标签:table 注入 tps action erro editor 版本 copy zip
实验包括:
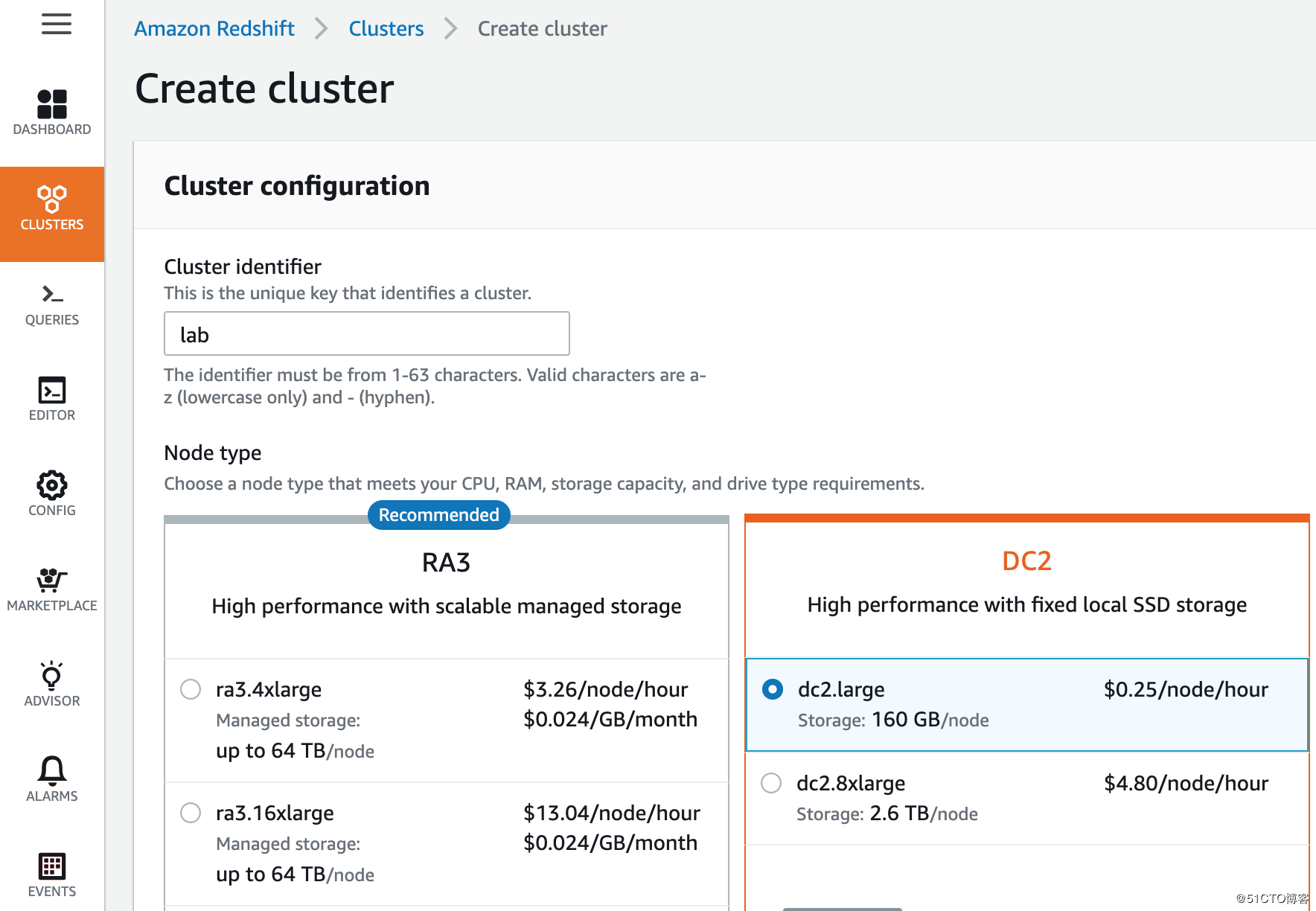
Nodes 为2个
下拉到Database configuration 中:
Database name:lab
Master user name:master
Master user password:Redshift123
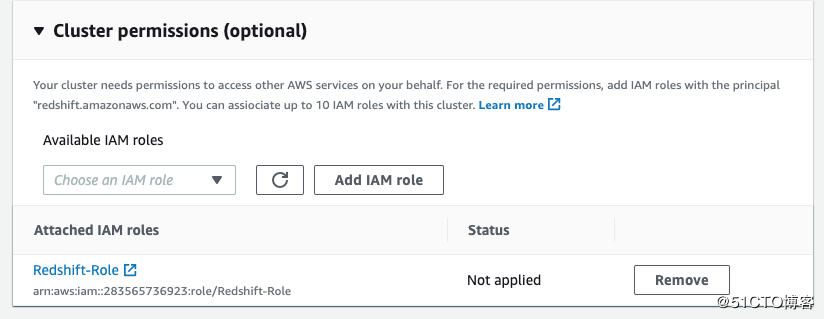
然后创建(或选择)一个具有S3 full access的role。
如果没有创建一个:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "s3:",
"Resource": "",
"Effect": "Allow"
}
]
}在Cluster permission 中选择刚刚创建的role:Redshift-Role
Copy这个role的ARN,我们后面会用得到:arn:aws:iam::303364507332:role/Redshift-Role
其他设置:注意选择的Security Group 放行inbound TCP 5439端口:
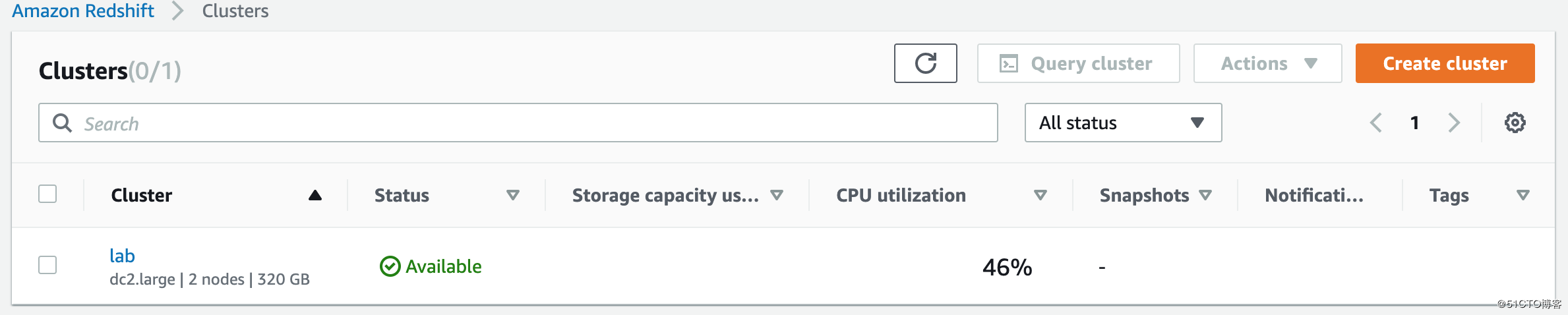
开始创建:
创建完成后的状态:
解释一下Node和Clusters,之前的架构图拖到这里:
