标签:width 实例 代码托管 load 排序 info 宕机 des 数据分析
通过一个关键词或一段描述,得到你想要的(相关度高)结果
关系型数据库:性能差、不可靠、结果不准确(相关度很低)
使用mysql数据库时,建立索引会加快查询效率(索引会对字段进行排序)
但若使用模糊查询:select * from emp where ename like ‘%张三%‘;(此时索引失效,会按顺序检索,时间复杂度O(n))
select * from emp where ename like ‘张三%‘;(此时索引生效,但相关度很低,只能搜索到张三xxx的数据,搜不到xx张三xx数据)
1、倒排索引数据结构:
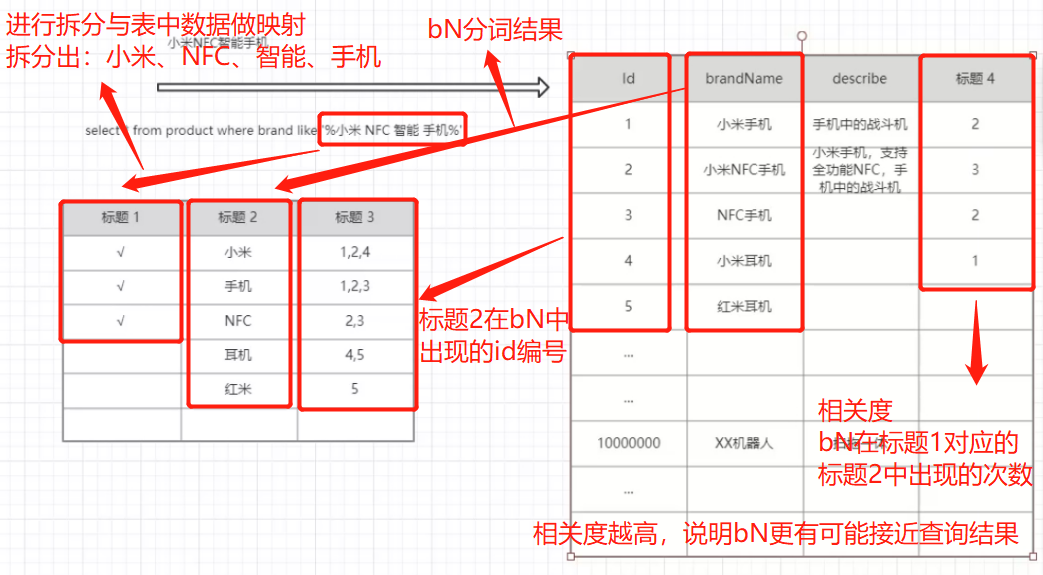
①包含这个关键词的document list(标题3)
②关键词在每个doc中出现的次数TF term frequency(describe)
③关键词在整个索引中出现的次数 IDF inverse doc frequency(标题2中每一个关键词在bN中出现的次数,出现的次数越高,相关度越低)
④关键词在当前doc中出现的次数
⑤每个doc的长度,越长相关度越低
⑥包含这个关键词的所有doc的平均长度
2、Lucene:
jar包,帮我们创建倒排索引,提供了复杂的API
3、如果用Lucene做集群实现搜索,会有哪些问题?
①节点一但宕机,数据丢失,后果不堪设想,可用性差
②自己维护,麻烦(自己创建管理索引),单台节点的承载请求的能力是有限的,需要人工做负载
1、分布式的搜索,存储和数据分析引擎
2、优点:
①面向开发者友好,屏蔽了Lucene的复杂特性,集群自动发现
②自动维护数据在多个节点上的建立
③会帮我做搜索请求的负载均衡
④自动维护冗余副本,保证了部分节点宕机的情况下仍然不会有任何数据丢失
⑤ES基于Lucene提供了很多高级功能:符合查询、聚合分析、基于地理位置
⑥对于大公司,可以构建几百台服务器的大型分布式集群,处理PB级别数据
⑦相对传统数据库,提供了全文检索,同义词处理,相关度排名。聚合分析以及海量数据的近实时处理
3、应用领域:
①百度(全文检索、高亮、搜索推荐)
②各大网站的用户行为日志(用户点击、浏览、收藏、评论)
③BI(商业智能),数据分析:数据挖掘统计
④Github:代码托管平台,几千亿行代码
⑤ELK(Elasticsearch(数据存储)、Logstash(日志采集)、Kibana(可视化))
1、Cluster(集群):每个集群至少包含两个节点
2、Node:集群中的每个节点,一个节点不代表一台服务器
3、Field:一个数据字段与index和type一起,可以定位一个doc
4、Document:ES最小的数据单元 Json格式
{
"id": "1",
"name": "小米",
"price": {
"标准版": 3999,
"尊享版": 4999
}
}
Type:逻辑上的数据分类
Index:一类相同或者类似的doc,比如一个员工索引、商品索引
Doc等价于row type等价于table index等价于db
P:Primary Shard主分片 R:Replica Shard副本分片
1、一个index包含多个Shard,默认5P,默认每个P分配一个R,P的数量在创建索引的时候如果想修改,需要重建索引
2、每个Shard都是一个Lucene实例,有完整的创建索引的处理请求能力
3、ES会自动在nodes上为我们做shard均衡
4、一个doc是不可能同时存在于多个PShard中的,但是可以存在于多个RShard中
5、P和对应的R不能同时存在于同一个节点,所以最低的可用配置是两台节点,互为主备
好处
①如果某一台机器宕机,可以保证其他节点数据的完整性
②横向扩容
标签:width 实例 代码托管 load 排序 info 宕机 des 数据分析
原文地址:https://www.cnblogs.com/lyc-code/p/13646484.html