标签:这一 目标 acp 下一跳 多个 简单的 支持 asi Opens
作者:Umberto Manferdini 译者:TF编译组在数据中心内部,虚拟化正成为占据主导地位的技术。这带来了“虚拟网络”等一些新的管理要素。虚拟网络允许虚拟机在现有的underlay网络(IP Fabric)上,利用软件功能和overlay技术相互通信。
当然,即使在现代数据中心内部,虚拟化也不是唯一的信条。我们仍然有物理设备和裸金属服务器。而且,虚拟机和裸金属服务器通常不是孤立的世界,它们需要彼此集成。
这种集成可能意味着让虚拟机和BMS出现在同一子网中。此解决方案通常称为BMS集成。
利用vRouter对E***原生的支持,同时与现有IP Fabric具备互操作性,就可以实现该目标。
与过去涉及附加元素(TSN节点)和协议(OVSDB)的解决方案不同,如今,我们仅依靠标准协议——E***。E***正在成为数据中心内部事实上的标准。由于SDN控制器可以轻松地与底层IP Fabric集成在一起,并且它们都使用BGP、E***和VXLAN,这带来了巨大的优势。
此外,使用标准的和众所周知的协议,可以避免供应商锁定,向多供应商的场景开放。
以终为始,这就是我们想要实现的目标:
一个经典的局域网!
实际上,在这种简单的网络模型背后,许多参与者都扮演着角色并发挥自己的作用。
这是真实的场景: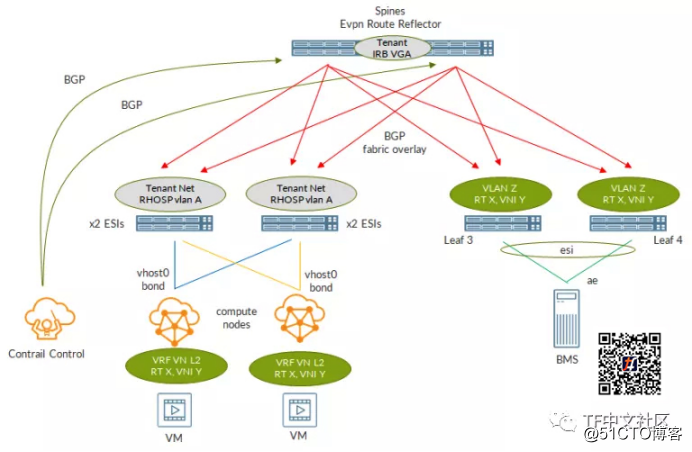
让我们一次解决一个问题。
首先,我们的DC具有标准IP Fabric。对于标准,我们是指使用VXLAN进行传输的基于BGP的结构。Overlay BGP用于交换E***路由。为了减少BGP会话的数量,将spine用作路由反射器,从而避免leaf-to-leaf的全连接。
Tungsten Fabric(注:原文为Contrail,本文以功能一致的Tungsten Fabric替换)部署在数据中心内。Tungsten Fabric overlay网络(通常称为Tungsten Fabric控制+数据网络)将映射到在Fabric上配置的VLAN(L2服务)。在RHOSP实现中,此网络通常映射到RHOSP租户网络。这意味着每个Tungsten Fabric节点将在此网络上有一个IP。具体来说,计算节点在该网络上将具有接口vhost0(VTEP接口)。
Tungsten Fabric控制+数据网络(在RHOSP环境中为Tenant网络)在Fabric上具有配置为IRB接口的网关。在这种情况下,IRB配置在spine上。这两个spine共享一个相同的IP地址,称为VGA,用作LAN网关。