XXXX(PS:还是看视频数据仓库那一章节吧)Task2: 链接Amazon Redshift
有两种大类方式连接Redshift集群, 我两种方法都简单介绍一下:
一:使用AWS console 直接Query cluster。
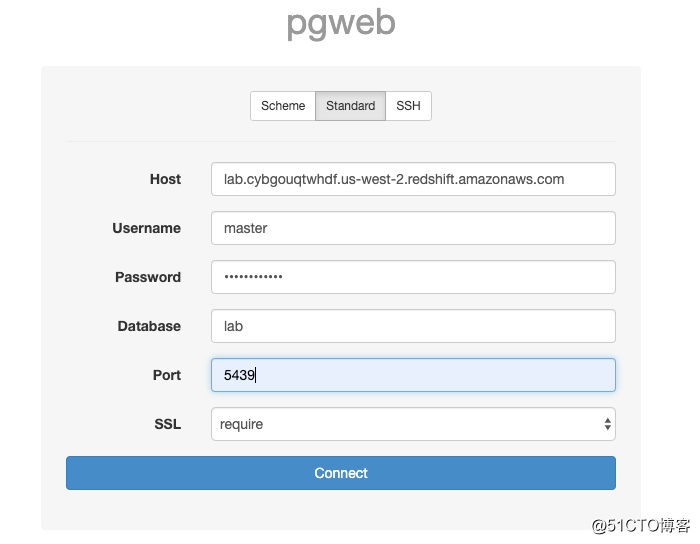
二:使用DB client,比如pgweb去连接,注意端口号是5439。
第一种方法,直接点Redshifit上的,Query cluster 输入相关数据库名称,用户和临时密码就可以登录进去并执行Query语句。
(注意,要用临时密码登录)Task3:加载S3的数据到Amazon Redshift
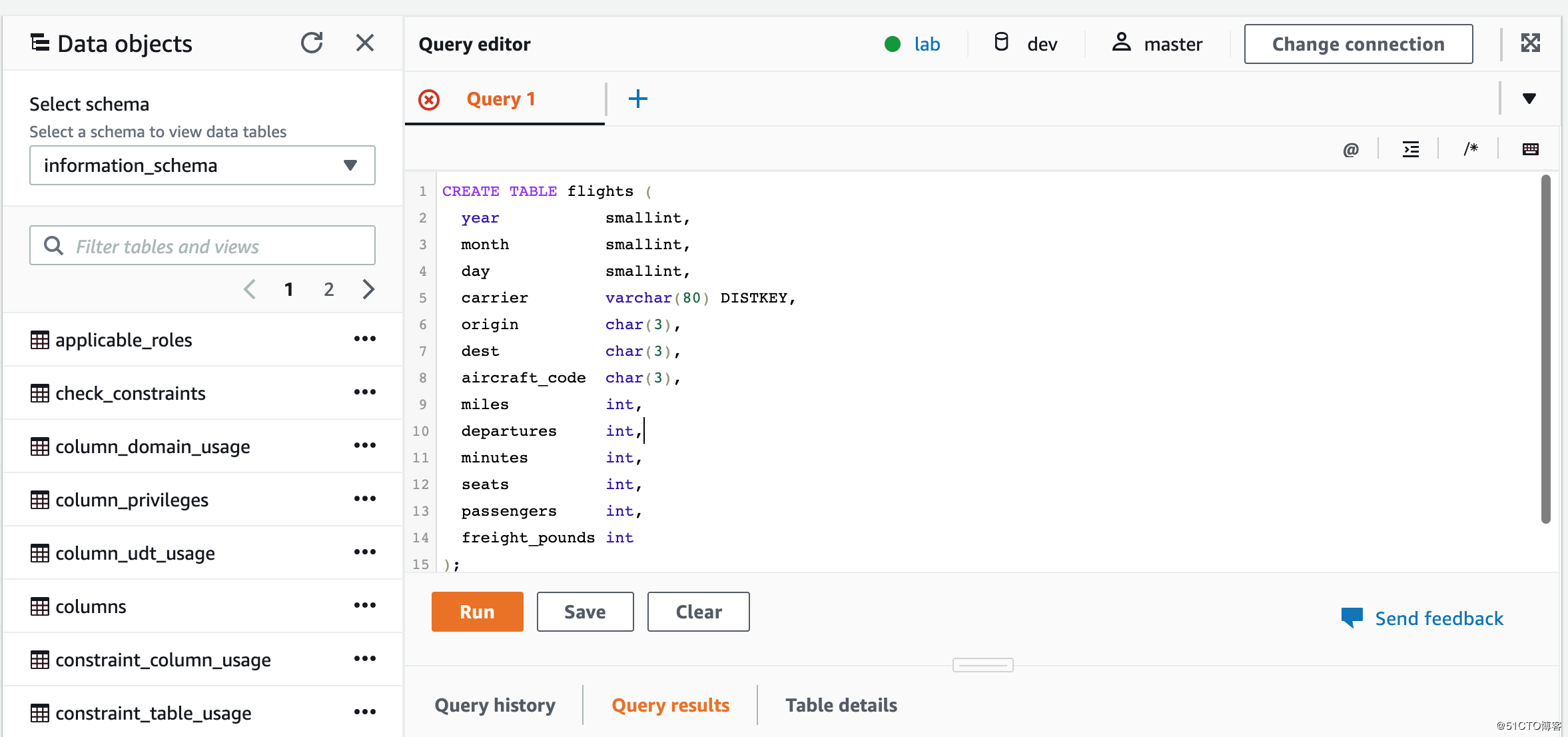
先创建数据仓库的表, copy以下代码到Redshift的Query editor中 并run:
(注意,创建的表在public的schema中)
CREATE TABLE flights (
year smallint,
month smallint,
day smallint,
carrier varchar(80) DISTKEY,
origin char(3),
dest char(3),
aircraft_code char(3),
miles int,
departures int,
minutes int,
seats int,
passengers int,
