标签:yun 结合 质量 try 统计 exce str one 加载
RF的结果报告可以方便我们查看每一条用例集、用例的执行结果统计,但是有的项目涉及到一些数据的比对,希望能够直观到看到数据,原生的测试报告就无法满足这个需求了。
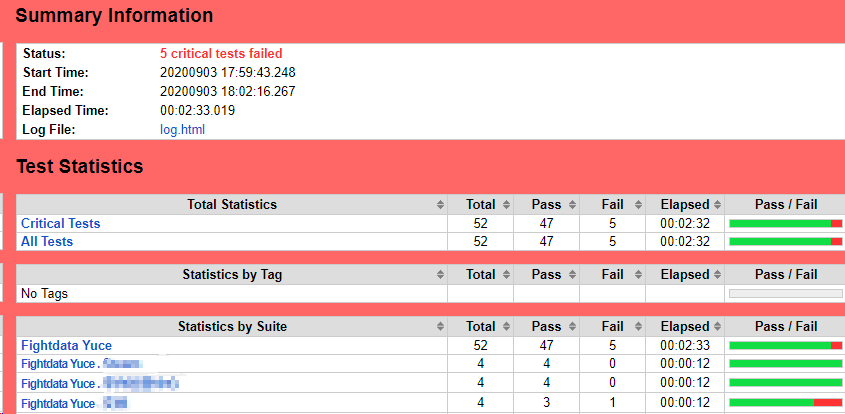

测试用例相关的信息和运行结果,我们可以通过解析RF的output.xml文件来进行获取

import xml.dom.minidom
import xml.etree.ElementTree
# 打开xml文档
dom = xml.dom.minidom.parse(‘E:\\robot\\fightdata_yuce\\results\\output.xml‘)
root2 = xml.etree.ElementTree.parse(‘E:\\robot\\fightdata_yuce\\results\\output.xml‘)
# 得到文档元素对象
root = dom.documentElement
total = root.getElementsByTagName(‘total‘);
total_len = len(total)
# total的stat节点个数
total2 = root2.getiterator("total")
total_stat_num = len(total2[total_len-1].getchildren())
statlist = root.getElementsByTagName(‘stat‘);
def get_total_statistics():
list = []
for i in range(0,total_stat_num):
d = dict()
d[‘fail‘] = int(statlist[i].getAttribute("fail"))#失败用例数
d[‘pass‘] = int(statlist[i].getAttribute("pass"))#成功用例数
d[‘total‘] = d[‘fail‘]+d[‘pass‘]#用例总数
d[‘percent‘] = (‘{:.2%}‘.format(d[‘pass‘] / d[‘total‘]))#用例百分比
list.append(d)
return list

import xml.dom.minidom
import xml.etree.ElementTree
# 打开xml文档
dom = xml.dom.minidom.parse(‘E:\\robot\\xxx\\results\\output.xml‘)
root2 = xml.etree.ElementTree.parse(‘E:\\robot\\xxx\\results\\output.xml‘)
tree3=root2.getroot()
# 获取suite下的子节点
def getcase():
casedict = {}
testlist2 = []
for elem in tree3.iterfind(‘suite/suite‘):
a = elem.attrib
suitedict = {}
testlist2.append(suitedict) #每一个用例集合存入列表
testlist = []
suitename = a[‘name‘]#获取用例结合的名字
for test in elem.iter(tag=‘test‘):
b=test.attrib
for data in test.iterfind(‘status‘):
casename = b[‘name‘] #获取用例的名字
c=data.attrib
status=c[‘status‘] #获取每条用例的执行结果