在spine配置IRB的模型,称为中央路由桥接(CRB)。还有一种情况,我们可以将L3 GW功能(IRB接口)移到leaf上,这样该模型就称为边缘路由桥接(ERB)。CRB与ERB的比较不在本文讨论范围之内。
Tungsten Fabric控制节点与IP Fabric spine之间具有BGP会话,在此会话上交换E***路由。这使IP Fabric可以学习Tungsten Fabric E***路由,反之亦然。这是实现BMS集成的关键,因为我们需要BMS相关的E***路由才能到达Tungsten Fabric,同时需要Tungsten Fabric虚拟机E***路由才能到达与BMS连接的leaf。
裸金属服务器是多宿主到一对leaf,并映射到IP Fabric上的VLAN。
另一方面,虚拟机连接到由Tungsten Fabric管理的L2虚拟网络。
为了实现BMS集成,需要使用BMS所属的L2 VLAN来“缝合”L2虚拟网络。
这是通过利用Tungsten Fabric的E***原生支持以及其与IP Fabric的集成来实现的。稍后我们将进行详细介绍。
IP Fabric必须正确配置。我们假设Tungsten Fabric集群已经启动并正在运行,那么Tungsten Fabric基础结构网络(RHOSP网络)已经就位。我们还假定Tungsten Fabric控制器已建立好启用了E***族的spine的BGP会话。
剩下的就是创建BMS VLAN和与E***相关的配置。
由于我们不希望在“扩展的2层网络”上使用网关,因此不需要设置IRB逻辑接口。其结果是,配置仅涉及BMS连接到的两个leaf。在这种情况下,spine将仅接收/通告E***路由并转发overlay流量(VXLAN数据包)。
两个leaf上的配置是相同的,因此我只演示一次。
首先,我们配置针对BMS的聚合接口: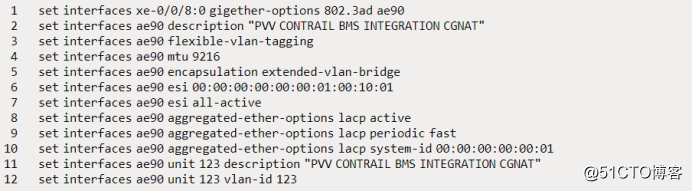
这是带有一些额外“调整(tweaks)”的标准AE接口。我们定义了两个leaf上都必须匹配的ESI,为了使用E***管理多宿主这是必须的。然后,我们还需要两个leaf上的LACP系统ID匹配。这是“欺骗”BMS所必需的;如果在两个链接上的系统ID相同,即使实际上在另一侧有两个不同的设备(leaf),BMS也将假定它已连接到单个系统。同样,这是在启用E***的DC中配置多宿主的标准最佳实践。
接下来,我们转到E***部分。
我们需要一个新的VNI:
VNI被分配了route target(实现BMS集成的关键参数)。Leaf E***策略必须进行更新以反映新服务(service)。
最后,添加一个新的VLAN:
作为可选项,可以通过在overlay BGP会话上向spine添加route target,来优化E***路由交换:
这对于leaf(和IP Fabric)的配置来说,已经足够了。
如果需要用作LAN网关的IRB接口,则在spine设备上还需要一些其它配置。
BMS配置非常简单。
BMS可以是我们想要的任何设备;例如,支持绑定的Centos服务器。
不过,这里我用了Juniper MX。以下代码行已加载到设备上: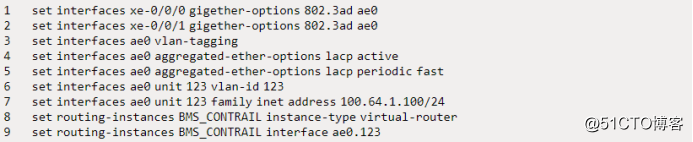
接口被分配给虚拟路由器,以便在路由方面将其与设备的其余部分隔离。
Tungsten Fabric配置涉及多个方面。
如前所述,我们假设Tungsten Fabric控制器和IP Fabric spine之间的BGP会话已经存在。
可以通过在Tungsten Fabric GUI中检查BGP路由器来验证这一点: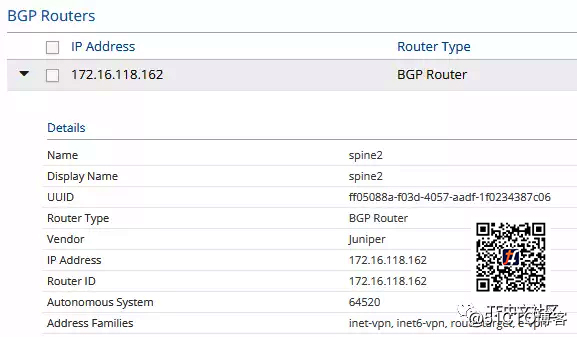
重要的是E***族被启用。
接下来,我来创建一个虚拟网络: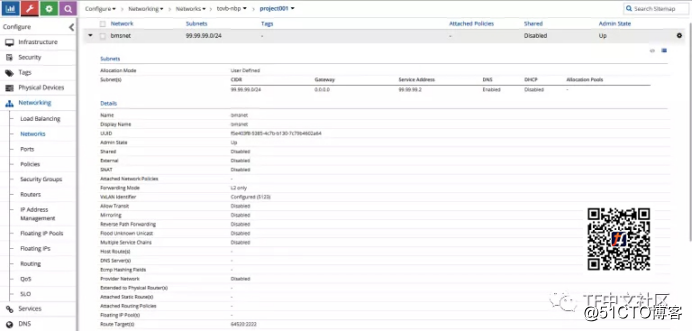
虚拟网络是2层的,因为其转发模式仅设置为L2。
提供了一个VNI,5123不是一个随机值。如果您还记得,那是我之前在leaf上配置的值。为了从overlay数据平面的角度缝合Tungsten Fabric和IP Fabric,这是必不可少的。
如先前所预期的,另一个关键值是route target。这与在fabric上设置的相同。这样,我们可以确保将fabric中的E*** BGP路由,按预期导入到Tungsten Fabric虚拟网络中,反之亦然。
虚拟网络也被分配了CIDR。由于“历史原因”,该网络地址的存在是因为Openstack/Neutron需要在每个网络上配置CIDR。实际上,作为仅为L2的VN,Tungsten Fabric没有针对该对象的L3(inet)路由表,只有MAC表。这意味着我们可以在虚拟机内部配置所需的任何IP地址。在vRouter级别仅检查MAC地址一致性就可以(也就是说,不要更改虚拟机上的MAC地址)。
在此虚拟网络上,我们连接两个虚拟机,因此该网络上有两个端口:
每个端口都有自己的MAC地址。这些MAC地址很重要,因为它们将被通告到E***中。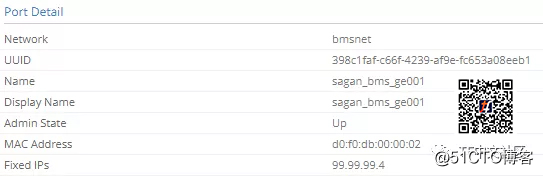
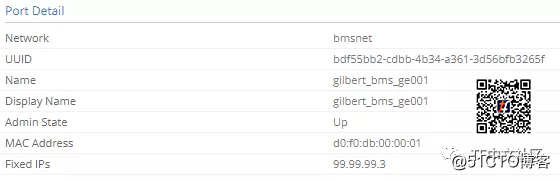
MAC地址应该在虚拟网络E***表中可见: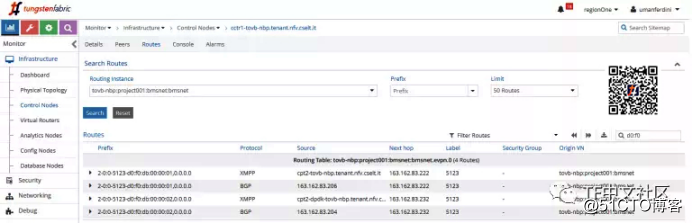
BGP和XMPP路由都存在(每个MAC地址2个路由,每个协议1个路由)。
请注意,VNI等于5123。
现在,一切准备就绪,BMS集成应该已经完成。
下面该进行验证了!