freight_pounds int
);
返回的结果:
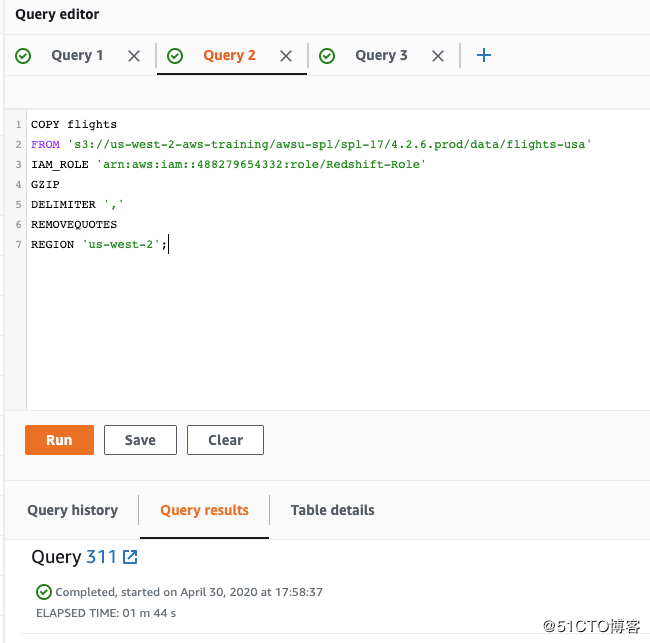
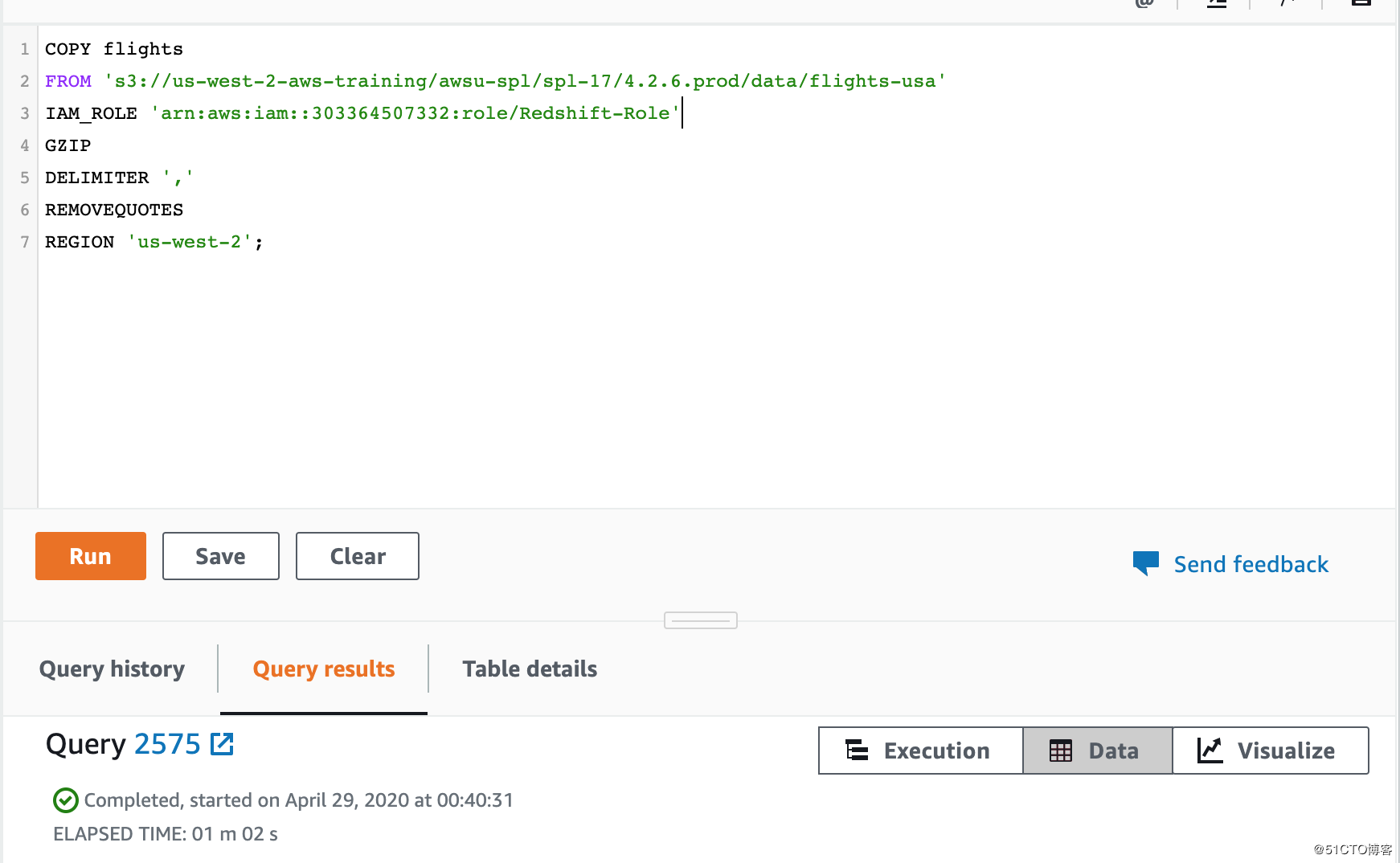
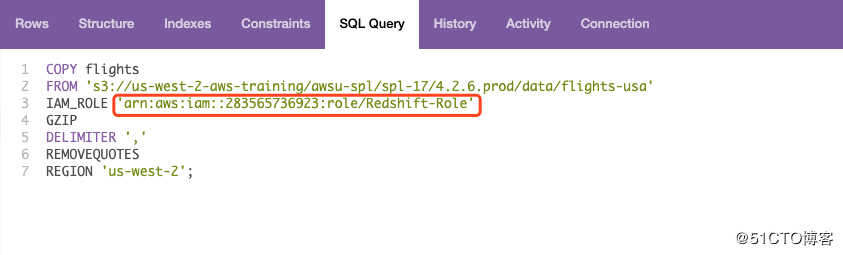
然后,Copy这段代码到Query editor中 并run :
(注意:IAM_ROLE 后边替换成自己的IAM ARN,‘arn:aws:iam::303364507332:role/Redshift-Role’ )
COPY flights
FROM ‘s3://us-west-2-aws-training/awsu-spl/spl-17/4.2.6.prod/data/flights-usa‘
IAM_ROLE ‘arn:aws:iam::303364507332:role/Redshift-Role‘
GZIP
DELIMITER ‘,‘
REMOVEQUOTES
REGION ‘us-west-2’;
(注意,如果这个query很快就执行完了,然后运行sql的时候没有查询到数据,请检查你的role是否add成功。)
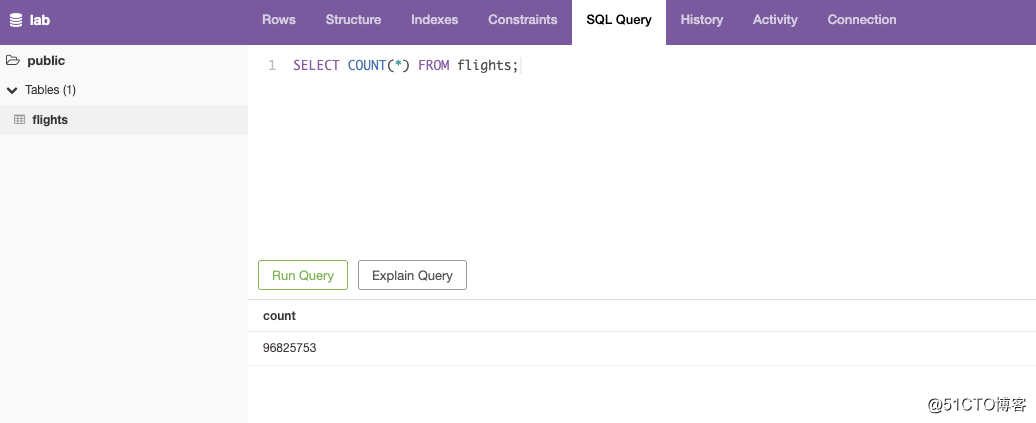
这个代码执行需要一点时间(2分钟左右,我用海外的Redshift,1分44秒搞定。为啥这么快?看数据源的地址。),因为会copy 6GB的数据包括了 23个CSV数据文件,数据统计了1990-2012年美联航的数据(96825753条数据)。