casedict[‘casename‘] = casename #用例名字存入字典
casedict[‘status‘] = status #用例执行结果存入字典
testlist.append(casedict) #每一条用例的名字和执行结果作为字典存入列表
casedict = {}
suitedict[‘suitename‘]=suitename
suitedict[‘test‘]=testlist
return testlist2 #最终返回的就是[{‘suitename‘: ‘xxx‘, ‘test‘: [{‘casename‘: ‘01 xxx‘, ‘status‘: ‘PASS‘},
#{‘casename‘: ‘02 xxx‘, ‘status‘: ‘PASS‘}
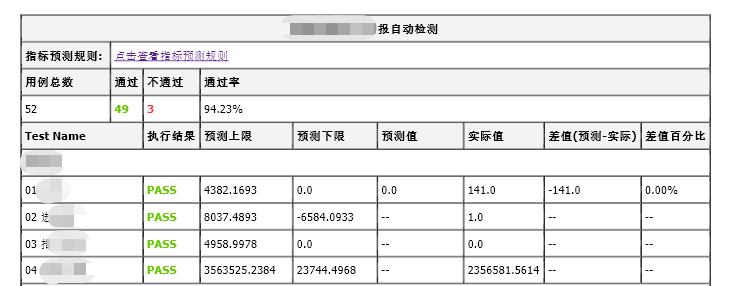
通过前面获取的获取,填充到jinja2的模板中,会生成另外一个有数据的html文件
from jinja2 import Environment, FileSystemLoader
import parsexml
def generate_html(data):
env = Environment(loader=FileSystemLoader(‘./‘)) # 加载模板
template = env.get_template(‘report.html‘)
# template.stream(body).dump(‘result.html‘, ‘utf-8‘)
data=parsexml.get_total_statistics()#获取解析的xml的用例统计数据
data2=parsexml.getcase()#获取测试用例信息和执行结果
with open("result.html", ‘w‘,encoding=‘utf-8‘) as fout:
html_content = template.render(data=data,data2=data2)
fout.write(html_content) # 写入模板 生成html
jinja2模板的原理就是,通过先创建一个html的模板文件,然后将数据渲染到模板文件,生成一个渲染后的html文件,该文件会显示填充的数据
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>战娃利润中心指标自动化测试报告</title>
</head>
<body>
<div style="width:100%;float:left">
<table cellspacing="0" cellpadding="4" border="1" align="left">
<thead>
<tr bgcolor="#F3F3F3">
<td style="text-align:center" colspan="9"><b>战娃利润中心日报自动检测</b></td>
</tr>
<!-- <tr>
<td bgcolor="#F3F3F3" style="width:80px"><b>详细报告:</b></td>
<td colspan="8">
<a href="${rooturl}${build.url}robot/report/report.html">点击查看报告详情</a>
</td>
</tr>-->
<tr>
<td bgcolor="#F3F3F3" style="width:100px"><b>指标预测规则:</b></td>
<td colspan="8">
<a href="https://docs.qq.com/sheet/DT1ZBZHdGdXJkVWFL">点击查看指标预测规则</a>
</td>