在BMS上,我记下了集成接口的MAC:
在这里,我假设到处都配置了route target。
我检查在leaf(连接到BMS)和spine之间是否相互交换route target:
1{master:0}[edit]
2netconfadmin@nfv-vb-leaf-08# run show route receive-protocol bgp 172.16.118.162 table bgp.rtarget.0 | match 2222
3 64520:64520:2222/96
4
5{master:0}[edit]
6netconfadmin@nfv-vb-leaf-08# run show route advertising-protocol bgp 172.16.118.162 table bgp.rtarget.0 | match 2222
7 64520:64520:2222/96可以在另一个leaf上进行相同的检查。
然后,我将验证在spine和Tungsten Fabric控制器之间交换了相同的路由目标:
1{master:0}[edit]
2netconfadmin@nfv-vb-spine-01# run show route advertising-protocol bgp 163.162.83.205 table bgp.rtarget.0 | match 2222
3 64520:64520:2222/96
4
5{master:0}[edit]
6netconfadmin@nfv-vb-spine-01# run show route receive-protocol bgp 163.162.83.205 table bgp.rtarget.0 | match 2222
7 64520:64520:2222/96可以在第二个spine上进行相同的操作。
一旦知道route target交换正常,就可以转到实际的MAC路由。
从学习了BMS MAC的leaf中,我将检查E*** T2路由是否已发送到spine:
1{master:0}[edit]
2netconfadmin@nfv-vb-leaf-08# run show route advertising-protocol bgp 172.16.118.162 table bgp.e***.0 e***-ethernet-tag-id 5123 match-prefix 2*
3
4bgp.e***.0: 1087 destinations, 1979 routes (1087 active, 0 holddown, 0 hidden)
5 Prefix Nexthop MED Lclpref AS path
6 2:172.16.118.170:1::5123::88:e0:f3:b3:1f:c0/304 MAC/IP
7* Self 100 I
8 2:172.16.118.170:1::5123::88:e0:f3:b3:1f:c0::100.64.1.100/304 MAC/IP
9* Self 100 I是的,它们在那里!MAC和MAC/IP路由。
该路由应从spine发送到Tungsten Fabric:
1{master:0}[edit]
2netconfadmin@nfv-vb-spine-01# run show route advertising-protocol bgp 163.162.83.205 table bgp.e***.0 e***-ethernet-tag-id 5123 match-prefix 2:172*
3
4bgp.e***.0: 4242 destinations, 7157 routes (4242 active, 0 holddown, 0 hidden)
5 Prefix Nexthop MED Lclpref AS path
6 2:172.16.118.170:1::5123::88:e0:f3:b3:1f:c0/304 MAC/IP
7* 172.16.118.170 100 I
8 2:172.16.118.170:1::5123::88:e0:f3:b3:1f:c0::100.64.1.100/304 MAC/IP
9* 172.16.118.170 100 I路由就在那里!