执行的时候,数据是并行加载从S3中加载到Redshift集群的。
当我们创建一个表的时候我们可以指定分区键,这次实验中分区键是 carrier varchar(80) DISTKEY,
所以当数据加载到表中时,每一行的数据会根据分区键分配到各个node slices中。在前面Redshift的架构中也有讲过,选择一个合适的分区键可以很好的提升我们的查询效率和并行数据加载的速度。
经过2-5钟的等待时间,完成数据的copy
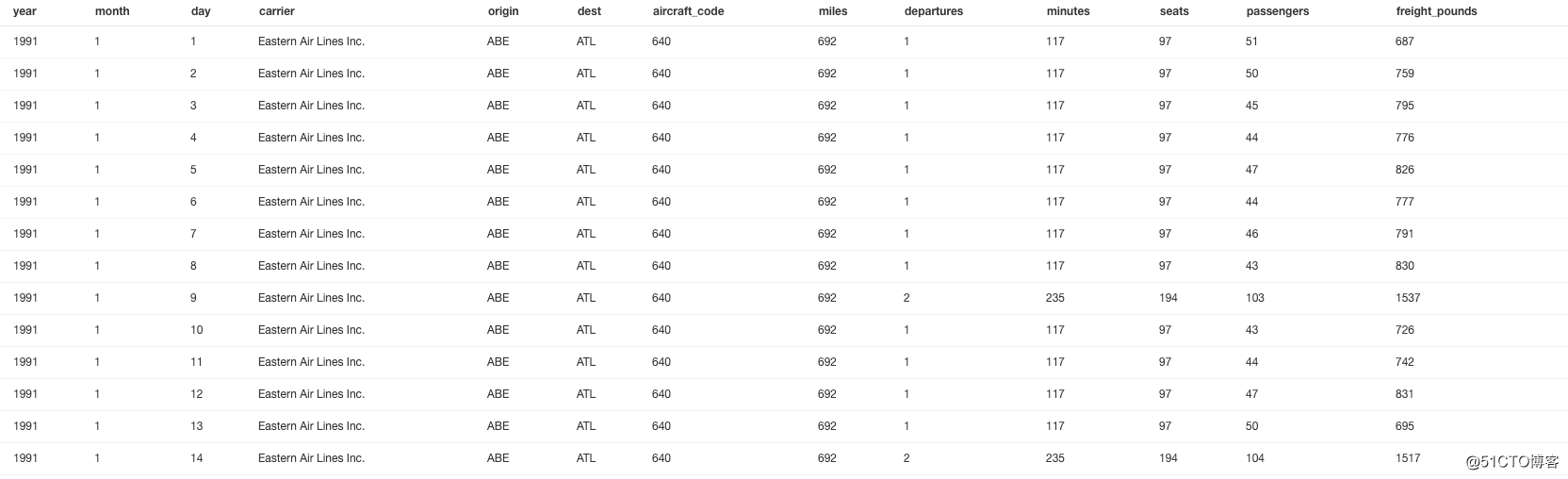
可以先用DB client 工具查看一下,数据是这样子的(九千多万条数据):Task4:Run Queries:
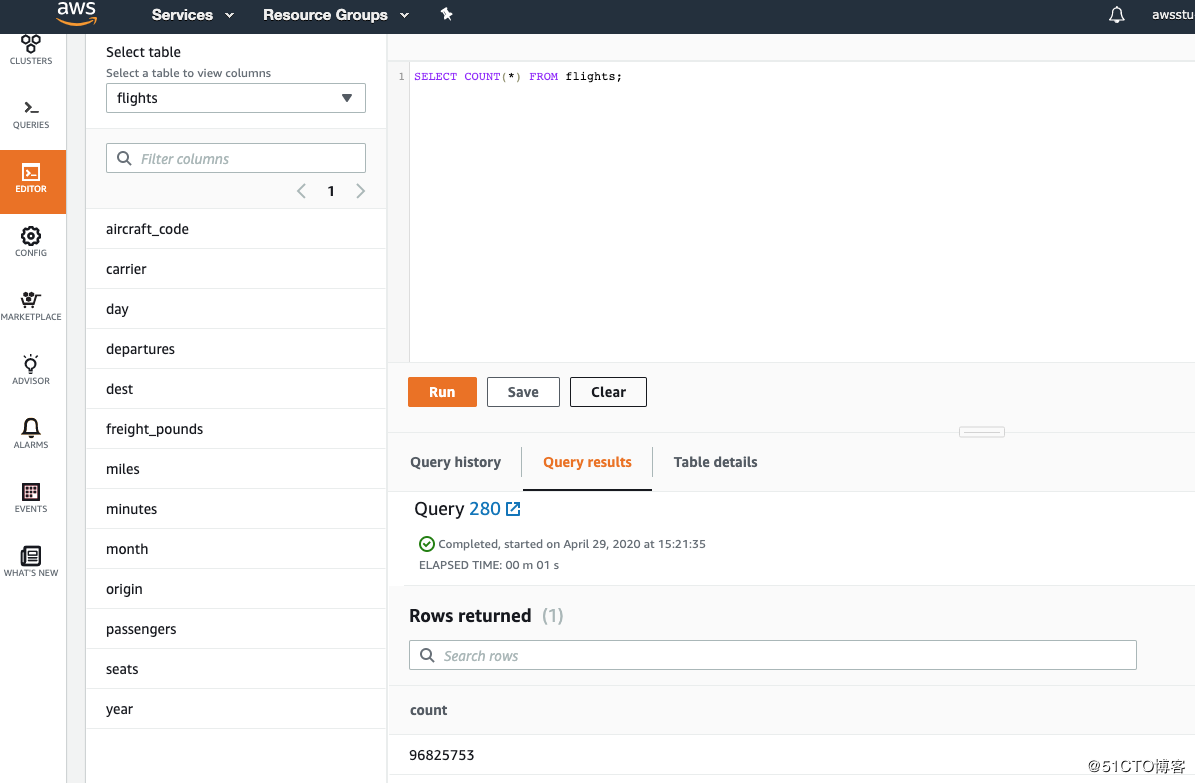
SELECT COUNT() FROM flights;
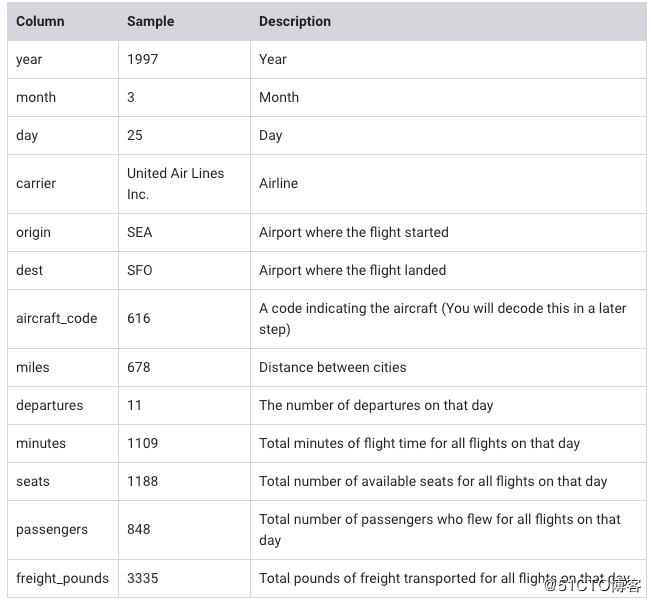
做数据分析或数据探索,理解每一个字段代表的含义十分重要,字段注释如下:
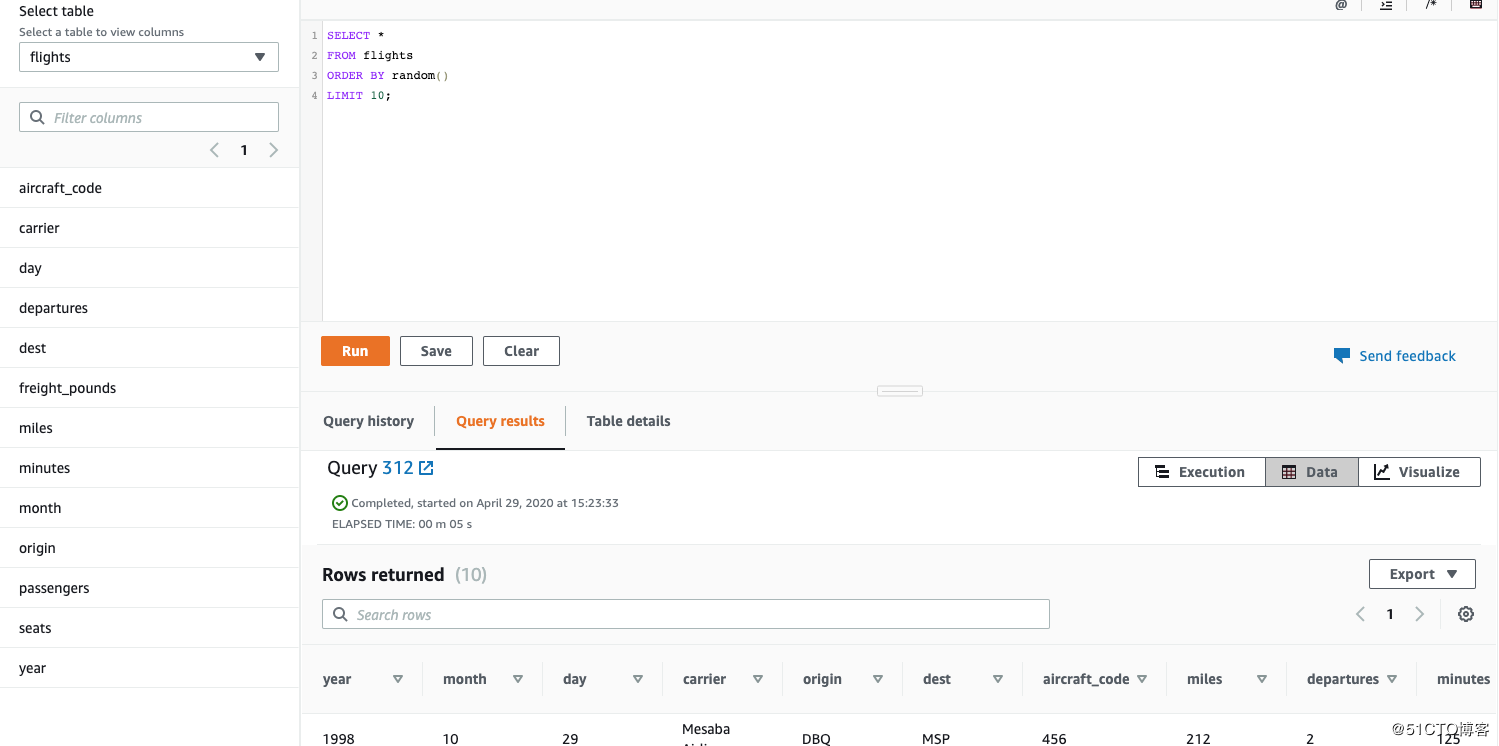
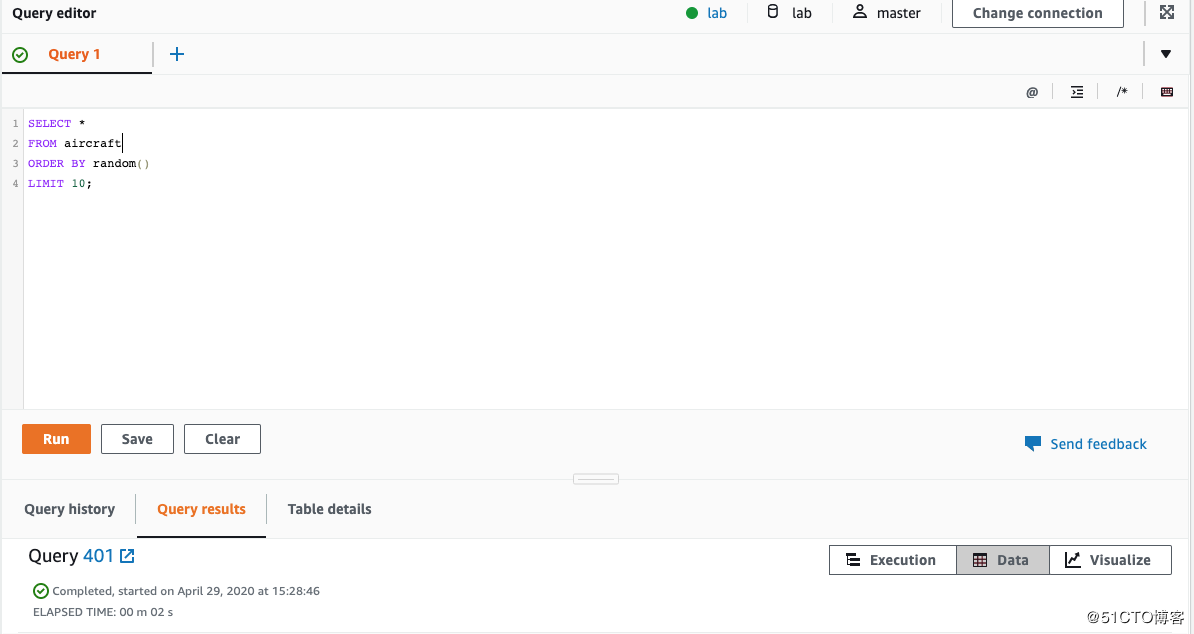
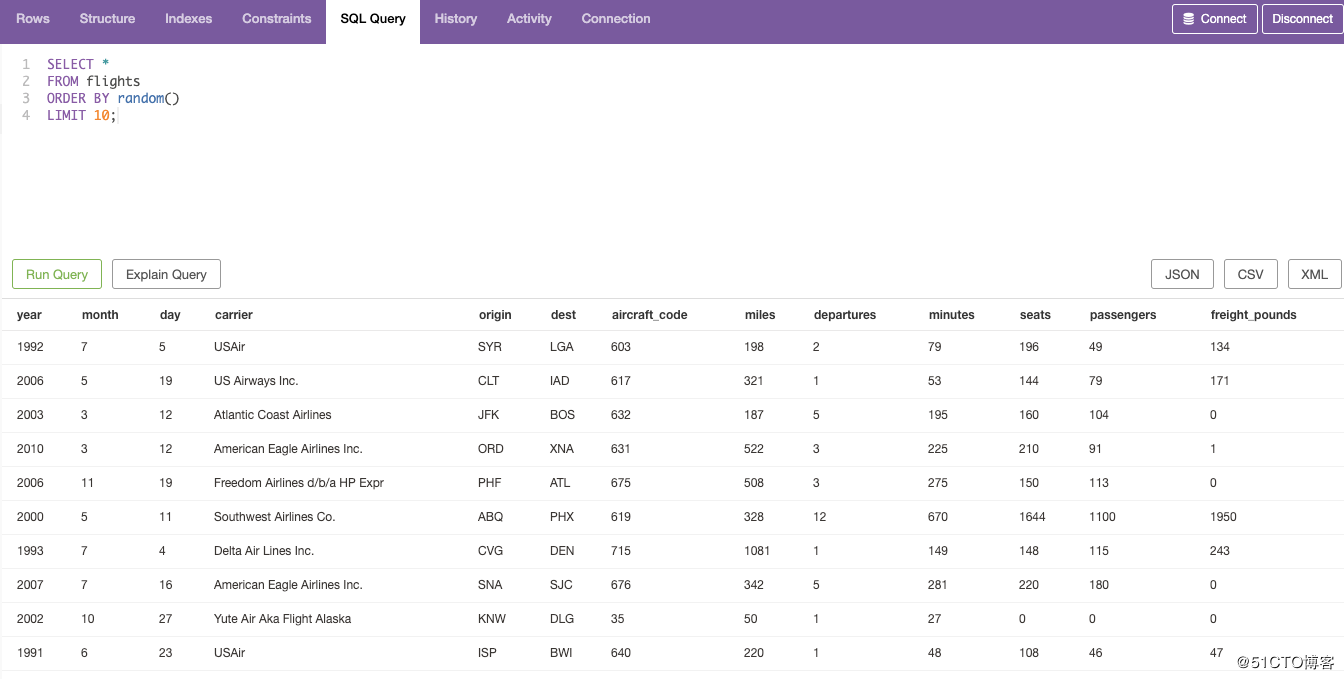
1.先随机找出flights表中的10条数据。