</tr>
<!--这里定义的是用例的统计信息-->
<tr bgcolor="#F3F3F3">
<td><b>用例总数</b></td>
<td><b>通过</b></td>
<td style="width:60px"><b>不通过</b></td>
<td colspan="6"><b>通过率</b></td>
</tr>
<!--通过2.3的渲染获取的数据,在这里进行取值填充-->
<tr>
<td>{{data[‘total‘]}}</td>
<td><b><span style="color:#66CC00">{{data[‘pass‘]}}</span></b></td>
<td><b><span style="color:#FF3333">{{data[‘fail‘]}}</span></b></td>
<td colspan="6">{{data[‘percent‘]}}</td>
</tr>
<!-- 这里定义的是用例的表头信息-->
<tr bgcolor="#F3F3F3">
<td colspan="2"><b>Test Name</b></td>
<td><b>执行结果</b></td>
<td><b>预测上限</b></td>
<td><b>预测下限</b></td>
<td><b>预测值</b></td>
<td><b>实际值</b></td>
<td><b>差值(预测-实际)</b></td>
<td><b>差值百分比</b></td>
</tr>
</thead>
<tbody>
<!--通过2.3的渲染获取的数据data2,也就是用例信息数据,在这里进行取值填充,由于涉及多个suite,
每个suite下有多条case,这里通过两层循环取每条case的相关信息 -->
{% for data in data2 %}
<tr>
<td colspan="9"><b>{{data[‘suitename‘]}}</b></td>
</tr>
<tr>
{% for c2 in data[‘test‘] %}
<td colspan="2">{{c2[‘casename‘]}}</td>
{% if c2[‘status‘]==‘PASS‘ %}
<td><b><span style="color:#66CC00">{{c2[‘status‘]}}</span></b></td>
{% else %}
<td><b><span style="color:#FF3333" >{{c2[‘status‘]}}</span></b></td>
{% endif %}
<td>{{c2[‘max‘]}}</td>
<td>{{c2[‘min‘]}}</td>
{% if c2[‘casename‘]==‘01 GMV‘ %}
<td>{{c2[‘yhat‘]}}</td>
{% else %}
<td>--</td>
{% endif %}
<td>{{c2[‘real‘]}}</td>
{% if c2[‘casename‘]==‘01 GMV‘ %}
<td>{{c2[‘reduce‘]}}</td>
{% else %}
<td>--</td>
{% endif %}
{% if c2[‘casename‘]==‘01 GMV‘ %}
<td>{{c2[‘percent‘]}}</td>
{% else %}
<td>--</td>
{% endif %}
</tr>
{% endfor %}
{% endfor %}
</tbody>
</table>
</body>
</html>
将上述渲染生成的有数据的html文件作为测试报告进行邮件发送
# !/usr/bin/python
# -*- coding: utf-8 -*-
import smtplib, time, os
