标签:输出 现在 def 基于 ash 效率 区别 image 超过
不论MapReduce还是RDD,shuffle都是非常重要的一环,也是影响整个程序执行效率的主要环节,但是在这两个编程模型里面shuffle却有很大的异同。
shuffle的目的是对数据进行混洗,将各个节点的同一类数据汇集到某一个节点进行计算,为了就是分布式计算的可扩展性。
可能大家多MR的shuffle比较清楚,相对来说MR的shuffle是比较清晰和粗暴的。shuffle阶段是介于Map和Reduce的一个中间阶段。
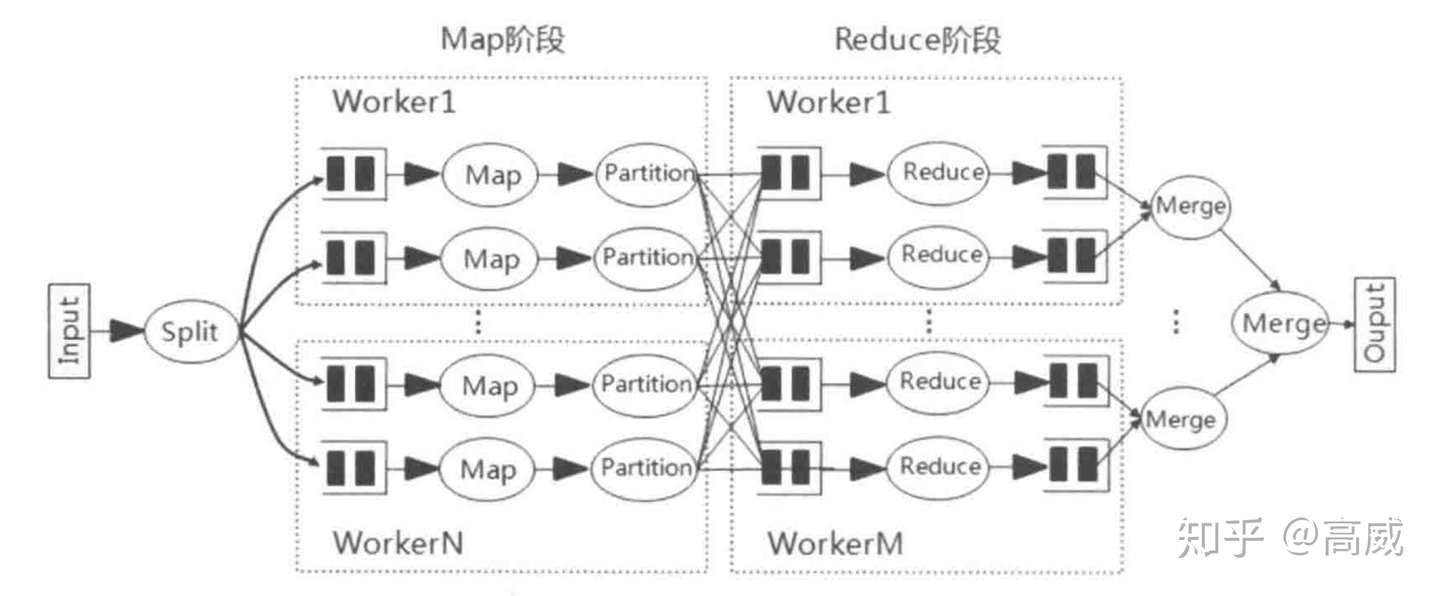
具体详情见:
高威:MapReduce编程模型?zhuanlan.zhihu.com
而Spark的shuffle过程时出现在ShuffleMapTask过程中,和MR的map端shuffle以及reduce端shuffle类似,spark由于是一条链路不落盘的RDD开发模式,所以Spark的shuffle分为shuffle的读操作和shuffle的写操作。
MR的shuffle分为:
但是MR的shuffle有一个很重要的特点:全局排序。
MR的shuffle过程中在Map端会进行一个Sort,也会在Reduce端对Map的结果在进行一次排序。这样子最后就变成了有多个溢出文件(单个溢出文件是有序的,但是整体上是无序的),那么最后在merge成一个输出文件时还需再排序一次,同时,reduce在进行merge的时候同样需要再次排序(因为它从多个map处拉数据)
注意:这个有序是指Key值有序,对于value依旧是无序的,如果想对value进行排序,需要借鉴二次排序的算法。
二次排序的理论是利用MR的全局排序的功能,将value和key值合并,作为一个新的Key值,然后由MR的机制进行Key的排序,这个方法类似于在处理数据倾斜的时候在Key值上加随机数的方法。
