不一样,解可以不一样。
如果引入 $x_0 = 1$ 和 $w_0 = b$, 则感知机可以表达为:
$\large h(\mathbf{x}) = sign(\sum_{i=0}^{n}w_i x_i ) $
在学习的过程中,我们还是任意随机选取一个超平面$\mathbf{w}$,每遇到一个误分类点,就将$\mathbf{w}$往正确的方向调整一下,直到最后完全把数据集分开,下面我们看看怎么调整$\mathbf{w}, b$:
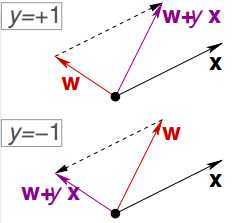
对于y=+1的点,如果分错了,$\mathbf{w}$需要往$\mathbf{x}$方向调整,即:
$\large \mathbf{w} := \mathbf{w}+\mathbf{x}$ 。
对于y=-1的点,如果分错了,$\mathbf{w}$需要往$\mathbf{x}$反方向调整,即:
$\large \mathbf{w} := \mathbf{w} - \mathbf{x}$
无论哪种情况,调整的结果都有:
$\large \mathbf{w} := \mathbf{w} + y\mathbf{x}$
下面看一个逐步调整$\mathbf{w}$的例子:
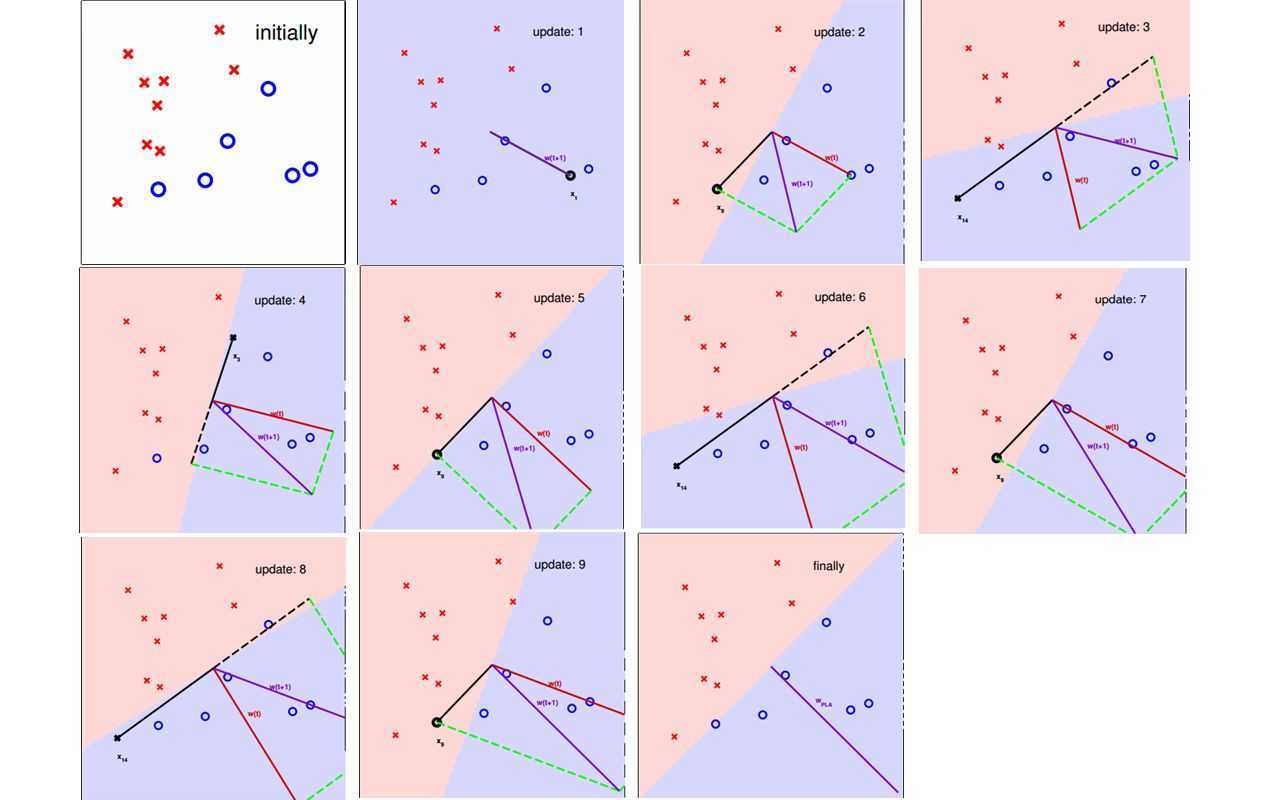
假设数据集线性可分,那么一定存在一个分离超平面能够将数据集完全正确无误的分开,假设这个超平面记为 $\hat {\mathbf{w}^{opt}}$,即对数据集里所有的点,都有:
$\large y^i \hat {\mathbf{w}^{opt}} \cdot \mathbf{x}^i > 0$
即我们记
$\large min(y^i \hat {\mathbf{w}^{opt}} \cdot \mathbf{x}^i ) = \gamma $
$\large max({||\mathbf{x}^i||}^2) = R^2 $
下面从两个方面说明感知机算法是收敛的。
第一方面:每次调整都会让 $\mathbf{w}$和 $\hat {\mathbf{w}_{opt}}$ 更接近一点。
什么叫两个向量比较接近?什么东西描述了两个向量的相似性?对,是内积。考虑从第 $k-1$ 次到第 $k$ 次的迭代,假如点 $(\mathbf{x}^i,y^i)$是被 $\mathbf{w}^{k-1}$ 误分类的点,即:
$\large y^i \mathbf{w}^{k-1} \cdot \mathbf{x}^i < 0 $
则 $\mathbf{w}$ 的更新为:
$\large \mathbf{w}^{k} = \mathbf{w}^{k-1}+ \eta y^i \mathbf{x}^i $