SELECT
FROM flights
ORDER BY random()
LIMIT 10;
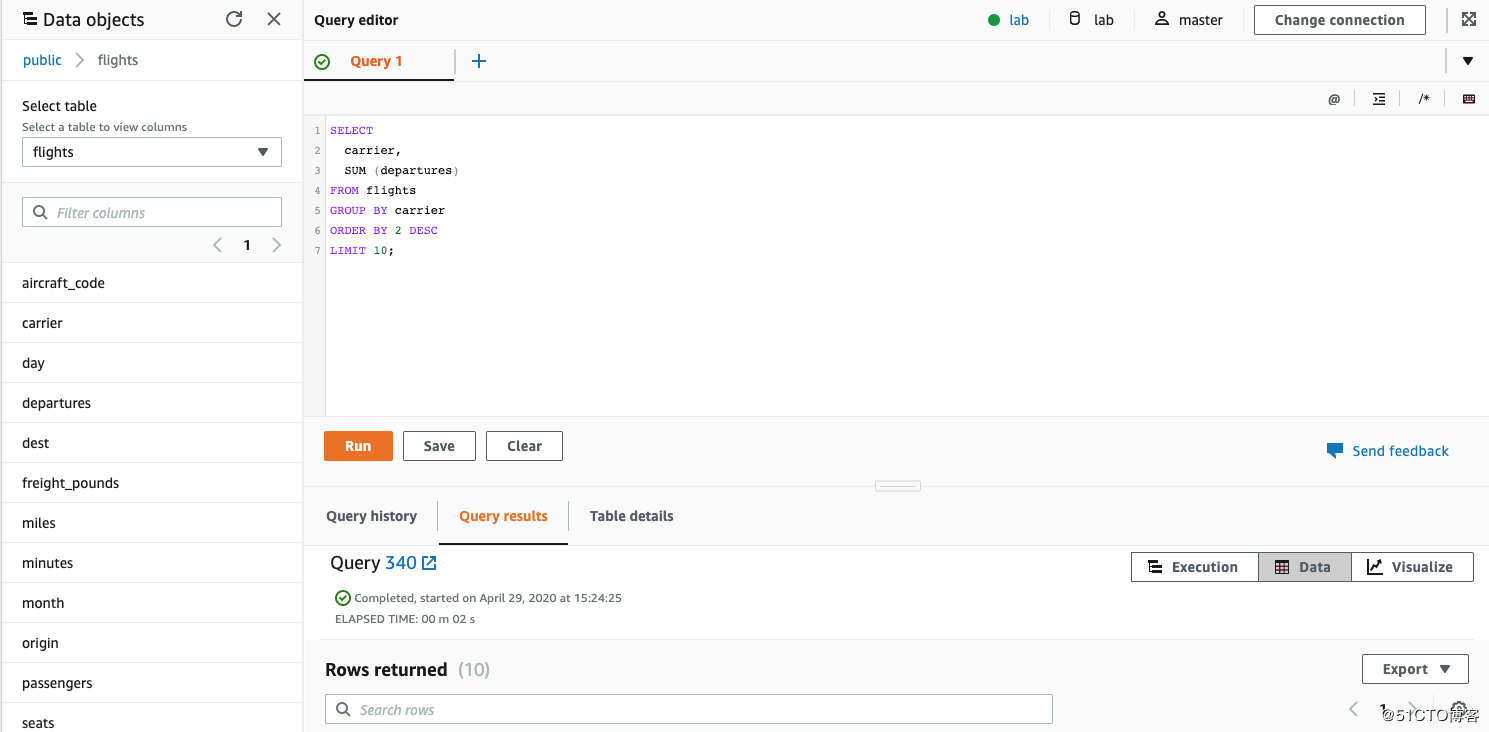
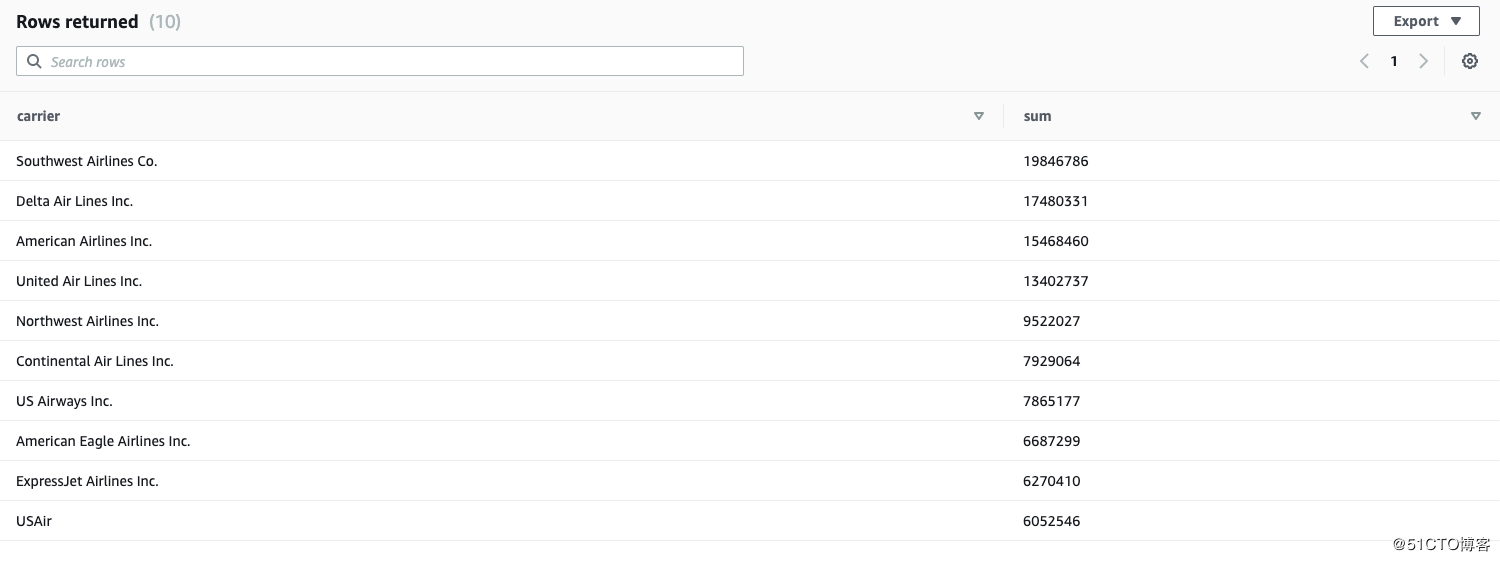
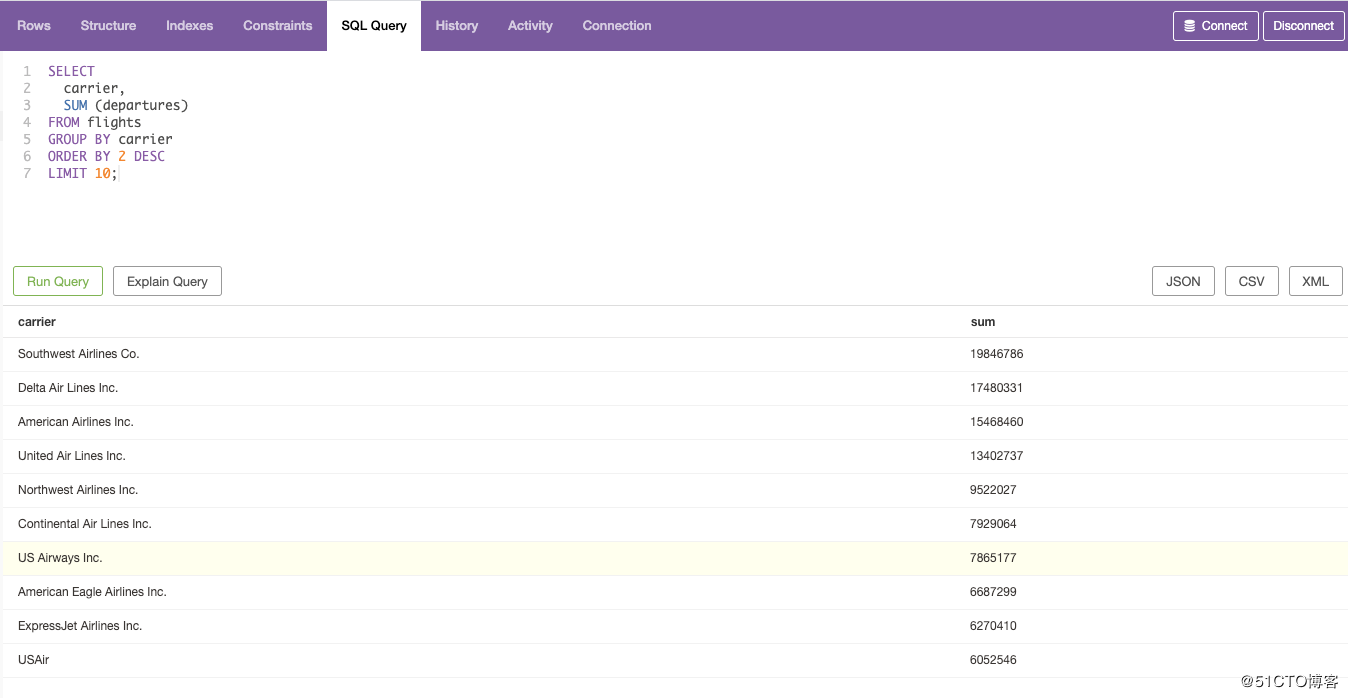
2.找出 出发次数最多的 top10 的Airline公司并groupby carrier。
SELECT
carrier,
SUM (departures)
FROM flights
GROUP BY carrier
ORDER BY 2 DESC
LIMIT 10;
其实还有很多可以写,在对应企业具体需求的时候,老板们会有很多想法,比如,
他还想知道载客量最多的TOP3的航空公司都有哪些?Task 5: Joining tables
表关联查询,跟关系型数据库的方法差不多,我在前面的课程中有讲过。数据仓库的概念实际就是数据库的升级版本,更庞大的数据,更多维度的分析。
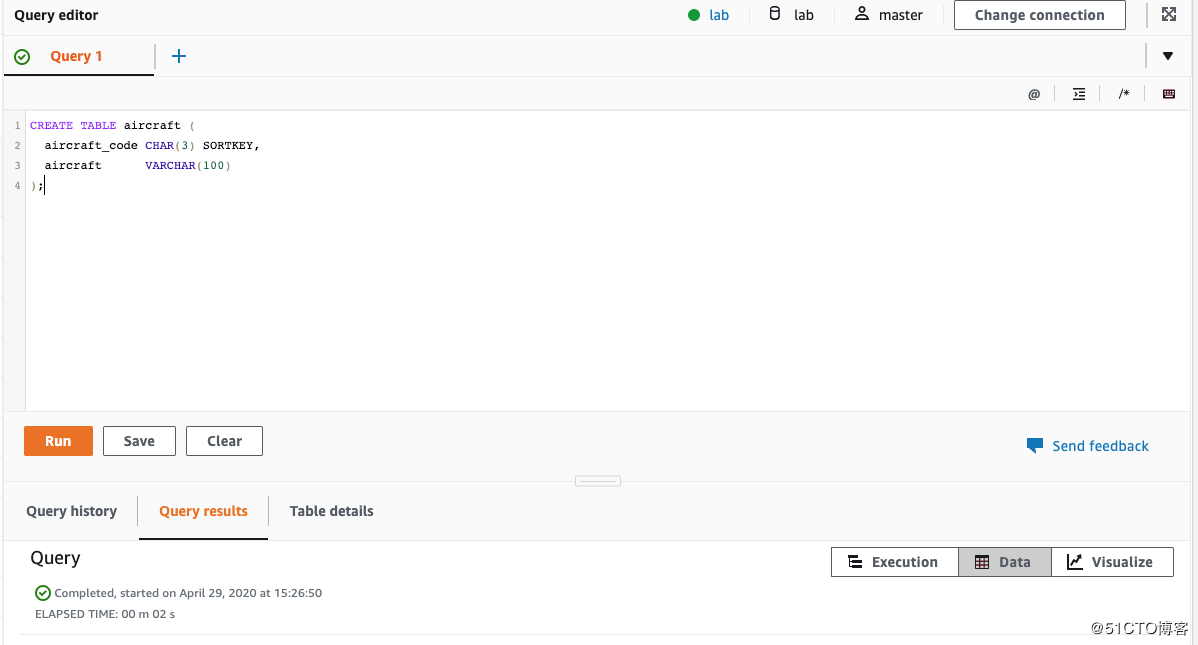
我们再创建一张table,并定义它的Schema:
CREATE TABLE aircraft (
aircraft_code CHAR(3) SORTKEY,
aircraft VARCHAR(100)
);
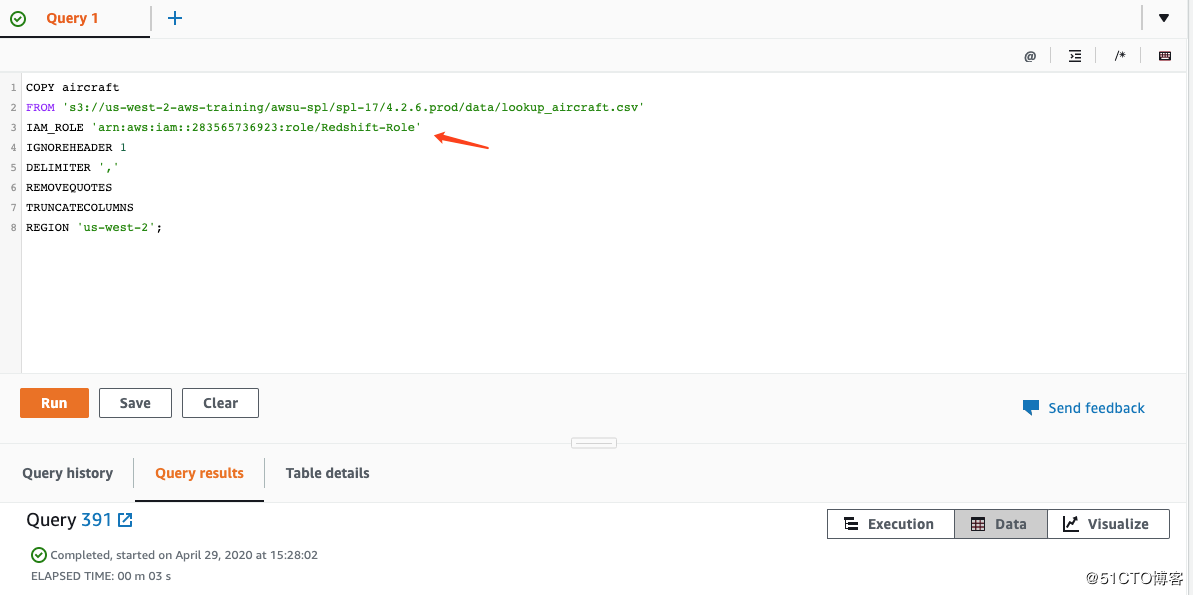