这个是排序的一种思想----合并排序。先进行小范围排序,最后再大范围排序。最后的复杂度为O(nlog(n)),比普通排序复杂度O(n的平方)快。
但是问题是,排序是一个很耗资源的一种操作,而且很多的业务场景,是不需要进行排序的。所以MR的全局排序在很多的业务场景中是一个非常耗资源而且无用的操作。
Spark的shuffle(对排序和合并进行了优化):
为了避免不必要的排序,Spark提供了基于Hash的、基于排序和自定义的shuffleManager操作。
1、shuffle的读写操作
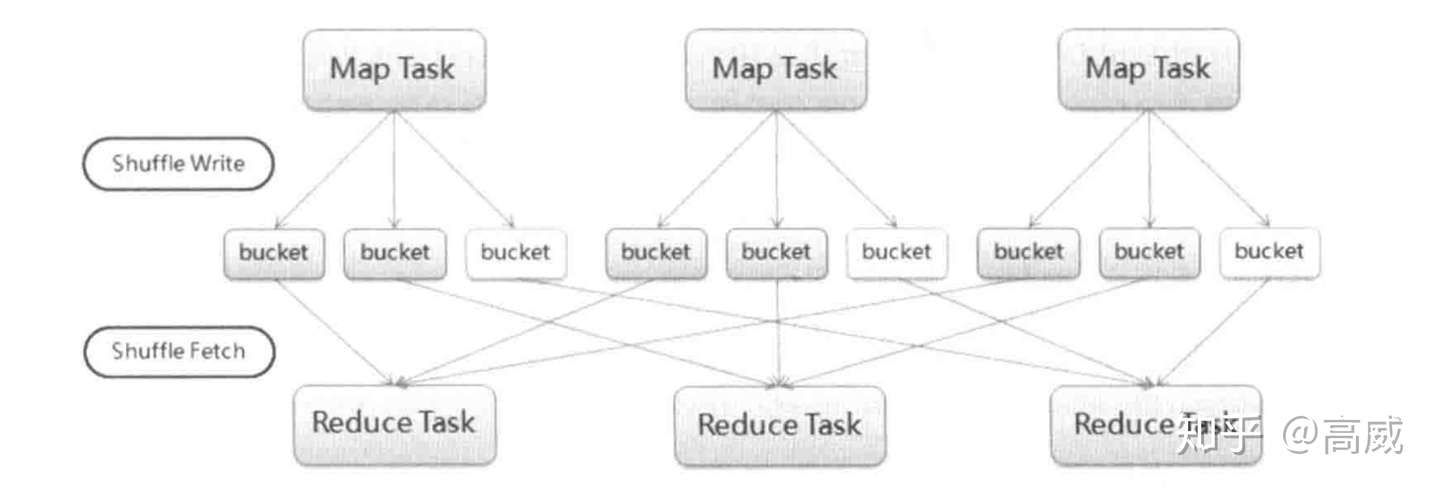
基于Hash的shuffle会出现一个问题:文件个数是M*R个,对于文件系统是一个负担,同时在shuffle的数据量不大的情况下,文件个数过多,随机写入会严重降低I/O的性能。同时如果后续任务很大的情况下,这些小文件所占用的缓存也是一个很大的开销。
后续HashShuffle优化合并的运行机制,避免大量文件产生,把同一个core上的多个Mapper文件输出到同一个文件里面,这样文件个数就变成了R。
在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。
根据不同的shuffle算子(是否combine),可选择不同的数据结构。
如果不需要combine,会选择Array数据结构,直接写到内存,然后溢写到磁盘;
如果需要combine,则选择Map数据结构,一边对Map进行排序聚合,一边写到内存,然后溢写到磁盘,最后在合并聚合。
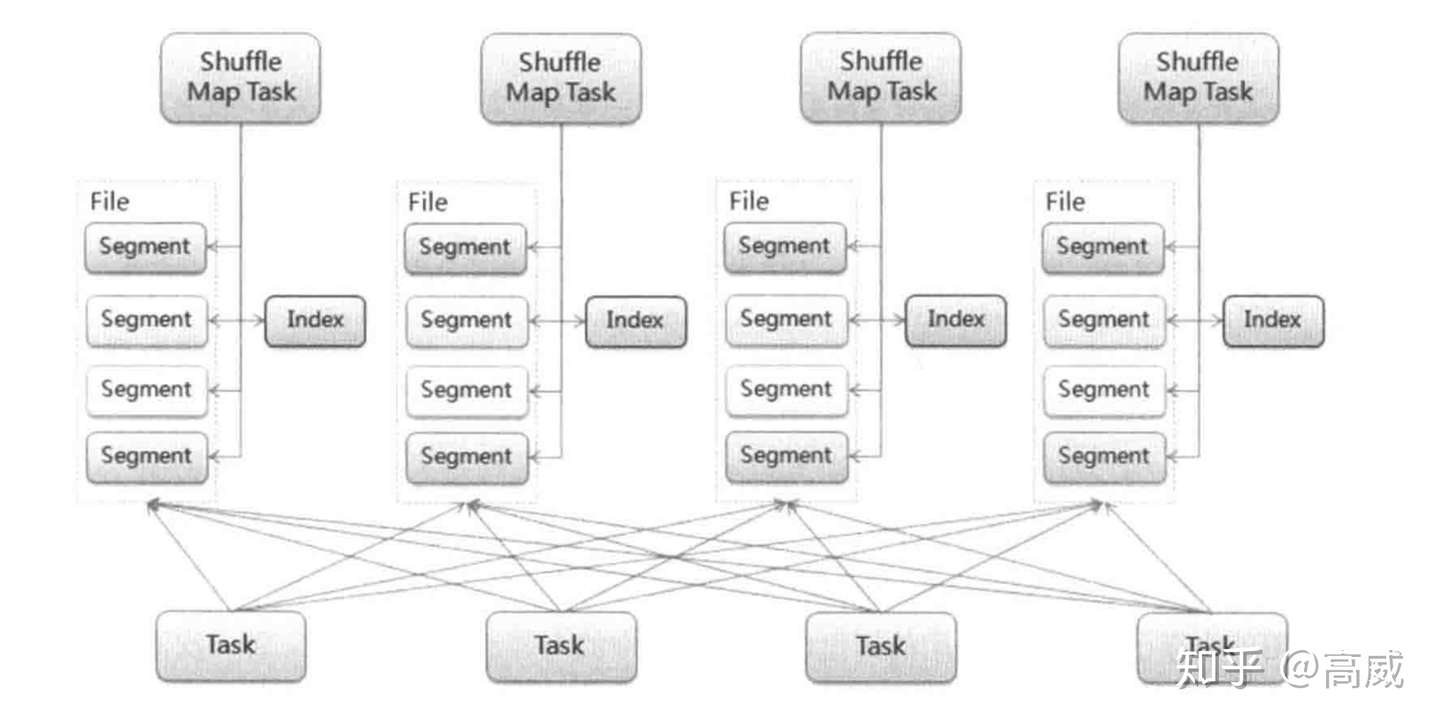
SortShuffle数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可以选用不同的数据结构。如果是有聚合操作的shuffle算子,就是用map的数据结构(边聚合边写入内存),如果是join的算子,就使用array的数据结构(直接写入内存)。接着,每写一条数据进入内存数据结构之后,就会判断是否达到了某个临界值,如果达到了临界值的话,就会尝试的将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序,排序之后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批次1万条数据的形式分批写入磁盘文件,写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
此时task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写,会产生多个临时文件,最后会将之前所有的临时文件都进行合并,最后会合并成为一个大文件。最终只剩下两个文件,一个是合并之后的数据文件,一个是索引文件(标识了下游各个task的数据在文件中的start offset与end offset)。最终再由下游的task根据索引文件读取相应的数据文件。
当非聚合的情况下,同时分区数少于设定的阈值,会启动ByPass 机制,bypass的就是不排序,还是用hash去为key分磁盘文件,分完之后再合并,形成一个索引文件和一个合并后的key hash文件。省掉了排序的性能。
标签:输出 现在 def 基于 ash 效率 区别 image 超过
原文地址:https://www.cnblogs.com/jeasonit/p/13638285.html