from email.mime.text import MIMEText
from email.header import Header
import generate
def send_mail_html(file):
sender = ‘ccc@fulu.com‘ #发件人
mail_to =[‘aa@fulu.com‘,‘bb@fulu.com] #收件人
t = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) #获取当前时间
subject = ‘战娃利润中心指标自动化测试报告‘ + t #邮件主题
smtpserver = ‘smtp.qiye.aliyun.com‘ #发送服务器地址
username = ‘cc@fulu.com‘ #用户名
password = ‘123456‘ #密码
f = open(file, ‘rb‘)
mail_body = f.read()
f.close()
msg = MIMEText(mail_body, _subtype=‘html‘, _charset=‘utf-8‘)
msg[‘Subject‘] = Header(subject, ‘utf-8‘)
msg[‘From‘] = sender
msg[‘To‘] = ";".join(mail_to)
try:
smtp = smtplib.SMTP()
smtp.connect(smtpserver)
smtp.login(username, password)
smtp.sendmail(sender, mail_to, msg.as_string())
except:
print("邮件发送失败!")
else:
print("邮件发送成功!")
finally:
smtp.quit()
def result():
file = ‘result.html‘ #渲染后的html报告文件
result = {}
generate.generate_html(result)
send_mail_html(file)
邮件展示结果
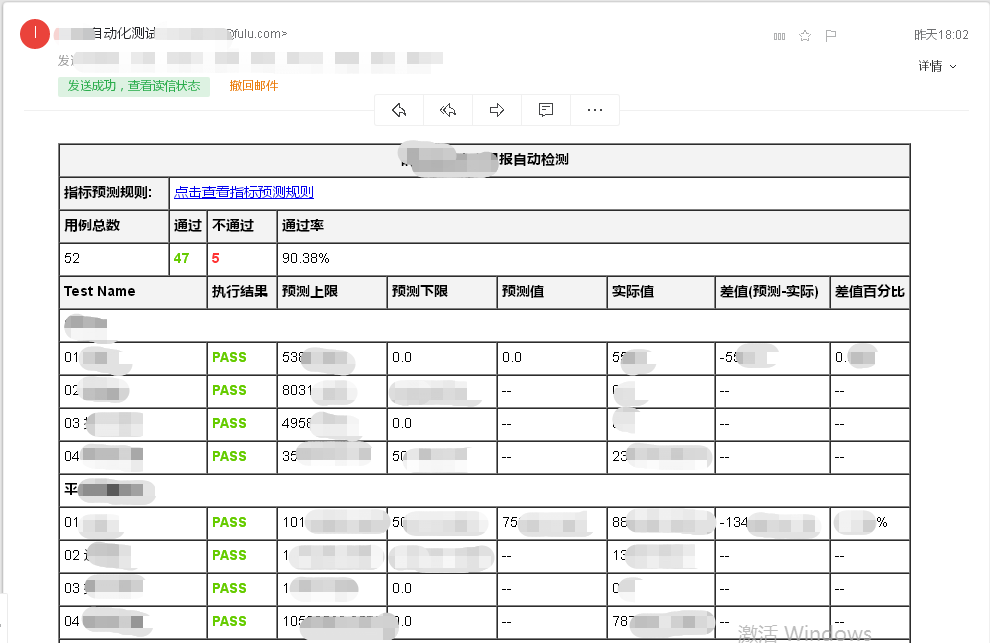
在当初接到该需求的时候,尝试在网上找相关的实现方案,其中jenkins自带的RF的插件可以实现报告的解析和邮件发送,第一版我们就是采用该报告模板进行推送
第一版报告,参考该博文https://blog.csdn.net/qq_38317509/article/details/81316940
在需要展示每条用例的具体数据信息的时候,也是尝试对该模板文件进行修改取值,并查看了插件的源码实现,发现无法进行这种个性化的数据的取值,源码只是返回了用例信息、执行状态和执行时间,以及失败时候的msg,那能不能通过msg这个关键字来做文章呢,也就是把需要查看的数据通过msg打印显示出来,然而发现只有case失败的时候才显示用例,成功的时候不显示,而且数据以log显示,查看不是那么清晰
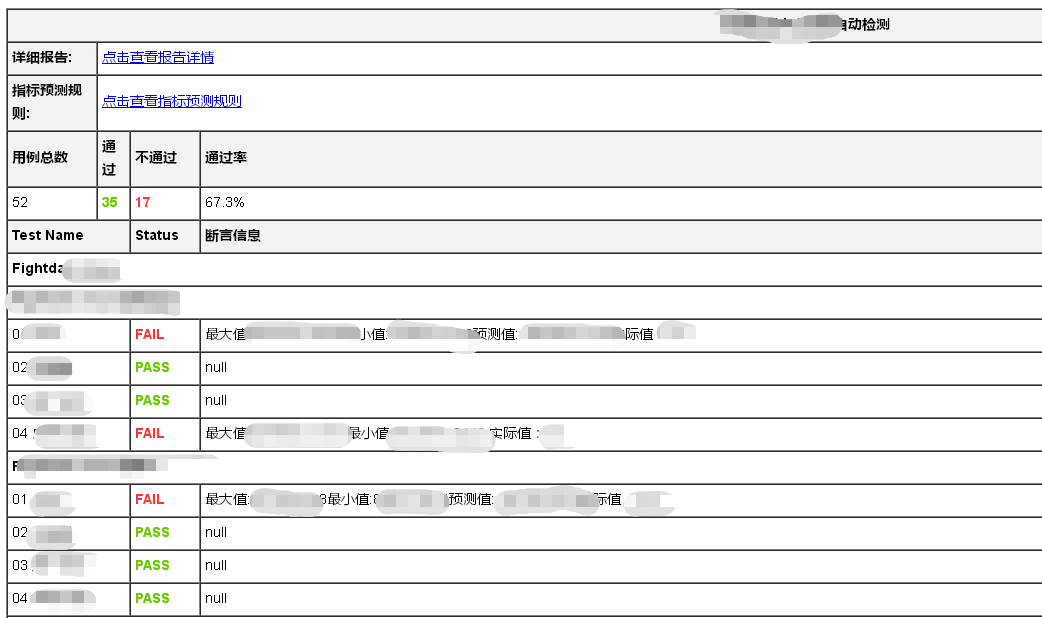
基于上述情况,发现了jinja2这个包,于是就放弃了jenkins的插件,通过自定义报告模板,然后填充数据的方式,这样灵活度就大大提高了,后续的个性化需求也方便去定制开发了,目前我们还是依赖jenkins进行测试任务的触发,我们希望将RF这块也容器化,这块你们有相关的实践吗,欢迎指导~
jinja2快速实现自定义的robotframework的测试报告
标签:yun 结合 质量 try 统计 exce str one 加载
原文地址:https://www.cnblogs.com/fulu/p/13625585.html