结果就是,我们在Tungsten Fabric虚拟网络MAC表中找到了MAC信息: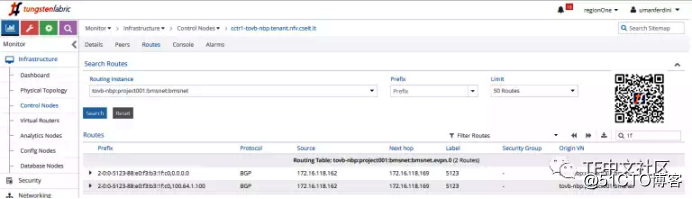
下一跳是连接到BMS的leaf的VTEP地址(设计上是环回地址),该leaf学习了BMS MAC并通告了类型2。
此路由交换总结如下: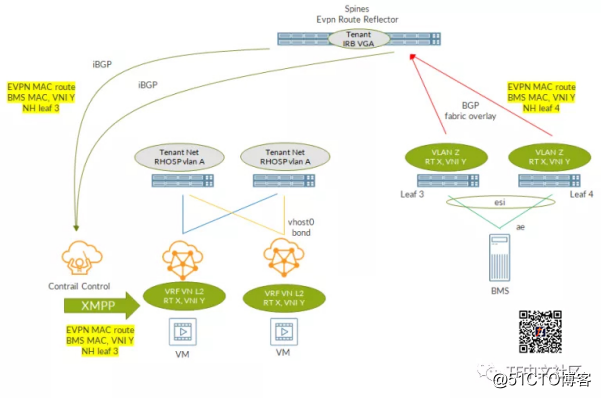
请注意,最后一步使用XMPP,因为它是Tungsten Fabric控制器和计算节点之间使用的协议。
当然,另一个leaf也可能会通告T2路由,这取决于它是否在本地学习MAC。
现在,我将检查从Tungsten Fabric到leaf的路由。
在Spine上,我将检查是否从Tungsten Fabric控制器收到了VM的MAC路由:
1{master:0}[edit]
2netconfadmin@nfv-vb-spine-01# run show route receive-protocol bgp 163.162.83.205 table bgp.e***.0 e***-ethernet-tag-id 5123
3
4bgp.e***.0: 4232 destinations, 7137 routes (4232 active, 0 holddown, 0 hidden)
5 Prefix Nexthop MED Lclpref AS path
6 2:163.162.83.222:7::5123::d0:f0:db:00:00:01/304 MAC/IP
7* 163.162.83.222 200 100 ?
8 2:163.162.83.232:4::5123::d0:f0:db:00:00:02/304 MAC/IP
9 163.162.83.232 200 100 ?
10 3:163.162.83.222:7::5123::163.162.83.222/248 IM
11* 163.162.83.222 200 100 ?
12 3:163.162.83.232:4::5123::163.162.83.232/248 IM
13 163.162.83.232 200 100 ?有4个路由(2个MAC,2个MAC/IP);这是因为有2个虚拟机。请注意虚拟机使用的IP。如果您还记得,我们确实在VN内配置了CIDR 99.99.99.0/24。无论如何,如前所述,作为L2 VN,我们可以在VM内配置所需的任何IP(但是我们需要保持MAC地址不变,这超过了本文的范围)。
从那里,路由一定会到达leaf:
1{master:0}[edit]
2netconfadmin@nfv-vb-leaf-07# run show route receive-protocol bgp 172.16.118.162 table bgp.e***.0 e***-ethernet-tag-id 5123
3
4bgp.e***.0: 1088 destinations, 1713 routes (1088 active, 0 holddown, 0 hidden)
5 Prefix Nexthop MED Lclpref AS path
6 2:172.16.118.170:1::5123::88:e0:f3:b3:1f:c0/304 MAC/IP
7 172.16.118.170 100 I
8 2:172.16.118.170:1::5123::88:e0:f3:b3:1f:c0::100.64.1.100/304 MAC/IP
9 172.16.118.170 100 I
10 3:172.16.118.170:1::5123::172.16.118.170/248 IM
11 172.16.118.170 100 I是的,都在那里!
