标签:vat restore 共享 join enc 没有 extends over ISE
之前看 Flink Source 的 metrics 时候,看到 FlinkKafkaConsuemr 消费 Kafka 数据的代码,感觉比较有意思,就仔细看下了
大致流程如下:
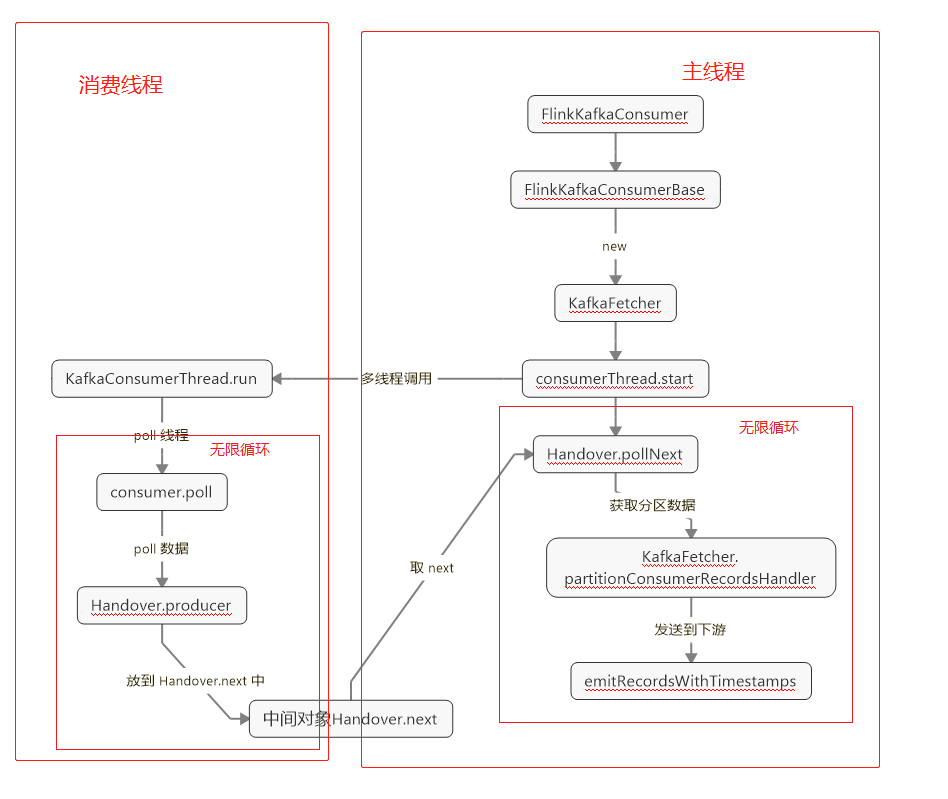
FlinkKafKaConsuemr 的启动流程就不细讲了,直接跳到 FlinkKafkaConsumerBase.run 中,创建 KafkaFetcher,并启动 拉取kafka 数据的循环
@Override public void run(SourceContext<T> sourceContext) throws Exception { // new 一个 KafkaFetcher(消费kafka 的类) // from this point forward: // - ‘snapshotState‘ will draw offsets from the fetcher, // instead of being built from `subscribedPartitionsToStartOffsets` // - ‘notifyCheckpointComplete‘ will start to do work (i.e. commit offsets to // Kafka through the fetcher, if configured to do so) this.kafkaFetcher = createFetcher( sourceContext, subscribedPartitionsToStartOffsets, watermarkStrategy, (StreamingRuntimeContext) getRuntimeContext(), offsetCommitMode, getRuntimeContext().getMetricGroup().addGroup(KAFKA_CONSUMER_METRICS_GROUP), useMetrics); // depending on whether we were restored with the current state version (1.3), // remaining logic branches off into 2 paths: // 1) New state - partition discovery loop executed as separate thread, with this // thread running the main fetcher loop // 2) Old state - partition discovery is disabled and only the main fetcher loop is executed if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) { // 执行 拉取 循环 kafkaFetcher.runFetchLoop(); } else { runWithPartitionDiscovery(); } } private void runWithPartitionDiscovery() throws Exception { final AtomicReference<Exception> discoveryLoopErrorRef = new AtomicReference<>(); createAndStartDiscoveryLoop(discoveryLoopErrorRef); kafkaFetcher.runFetchLoop(); ... }
再看下 KafkaFetcher 的 runFetchLoop 方法: 启动消费 kafka topic 的线程,并获取数据(同步的 Handover 在两个线程间使用全局变量共享数据)
@Override public void runFetchLoop() throws Exception { try { // kick off the actual Kafka consumer // 启动消费 Kafka topic 的线程 consumerThread.start(); // 无限循环,从 handover 中获取 kafka 数据 while (running) { // this blocks until we get the next records // it automatically re-throws exceptions encountered in the consumer thread // 从 handover 取 消费出来的 kafka 数据 final ConsumerRecords<byte[], byte[]> records = handover.pollNext(); // get the records for each topic partition // 获取订阅分区的数据 for (KafkaTopicPartitionState<T, TopicPartition> partition : subscribedPartitionStates()) { List<ConsumerRecord<byte[], byte[]>> partitionRecords = records.records(partition.getKafkaPartitionHandle()); // 处理 一下 partitionConsumerRecordsHandler(partitionRecords, partition); } } } finally { // this signals the consumer thread that no more work is to be done consumerThread.shutdown(); } // on a clean exit, wait for the runner thread try { consumerThread.join(); } catch (InterruptedException e) { // may be the result of a wake-up interruption after an exception. // we ignore this here and only restore the interruption state Thread.currentThread().interrupt(); } } protected void partitionConsumerRecordsHandler( List<ConsumerRecord<byte[], byte[]>> partitionRecords, KafkaTopicPartitionState<T, TopicPartition> partition) throws Exception { for (ConsumerRecord<byte[], byte[]> record : partitionRecords) { // 反序列化 数据 deserializer.deserialize(record, kafkaCollector); // emit the actual records. this also updates offset state atomically and emits // watermarks // emit 数据 带上 timestamp(这里也可以看出,从kafka 消费的数据, // 带着 数据的 分区、offset、timestamp 信息,这些属性在下游使用正确的姿势,都是可以在 下游算子获取到的) emitRecordsWithTimestamps( kafkaCollector.getRecords(), partition, record.offset(), record.timestamp()); if (kafkaCollector.isEndOfStreamSignalled()) { // end of stream signaled running = false; break; } } }