然后往表中注入数据,跟之前的步骤一样,COPY命令到Query editor中:
COPY aircraft
FROM ‘s3://us-west-2-aws-training/awsu-spl/spl-17/4.2.6.prod/data/lookup_aircraft.csv‘
IAM_ROLE ‘arn:aws:iam::283565736923:role/Redshift-Role‘
IGNOREHEADER 1
DELIMITER ‘,‘
REMOVEQUOTES
TRUNCATECOLUMNS
REGION ‘us-west-2’;
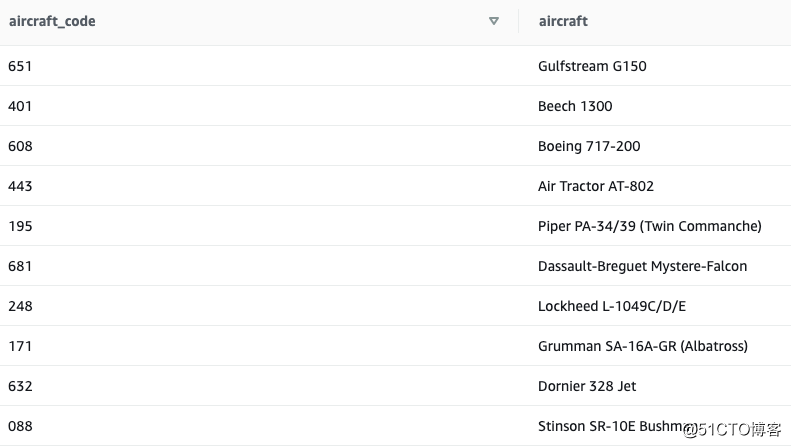
我们先随机查一下新创建的table中的随机10条数据:
SELECT *
FROM aircraft
ORDER BY random()
LIMIT 10;
返回的结果:
这个表我们发现,包含两个字段,一个是aircraft code,另一个是aircraft。这个aircraft code同时也是flights表中的字段。那么我们就可以把他们做关联join,做很多维度的查询了。(JOIN aircraft using (aircraft_code))
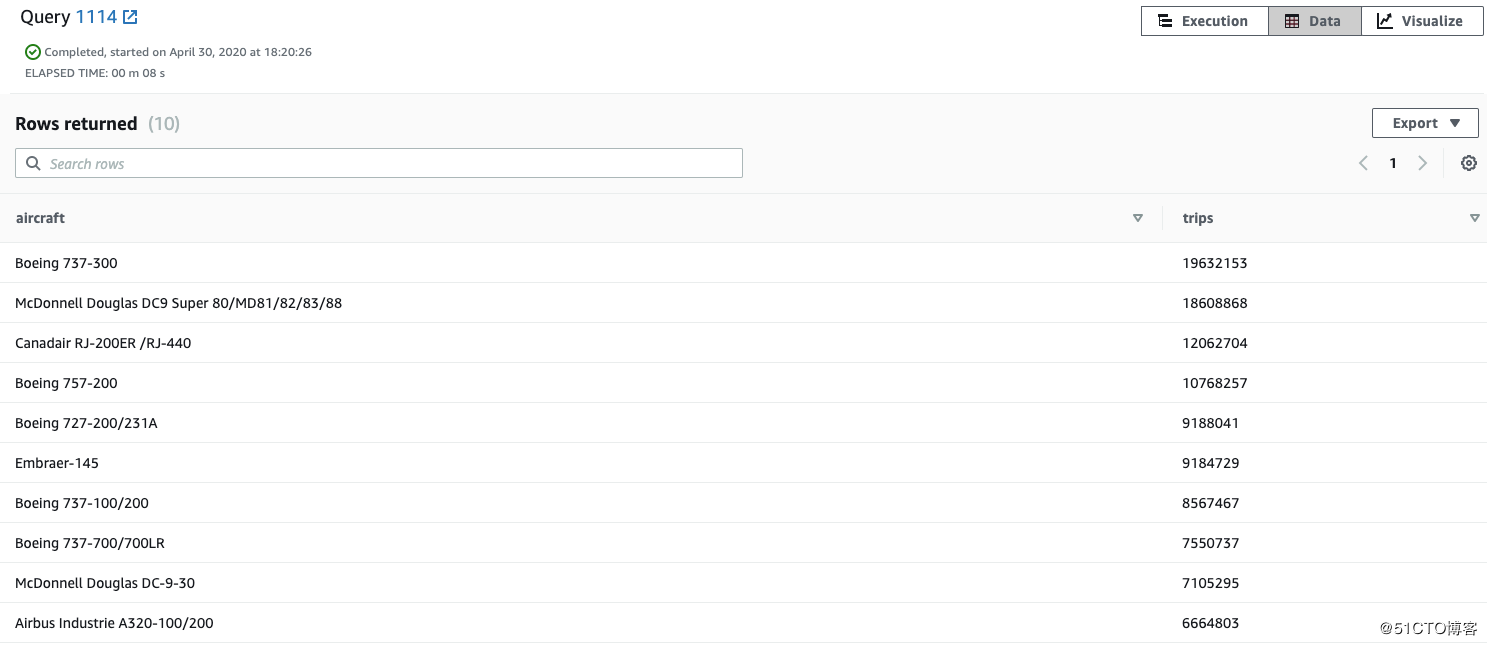
执行SQL:飞行次数(别名为trips)TOP10 的aircraft(应该是航班号)。