结果就是,在leaf上,以太网表应反映以下内容:
1netconfadmin@nfv-vb-leaf-07# run show ethernet-switching table vlan-name VLAN-BMSINT
2
3MAC flags (S - static MAC, D - dynamic MAC, L - locally learned, P - Persistent static
4 SE - statistics enabled, NM - non configured MAC, R - remote PE MAC, O - ovsdb MAC)
5
6
7Ethernet switching table : 3 entries, 3 learned
8Routing instance : default-switch
9 Vlan MAC MAC Logical Active
10 name address flags interface source
11 VLAN-BMSINT 88:e0:f3:b3:1f:c0 DR ae90.123
12 VLAN-BMSINT d0:f0:db:00:00:01 D vtep.32778 163.162.83.222
13 VLAN-BMSINT d0:f0:db:00:00:02 D vtep.32779 163.162.83.232BMS MAC只有一个条目。标志DR的意思是“远程(remote)”。这告诉我们MAC实际上是由另一个leaf学习的。
另外两个路由指向虚拟机。
转发接口是VTEP IFL。当数据包必须封装到VXLAN隧道中时,使用接口VTEP。最右边的值是VTEP目标地址:在这种情况下,是托管VM的计算节点的vhost0地址。
这里也可以看到:
1netconfadmin@nfv-vb-leaf-07# run show interfaces vtep.32778
2 Logical interface vtep.32778 (Index 947) (SNMP ifIndex 1085)
3 Flags: Up SNMP-Traps Encapsulation: ENET2
4 VXLAN Endpoint Type: Remote, VXLAN Endpoint Address: 163.162.83.222, L2 Routing Instance: default-switch, L3 Routing Instance: default
5 Input packets : 0
6 Output packets: 4
7 Protocol eth-switch, MTU: Unlimited
8 Flags: Trunk-Mode虽然我们没有提到,但是与类型2路由类似,E***类型1路由也完成了交换。这意味着可以使用诸如aliasing之类的原生E***机制,并且Tungsten Fabric可以利用它。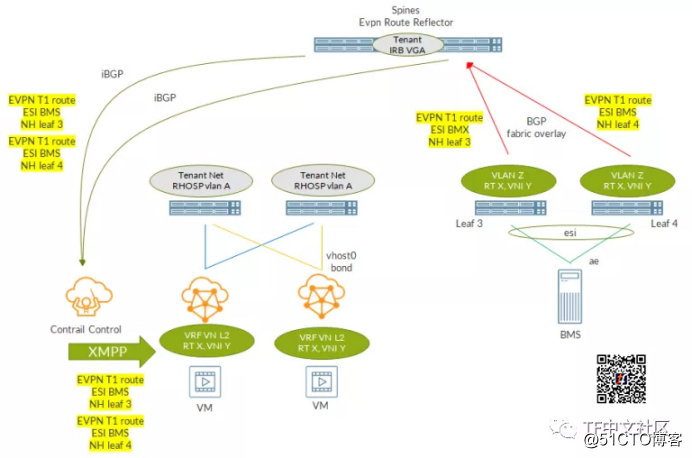
就是这个!BMS集成已经实现了,VM可以与BMS通信,反之亦然。
让我们看一下流量的路径。
我分析了VM到BMS的用例,但对BMS到VM的用例也进行了同样的考虑。
下图总结了所有阶段:
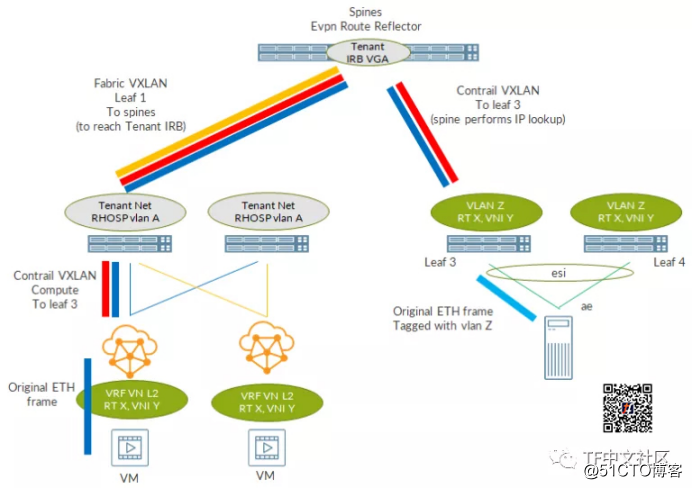
首先,VM发送目标为BMS IP的IP/Ethernet数据包。