$\large \mathbf{w}^{k} \cdot \hat{\mathbf{w}^{opt} } = \mathbf{w}^{k-1} \cdot \hat{\mathbf{w}^{opt}} + \eta y^i \hat{\mathbf{w}^{opt}} \cdot \mathbf{x}^i \geq \mathbf{w}^k \cdot \hat{\mathbf{w}^{opt}} + \eta \gamma \geq \mathbf{w}^{k-2} \cdot \hat{\mathbf{w}^{opt}} + 2 \eta \gamma \geq \ldots \geq \ldots \geq k \eta \gamma $
第二方面:每次调整都不会使 $\mathbf{w}$ 变化太快
为此我们计算 $\mathbf{w}$ 的 $L_2$ 范数,也即就是 $\mathbf{w}$ 的长度。
$\large {||\mathbf{w}^k||}^2 = {||\mathbf{w}^{k-1}||}^2 + 2 \eta y^i \mathbf{w}^{k-1} \cdot \mathbf{x}^i + \eta ^ 2 {||\mathbf{x}^i||}^2 \leq {||\mathbf{w}^{k-1}||}^2 + \eta ^ 2 {||\mathbf{x}^i||}^2 \leq {||\mathbf{w}^{k-1}||}^2 + \eta ^ 2 R^2 \leq {||\mathbf{w}^{k-2}||}^2 + 2 \eta ^ 2 R^2 \leq \ldots \leq k \eta ^2 R^2 $
结合两个方面得出的不等式:
$\large k \eta \gamma \leq \mathbf{w}^{k} \cdot \hat{\mathbf{w}^{opt}} \leq ||\mathbf{w}^{k}||||\hat{\mathbf{w}^{opt}}|| \leq \sqrt {k} \eta \gamma $
所以:
$ \large k \leq \frac {R^2}{\gamma ^2} $
从上面的式子可以看出,误分类的次数是有上限的,经过有限次搜索可以找到将训练数据完全正确分开的分离超平面。
参考资料
统计学习方法 李航著
机器学习基石 https://class.coursera.org/ntumlone-002
机器学习 Tom M.Mitchell著
标签:style blog http io color ar sp 数据 on
原文地址:http://www.cnblogs.com/dudi00/p/4089052.html