Fetcher 线程就是这样的
看下 consumerThread , KafkaFetcher 初始化的时候,会同时创建一个 KafkaConsumerThread 的对象,KafkaConsumerThread 集成了 Thread 类,所以是多线程的
public class KafkaConsumerThread<T> extends Thread
@Override public void run() { // this is the means to talk to FlinkKafkaConsumer‘s main thread // 中转 对象 final Handover handover = this.handover; // This method initializes the KafkaConsumer and guarantees it is torn down properly. // This is important, because the consumer has multi-threading issues, // including concurrent ‘close()‘ calls. try { // 消费线程启动的时候,会创建 kafka consumer this.consumer = getConsumer(kafkaProperties); } catch (Throwable t) { handover.reportError(t); return; } // from here on, the consumer is guaranteed to be closed properly try { // register Kafka‘s very own metrics in Flink‘s metric reporters if (useMetrics) { // register Kafka metrics to Flink // 注册 kafka 的 metrics 到 Flink 中,从 webUi 的 metrics 可以找到 kafka 的metrics Map<MetricName, ? extends Metric> metrics = consumer.metrics(); if (metrics == null) { // MapR‘s Kafka implementation returns null here. log.info("Consumer implementation does not support metrics"); } else { // we have Kafka metrics, register them for (Map.Entry<MetricName, ? extends Metric> metric: metrics.entrySet()) { consumerMetricGroup.gauge(metric.getKey().name(), new KafkaMetricWrapper(metric.getValue())); // TODO this metric is kept for compatibility purposes; should remove in the future subtaskMetricGroup.gauge(metric.getKey().name(), new KafkaMetricWrapper(metric.getValue())); } } } // main fetch loop // 主要的消费 无限循环() while (running) { // check if there is something to commit // 提交 kafka 的 offset if (!commitInProgress) { // get and reset the work-to-be committed, so we don‘t repeatedly commit the same final Tuple2<Map<TopicPartition, OffsetAndMetadata>, KafkaCommitCallback> commitOffsetsAndCallback = nextOffsetsToCommit.getAndSet(null); if (commitOffsetsAndCallback != null) { log.debug("Sending async offset commit request to Kafka broker"); // also record that a commit is already in progress // the order here matters! first set the flag, then send the commit command. commitInProgress = true; consumer.commitAsync(commitOffsetsAndCallback.f0, new CommitCallback(commitOffsetsAndCallback.f1)); } } // get the next batch of records, unless we did not manage to hand the old batch over // 只有 records 是 null 的时候,才 poll 数据,不然就覆盖了(这里涉及到多线程调用,如果当前线程在 wait 或 就绪状态 就会没办法 转移 records ) if (records == null) { try { records = consumer.poll(pollTimeout); } catch (WakeupException we) { continue; } } try { // 处理消费到的数据 handover.produce(records); records = null; } catch (Handover.WakeupException e) { // fall through the loop } } }