数据包到达在其MAC表中执行查找的vRouter(请记住,虚拟网络仅是L2)。从那里,它匹配从spine接收到的BGP路由,将原始数据包封装到发往BMS多宿主的leaf的VXLAN标头中。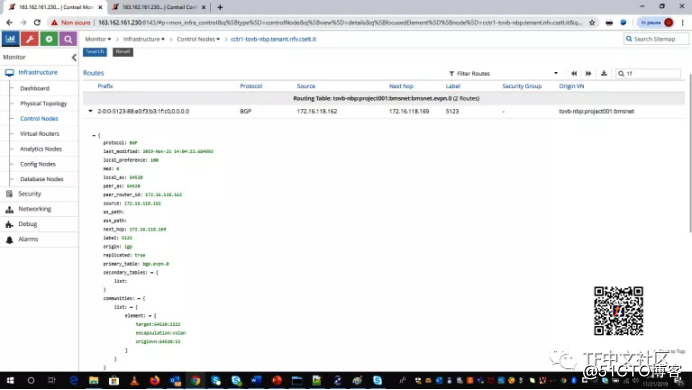
使用虚拟网络内部配置的VNI(5123)将数据包封装在VXLAN中。计算节点执行IP查找,以了解如何达到leaf环回。该查找在“常规”服务器路由表(在“ip route”中看到的表)中进行。当然,必须有一条通往leaf环回的路由。这些路由可以手动添加(从而可以永久生效),也可以在Tungsten Fabric安装过程中进行设置(使用RHOSP可以在NIC模板级别完成)。
查找应告知必须将数据包发送到Tungsten Fabric的控制+数据(RHOSP租户网络)网关。此地址是在spine上配置的IRB。
此时,VXLAN数据包作为目标MAC地址为IRB(租户网络网关)MAC的以太网帧离开计算节点。数据包到达与RHOSP租户网络关联的逻辑接口上的“本地”leaf上。MAC查找此时发生,并且leaf发现必须将数据包封装在发往spine的VXLAN隧道中。这时,VNI与Fabric中的RHOSP租户的VLAN(此处未显示)关联。是的,另一个VXLAN隧道。在leaf和spine之间,我们有一个由计算节点创建的VXLAN数据包,该数据包封装到由leaf创建的另一个VXLAN数据包中。
“双重封装”的VXLAN数据包到达了spine。Spine发现到目标MAC是其拥有的MAC(IRB MAC);它解封装外部VXLAN标头并执行IP查找。查找针对内部VXLAN数据包目标地址,即leaf环回。该地址是可用的,这要归功于IP Fabric的underlay路由交换。Spine只是将数据包转发到连接BMS的leaf上。
VXLAN数据包到达leaf。Leaf基于VN(5123)对其进行解封装,并将数据包放入BMS vlan(123)。MAC查找在此时发生,并且找到了BMS si的匹配项。
最后,根据leaf和BMS之间的VLAN标记配置的原始IP数据包,将被发送到原始目的地!
我们终于到达了BMS。
这段漫长的旅程涉及到两个overlay:由VXLAN隧道compute-to-leaf表示的Tungsten Fabric overlay,以及由VXLAN隧道leaf-to-spine表示的fabric overlay。
这里比较复杂,但是从用户的角度来看,它看起来确实像是BMS和VM在同一子网中。
关于复杂性……真的有那么复杂吗?
某些配置可以看作是“day 0”,就是在设置DC时只需配置一次。这包括针对spine和IP Fabric E*** overlay的Tungsten Fabric BGP会话。
随后,实现BMS集成就相当容易了。
在Tungsten Fabric上,我们只需要一个L2 VN。在fabric上,我们只需要标准的L2服务。
重要的是VNI和router target匹配,以便允许正确的路由导入。
以上,就是关于Tungsten Fabric虚拟网络的BMS部分的分享。
原文链接:
https://iosonounrouter.wordpress.com/2019/11/21/bare-metal-integration-in-a-contrail-world/
推荐阅读
细说TF服务链

关注微信:TF中文社区
如何在Tungsten Fabric上整合裸金属服务器(附配置验证过程)
标签:这一 目标 acp 下一跳 多个 简单的 支持 asi Opens
原文地址:https://blog.51cto.com/14638699/2528494