SELECT
aircraft,
SUM(departures) AS trips
FROM flights
JOIN aircraft using (aircraft_code)
GROUP BY aircraft
ORDER BY trips DESC
LIMIT 10;
后面的步骤是使用DB client,感兴趣同学再用它做一遍,也可以忽略。直接跳到Task6:性能分析二:使用DB client,比如pgweb去连接,注意端口号是5439.
Host地址在Redshift的
然后Run Query 就会有一个名为flights的表创建完成:Task6: 加载数据:
然后执行COPY命令
Task7:Run Queries:
运行SQL:SELECT COUNT() FROM flights;
SELECT FROM flightsORDER BY random()LIMIT 10;
SELECT carrier, SUM (departures)FROM flightsGROUP BY carrierORDER BY 2 DESCLIMIT 10;Task8:性能分析
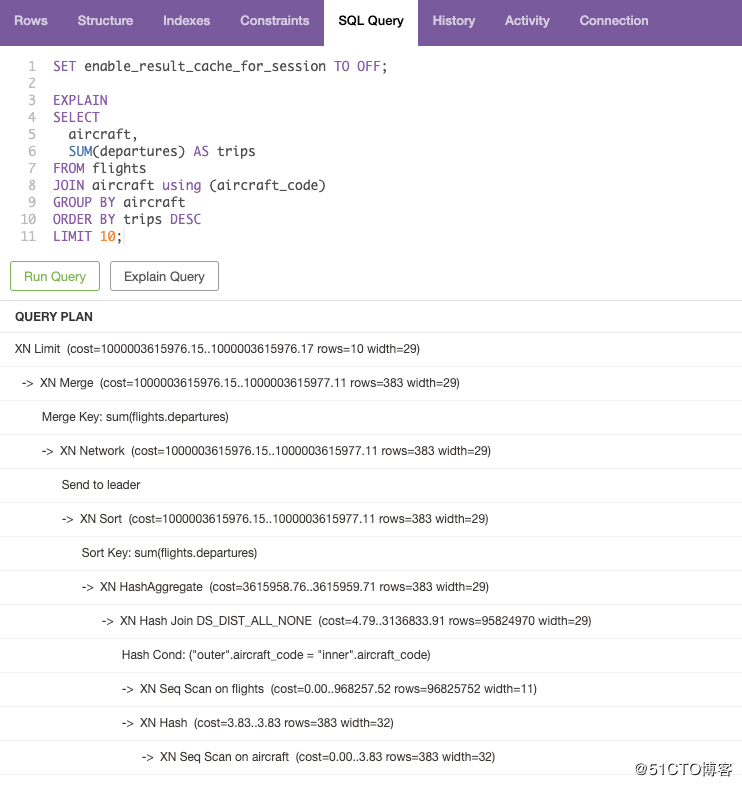
这个SQL需要用DB clinet去Run,因为Redshift query editor不支持multiple sql。ERROR: Multiple sql statements are not allowed.
