标签:style blog http io color ar sp 数据 on
本文主要通过一个典型的例子介绍什么是机器学习以及机器学习里常见的一些概念。
一个顾客想申请招商银行信用卡,招商银行让这个顾客填写一些基本资料,假设整个申请表一共只有五项(真实的申请表会被这五个选项要多得多)。
| 性别 | 女 |
| 年龄 | 23 |
| 工作年限 | 0.5 |
| 年收入 | 10万 |
| 负债 | 1万 |
假如你是招商银行信用卡负责人,你会给她发放信用卡吗?实际上你想知道的是给她发放信用卡对银行有好处还是坏处。你可能有点摸不着头脑,不知道到底是给不给这位顾客发送信用卡,正在焦头烂额之时,领导又来电话了:“张某某上上个月刷了一万块,还款日都过去半个月了,怎么还不见他还钱?当初是怎么通过他的审核给他发送信用卡的?blabla。。。”这时候你多么希望手上掌握一个非常完美的公式,只要用这个公式一算,得到一个分数,就知道是不是应该给张某某,李某某。。。发放信用卡啊,而且这个完美的公式的确很完美,不会犯错误。无奈你根本找不到这个公式,于是你想凭借自己的聪明才智攒一个公式出来,所以你想整理一下已经拥有行用卡的顾客的消费数据,希望根据这些数据发明一个公式,而且这个公式跟那个完美的公式长得越像越好。
从这个例子,我们引出一些基本概念:
输入所有可能取值的集合。上面的例子,输入实际上是一个五维的向量,所以输入空间就是这个向量所有的可能取值。
输出所有可能取值的集合。上面的例子,输出空间就是是和否,或者有好处,有坏处...
输入空间和输出空间可以是同一个空间,也可以是不同的空间,通常输出空间远小于输入空间。
就是例子中的完美公式。
例子中已经拥有信用卡的顾客的消费数据。
例子中发明的公式就是一个假设。
我们期望的是“假设”和“目标函数”长得越像越好,那到底“假设”长什么样呢?
假设1:年收入大于8万就发放信用卡,小于8万就不发。
假设2:女性就发放信用卡,否则不发。
。。。
假设N:。。。
所有上面的那些假设就构成了假设空间,一般假设空间里的假设有无穷多个。
在李航博士的统计学习方法里,假设又可以叫模型,如果模型是一个线性模型,那模型对应的假设空间就是所有线性函数构成的函数集合。
有了模型的假设空间,接下来需要考虑的是采取什么样的准则选择最优的模型。一般都是先定义好风险损失函数,采取最小化损失函数的策略。
算法是指学习模型的具体计算方法,一般如我们常说的梯度下降法,牛顿法,向后传播算法等等。
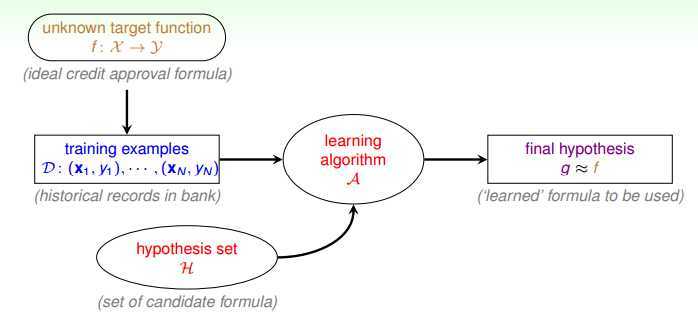
最后借用台湾国立大学林轩田老师的一副图来描述什么是机器学习:Machine learning is using "data" to compute hypothesis "g" that approximates target "f"。
统计学习方法 李航著
机器学习基石 https://class.coursera.org/ntumlone-002
标签:style blog http io color ar sp 数据 on
原文地址:http://www.cnblogs.com/dudi00/p/4088551.html