KafkaConsuemrThread 做的事情就是,从Kafka 消费数据,通过 handover.producer 转移数据
下面就到了中转数据的 Handover 类了
贴下 Handover 类的注释:
/** * The Handover is a utility to hand over data (a buffer of records) and exception from a * <i>producer</i> thread to a <i>consumer</i> thread. It effectively behaves like a * "size one blocking queue", with some extras around exception reporting, closing, and * waking up thread without {@link Thread#interrupt() interrupting} threads. * * <p>This class is used in the Flink Kafka Consumer to hand over data and exceptions between * the thread that runs the KafkaConsumer class and the main thread. * * <p>The Handover has the notion of "waking up" the producer thread with a {@link WakeupException} * rather than a thread interrupt. * * <p>The Handover can also be "closed", signalling from one thread to the other that it * the thread has terminated. */ Handover 是一种实用程序,用于将数据(记录的缓冲区)和异常从<i>生产者</i>线程移交给<i>消费者</i>线程。 它的行为实际上像一个“阻塞队列”,围绕异常报告,关闭和唤醒线程而没有{@link Thread#interrupt()中断}线程。 <p> Flink Kafka Consumer中使用该类在运行KafkaConsumer类的线程与主线程之间移交数据和异常。 <p>切换的概念是使用{@link WakeupException}而不是线程中断来“唤醒”生产者线程。 <p>还可以“关闭”切换,从一个线程向另一线程发信号,表明该线程已终止。
看下对应代码: 两个同步方法,生产和消费数据,使用全局变量 next 中转,使用 同步代码块 保证数据的一致性
// 同步对象 private final Object lock = new Object(); // 全局变量,数据交换用 private ConsumerRecords<byte[], byte[]> next; // 消费线程 public ConsumerRecords<byte[], byte[]> pollNext() throws Exception { // 进入同步方法(加锁) synchronized (lock) { // 如果 next 是 null 的,调用 wait 是消费线程 等待(释放锁,等待生产线程唤醒) while (next == null && error == null) { lock.wait(); } // 将 next 的值赋给 局部变量 n ConsumerRecords<byte[], byte[]> n = next; // 如果 n 不为 null if (n != null) { // 将 next 设为 null next = null; // 唤醒 生产线程 lock.notifyAll(); // 返回 n 到 KafkaFetcher return n; } else { ExceptionUtils.rethrowException(error, error.getMessage()); // this statement cannot be reached since the above method always throws an exception // this is only here to silence the compiler and any warnings return ConsumerRecords.empty(); } } } // 生产线程 public void produce(final ConsumerRecords<byte[], byte[]> element) throws InterruptedException, WakeupException, ClosedException { // 进入同步代码块(加锁) synchronized (lock) { // 如果 全局变量 next 不为空,调用 wait 使线程进入等待 (释放锁,等待消费线程唤醒) while (next != null && !wakeupProducer) { lock.wait(); } wakeupProducer = false; // if there is still an element, we must have been woken up // 到这来不等于 null 就说明多线程异常了,主动抛出异常 if (next != null) { throw new WakeupException(); } // if there is no error, then this is open and can accept this element else if (error == null) { // next 是 null 的,把从 kafka 消费出来的数据,放到全局变量 next 中 next = element; // 调用 notifyAll 方法,唤醒 消费线程 lock.notifyAll(); } // an error marks this as closed for the producer else { throw new ClosedException(); } } // 出同步方法,释放锁 }
整个流程如上面的流程图: KafkaFetcher 启动 kafkaConsumerThread 线程,KafkaConsumerThread (循环)从 kafka 消费到数据后,使用 Handover 的同步方法,转移数据,KafkaFetcher (循环)同样调用 Handover 的同步方法 获取 KafkaConsumerThread 消费出来的数据
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文

【源码】FlinkKafkaConsumer 消费 kafka 流程
标签:vat restore 共享 join enc 没有 extends over ISE
原文地址:https://www.cnblogs.com/Springmoon-venn/p/13614670.html