标签:else play 研究 计算机科学 answering 假设 搜索引擎 根据 eval
我们在处理很多数据分析任务时,不可避免地涉及到与文本内容相关的知识,这是属于文本挖掘(text mining)的内容,显然是NLP技术的范畴,基于这样的考虑我们先来对自然语言处理有一个基本的认识。
如果一台计算机能够欺骗人类,让人相信它是人类,那么该计算机就应当被认为是智能的。(阿兰.图灵)
机器能像我们人类一样理解文本吗?这是大家对人工智能最初的幻想。如今,它已成为人工智能的核心领域——自然语言处理(简称:NLP)。自然语言处理是一门融语言学、计算机科学、人工智能于一体的科学,人们把自然语言处理认为是人工智能的皇冠,它解决的是“让机器可以理解自然语言”——这一到目前为止都还只是人类独有的特权,因此,自然语言理解(NLU)被誉为人工智能皇冠上的明珠。
自然语言处理涉及到众多的技术,它包括但不限于以下几个领域:
以上简单列举了几个NLP相关的技术,接下来,我们希望能够在短时间内,对于NLP有一个基本的了解和简单的实践,我会带领大家写一个问答系统,也就是智能聊天机器人。
聊天机器人是我们日常生活中非常常见的一个人工智能的应用,从这一章开始,我们将通过技术的学习,一步一步开发出一款自己的聊天机器人。其实,早在1965年,Joseph Weizenbaum 在ACM上发表了题为《ELIZA,一个研究人机自然语言交流的计算机程序》的文章。文章描述了这个叫作Eliza的程序如何使人与计算机在一定程度上进行自然语言对话成为可能。Eliza通过关键词匹配规则对输入进行分解,而后根据分解规则所对应的重组规则来生成回复。从那之后,聊天机器人经历了飞速的发展,像微软小冰,苹果siri,小爱同学,天魔精灵等等都是现代聊天机器人的具体应用。
我们一般把聊天机器人分为三类:
对于聊天机器人的归类,我们从字面意思就能看的出来。任务型机器人就是能够在某个领域或者某个特定的场景下来帮助我们完成某些人物,比如小爱同学可以操作家里面的空调,siri可以帮助我们上闹钟等等。知识型机器人就是能够帮助我们处理某个特定领域的知识,比如天猫的自动客服,Sophia能够回答各种问题。聊天机器人就是能够和我们随机聊天的机器人。在我印象中,iphone4s刚诞生的时候,siri就上线了这个功能,曾经无数痴汉都肆虐式地调戏过siri老阿姨Susan Bennett,我们一起来看一下,阿姨年轻时那美丽的容颜。

不过当对siri原声进行采集的时候是这样的

感谢Susan的付出,才有当时的siri和我们寝室内的欢乐(我我我,一不小心暴露了年龄)
目前搭建聊天机器人主要要四种方法:
基于模版匹配的方法其核心就是要定义一条一条的规则,不需要AI技术就可以实现,上面提到的最早的聊天机器人Eliza就是其中的经典案例。这个过程虽然简单,但是需要设计大量的规则,而且要确保规则之间没有冲突(很难),可扩展性差、重复工作很多,很难处理语句的多样化表达等等。
基于检索模型的方法可以有效避免上述的缺点,首先仍是获取输入的文本信息,然后进入检索模型阶段,最后输出回答的结果。这一章,我们主要基于检索模型来构建聊天机器人。
后面的两种意图识别和端到端的方法需要随着NLP相关知识的学习深入才能有更多的实践。
基于检索模型的方法做聊天机器人,主要分为以下几步:中文分词,分本的表示,相似度计算,返回结果这四个步骤。分词就是把词分开,在英文中,I love you,这三个词组成的一句话原本就是用空格分开的,而中文里面的一句话,比如“我爱北京天安门”,应该怎么样用空格分开呢?
为了能够 让程序来帮我们自动完成这个工作,Python语言中提供了多个分词库,比如jieba,SnowNLP,thulac,pynlpir,nltk,pyltp等等,其中最具有代表性的还是百度的jieba分词,github地址是https://github.com/fxsjy/jieba,有兴趣的同学可以深入了解以下。中文分词的意思就是有人根据经验把很多词梳理了出来,然后对一个句子进行检索,知道了哪些字能够组成一个词,使用它之后,就会自动的帮助我们把句子拆分成不同的词。
jieba分词示例代码如下所示
import jieba
text = ‘我爱北京天安门‘
result = jieba.cut(text) # 分词的结果是一个生成器对象
for i in result:
print(i)
jieba分词库提供了三种分词模式,分别是精准模式,全模式和搜索引擎模式。
下面我们通过一个实例来看一下他们的效果分别是怎么样的,代码如下:
import jieba
text = ‘今天天气很热,我出去转了一圈出了一身汗,还是待在家里吹空调吧‘
result1 = jieba.cut(text, cut_all=False) # 精准模式
result2 = jieba.cut(text, cut_all=True) # 全模式
result3 = jieba.cut_for_search(text) # 搜索引擎模式
print(list(result1))
print(list(result2))
print(list(result3))
从结果上,我们看到在文本分析场景下,使用精准模式是比较适合的,其他两种模式对于词的切分上都太过于细致了。
在自然语言处理中,文本表示非常重要,只有把文本表示成数字的样子,我们才能够进一步进行处理。这种用数字代替文本的表示方法就是词向量。顾名思义,它就是用一个向量的形式来表示一个词。
假想我现在有一个由一些单词组成的文本的词典,词典的内容是:我 爱 北京 天安门,现在有三个词,分别是:我,北京和爱,现在我们要通过向量的方式根据词典来表达出这三个词,表示方法如下图所示:
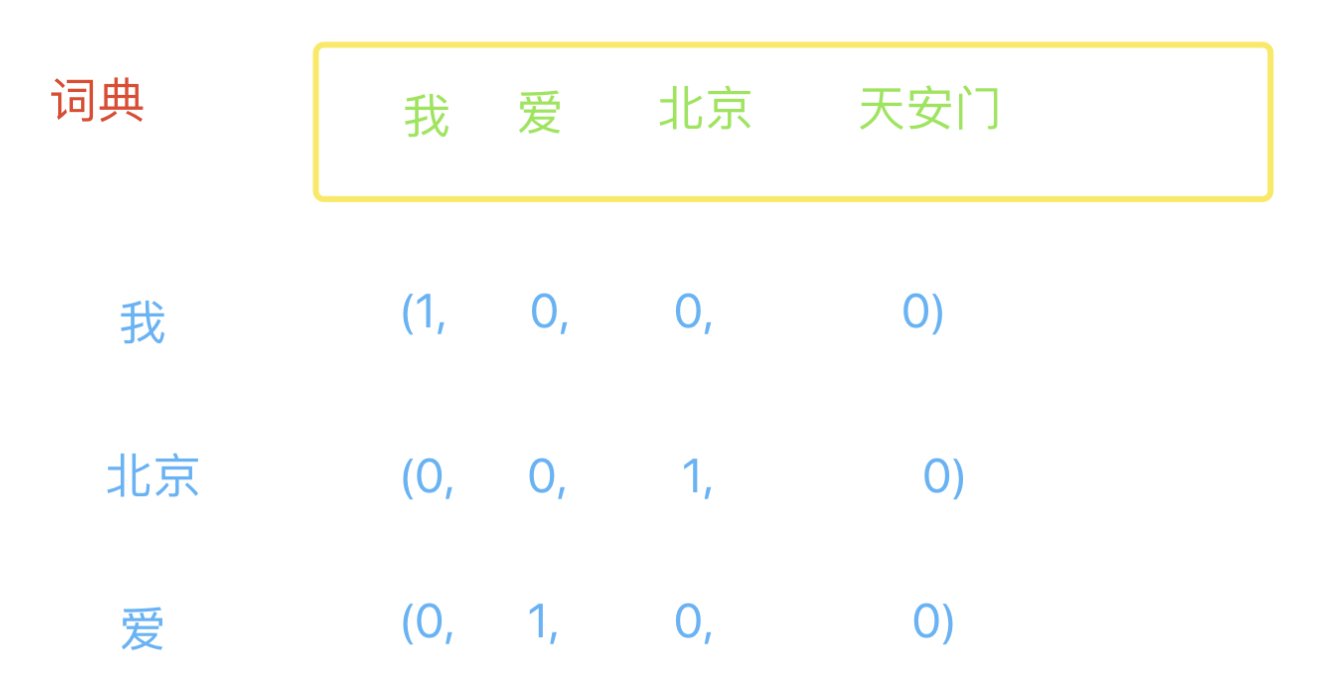
使用这种方式,假如词典,有10亿个词,每一个词的表示都是一个10亿维的数组,其中一维是1,其他全是0。显然,是用这种方式会把一个词表示的特别复杂,实际应用场景肯定不是这样的,我先使用这种方式来便于理解。
现在有一个词典和两个词,基于刚才介绍的词向量表示方法写一个程序来表示这两个词。
text_list = [‘我‘, ‘爱‘, ‘北京‘, ‘天安门‘]
w1 = ‘我‘
w2 = ‘天安门‘
def get_vector(word):
vector = []
for i in text_list:
if word == i:
vector.append(1)
else:
vector.append(0)
return vector
print(get_vector(w1))
print(get_vector(w2))
表示句子与词向量的表示方式类似,只需要我们判断在词向量中是否出现了这个句子的每一个词,出现标记为1,没有出现标记为0。表示句子的程序代码如下:
import jieba
text_list = [‘我‘, ‘爱‘, ‘北京‘, ‘天安门‘]
w1 = ‘我爱你‘
w2 = ‘我在天安门‘
w3 = ‘我的家在北京‘
def get_vector(word):
word_list = list(jieba.cut(word))
print(word_list)
vector = []
for i in text_list:
if i in word_list:
vector.append(1)
else:
vector.append(0)
return vector
print(get_vector(w1)) # 其中w1会受分词结果的影响非常严重,此处做简要说明
print(get_vector(w2))
print(get_vector(w3))
词向量的表示Python给我们提供了一个库gensim,它的使用方式如下代码所示:
import jieba
from gensim.models import word2vec
# 假设有文件 a.txt ,文件内容为:我爱北京天安门
f1 = open(‘a.txt‘)
# 用来存储分词之后的结果
f2 = open(‘b.txt‘, ‘a‘)
# 假设文件内有多行文本
lines = f1.readlines()
for line in lines:
# 替换tab,换行,空格
line.replace(‘/t‘, ‘‘).replace(‘/n‘, ‘‘).replace(‘ ‘, ‘‘)
segment = jieba.cut(line)
# 以空格拼接并写入
f2.write(‘ ‘.join(segment))
f1.close()
f2.close()
# 加载语料
sentences = word2vec.Text8Corpus(‘b.txt‘)
# 训练模型
model = word2vec.Word2Vec(sentences, min_count=1) # 语料库太少,必须设置min_count参数为1
# 保存模型
model.save(‘word2vec.model‘)
# 表示词向量
print(model.wv[‘我‘])
print(model.wv[‘天安门‘])
print(model.wv[‘我‘, ‘天安门‘])
# print(model.wv[‘上海‘]) # 词向量必须在语料库中存在才可以表示,不存在会报错
文本相似度,主要是计算不同文本之间的距离,他计算方式就像是计算直角三角形的斜边的长度,那么现在我们计算a和b两点之间的距离的计算方法就是:

这种距离的计算方式叫做欧式距离,把它扩展到n维空间下的计算方式就是:

曼哈顿距离是与欧式距离比较相近的距离计算,也叫做曼哈顿街区距离,他的计算距离很简单,就是计算两点在轴上的相对距离总和,如下图蓝色虚线所示:
曼哈顿距离公式:d(a,b)= |x1 - x2| + |y1 - y2|
在n维空间下:d(a,b)= |x1 - x2|+|y1 - y2|+ ... |xn - yn|
在早期的计算机图形学中,使用曼哈顿距离可以大大提高运算速度,而且误差很小,现在常把曼哈顿距离应用于与图形相关的复杂的计算中以此来提高效率,这里我们做一个简单的引导就不再一一展开。
余弦相似度是计算文本相似度应用的非常多的一个计算公式,它的本质是计算两点所构成向量夹角的余弦值,如下图所示:
从图中我们可以看:θ = θ1 - θ2,θ的值越小,则余弦值越接近于1,进而说明两个点之间越相似。余弦相似度的计算也有其特定的公式,他的推导过程如下所示:

公式的推导过程比较简单,有数学恐惧症的同学可以先跳过这一部分。
计算文本相似度只需要一行代码,但是有一个小细节,我们计算的词必须要出现在语料库中,由于文本数据少之又少,我们计算的结果会和实际有所偏差,但这并不影响我们的理解,示例代码如下:
# 1 获取两个文本之间的相似度
sim1 = model.wv.similarity(‘我‘, ‘天安门‘)
# sim2 = model.wv.similarity(‘我们‘, ‘天安门‘) # 报错:"word ‘我们‘ not in vocabulary"
print(sim1)
# 2 找到与给定文本最想的文本,并排序
sim_text = model.wv.most_similar(‘我‘)
print(sim_text)
# 3 比较两个词条的相似性
sim3 = model.wv.n_similarity([‘我‘, ‘天安门‘], [‘爱‘, ‘北京‘])
print(sim3)
首先我这里会有以压缩文件,里面包含两个txt文件,其中fenci.txt里边存储了一段文字,你需要把这些文字用分词库,把他们分成不同的词语,作为我们的语料库。
chapter3_1.zip
content_file.txt文件中存储了一些标题和回帖的内容,这些内容是来源于网上的一些帖子内容。我们把title看做是相关的聊天主题,而reply看做是回答的答案。
你需要根据这些语料来制作一个能够自动回复用户的聊天机器人,具体代码如下:
import json
import random
import jieba
from gensim.models import word2vec
"""
1、用户输入一段文本
2、对用户输入的文本进行分词
3、把用户输入的结果与content_file.txt文件中的title字段,一一的进行相似度运算
4、获取到最大的相似度。
5、由于reply中的内容是一个列表,所以随机产生一个答案进行回复。
"""
f1 = open(‘fenci.txt‘)
f2 = open(‘result.txt‘, ‘a‘)
lines = f1.readlines()
for line in lines:
line.replace(‘\t‘, ‘‘).replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘)
segment = jieba.cut(line)
f2.write(‘ ‘.join(segment))
f1.close()
f2.close()
sentences = word2vec.Text8Corpus(‘result.txt‘)
model = word2vec.Word2Vec(sentences, min_count=1)
model.save(‘chat-bot.model‘)
word2vec.Word2Vec.load(‘chat-bot.model‘)
# 3 比较两个词条的相似性
sim3 = model.wv.n_similarity([‘我们‘, ‘最近‘], [‘因为‘, ‘不好‘])
print(sim3)
while True:
text = input("请输入>>:").strip()
if text in [‘拜拜‘, 88, 8, ‘bye‘, ‘再见‘]:
print("有缘再见")
break
# 1 分词
words = jieba.cut(text)
user_word_list = []
for word in words:
user_word_list.append(word)
# 2 加载回复文件
content_file = open(‘content_file.txt‘)
json_content_file = json.load(content_file)
max_sim_result = 0
max_sim_response = []
max_sim_title = ‘‘
for line in json_content_file:
content_cut_word = jieba.cut(line[‘title‘])
content_list = []
for w in content_cut_word:
content_list.append(w)
try:
sim_result_value = model.wv.n_similarity(user_word_list, content_list)
except:
continue
# 3 检查最大相似度的匹配
if sim_result_value > max_sim_result:
max_sim_result = sim_result_value
max_sim_response = line[‘reply‘]
max_sim_title = line[‘title‘]
print(max_sim_result)
print(max_sim_title)
if max_sim_response:
print(max_sim_response[random.randint(0, len(max_sim_response) - 1)])
else:
print(‘对不起,请说人话‘)
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan。
标签:else play 研究 计算机科学 answering 假设 搜索引擎 根据 eval
原文地址:https://www.cnblogs.com/mayite/p/13624464.html