SET enable_result_cache_for_session TO OFF;EXPLAIN
SELECT
aircraft,
SUM(departures) AS trips
FROM flights
JOIN aircraft using (aircraft_code)
GROUP BY aircraft
ORDER BY trips DESC
LIMIT 10;
什么意思呢?这句SQL主要是分析每一个逻辑步骤中query所消耗的时长。什么时候执行SUM,它的COST是?什么时候执行JOIN,它的COST是?对应优化SQL的查询性能十分重要。
数据压缩和列式存储
这两点是数据仓库查询效率比传统关系型数据库快的主要原因。
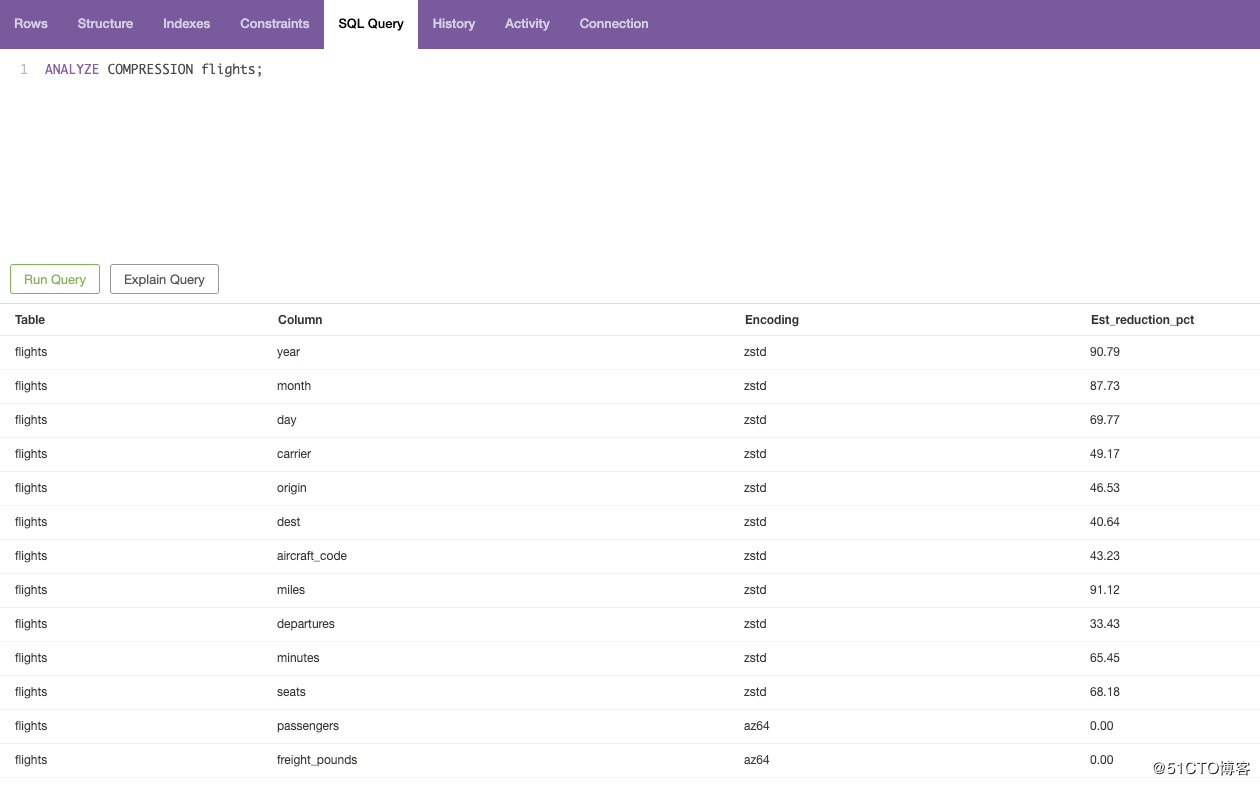
执行这条SQL,我们来分析一下:
ANALYZE COMPRESSION flights;
Encoding 是压缩方式,Est_reduction_pct 代表压缩率。是不是很惊人?!
具体可以参考:https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/r_ANALYZE_COMPRESSION.htmlTask9:从已有的表中创建新的表。
目的是为了进一步分析,比如我想分析有多少飞往洛杉矶的乘客?TOP10最受欢迎的飞往Las Vegas的航班是?
好,我们开始,创建一个airport的table,并定义SORTKEY:
CREATE TABLE airports (
airport_code CHAR(3) SORTKEY,
airport varchar(100)
);COPY airports
FROM ‘s3://us-west-2-aws-training/awsu-spl/spl-17/4.2.6.prod/data/lookup_airports.csv‘
IAM_ROLE ‘arn:aws:iam::488279654332:role/Redshift-Role‘
IGNOREHEADER 1
DELIMITER ‘,‘
REMOVEQUOTES
TRUNCATECOLUMNS
REGION ‘us-west-2‘;
创建一个Las Vegas 航班的table.
CREATE TABLE vegas_flights
DISTKEY (origin)
SORTKEY (origin)
AS
SELECT
flights.*,
airport
FROM flights
JOIN airports ON origin = airport_code
WHERE dest = ‘LAS’;
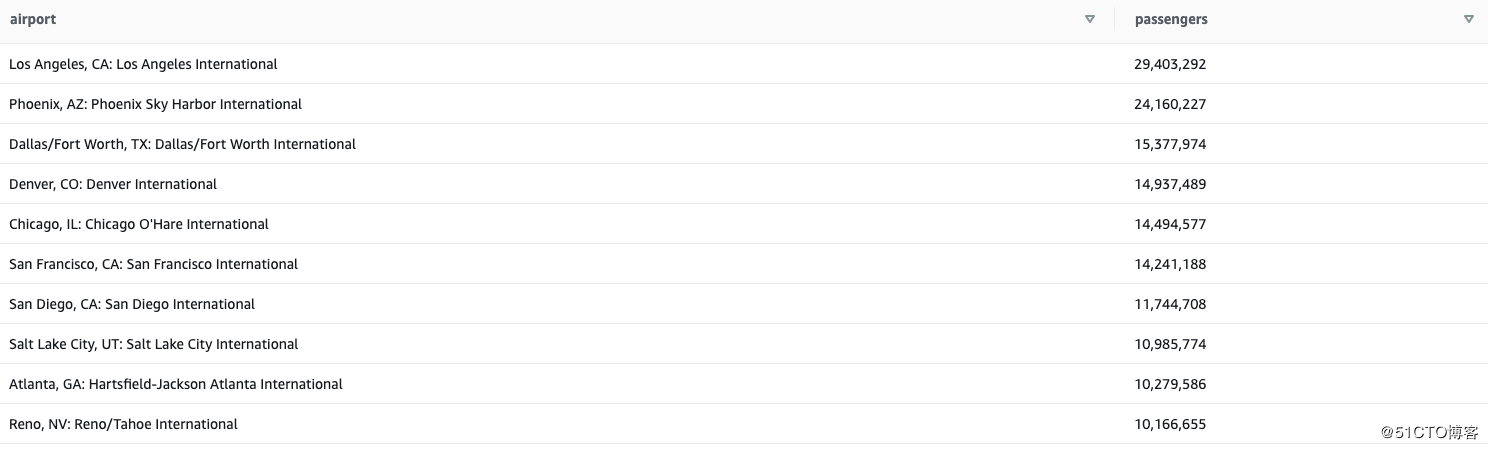
然后我们找到TOP10最受欢迎的飞往Las Vegas的航班是?
SELECT
airport,
to_char(SUM(passengers), ‘999,999,999‘) as passengers
FROM vegas_flights
GROUP BY airport
ORDER BY SUM(passengers) desc
LIMIT 10;Task10:检查磁盘空间和数据分布
SELECT
owner AS node,
diskno,
used,
capacity,
used/capacity::numeric * 100 as percent_used
FROM stv_partitions
WHERE host = node
ORDER BY 1, 2;
Used:Megabytes,多少MB磁盘使用
Capacity:磁盘空间。
Percent_used:用了多少。这里node0 用了0.54%,node1 用了 0.42%。Task11:监控与维护
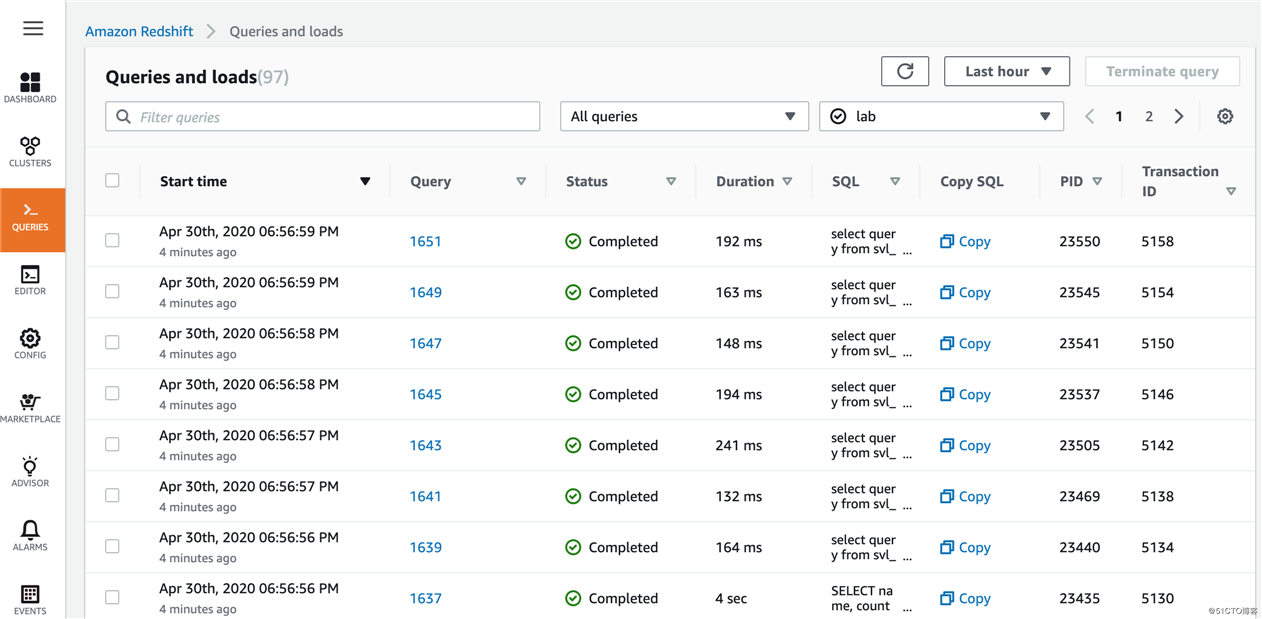
每一个Query的执行情况:
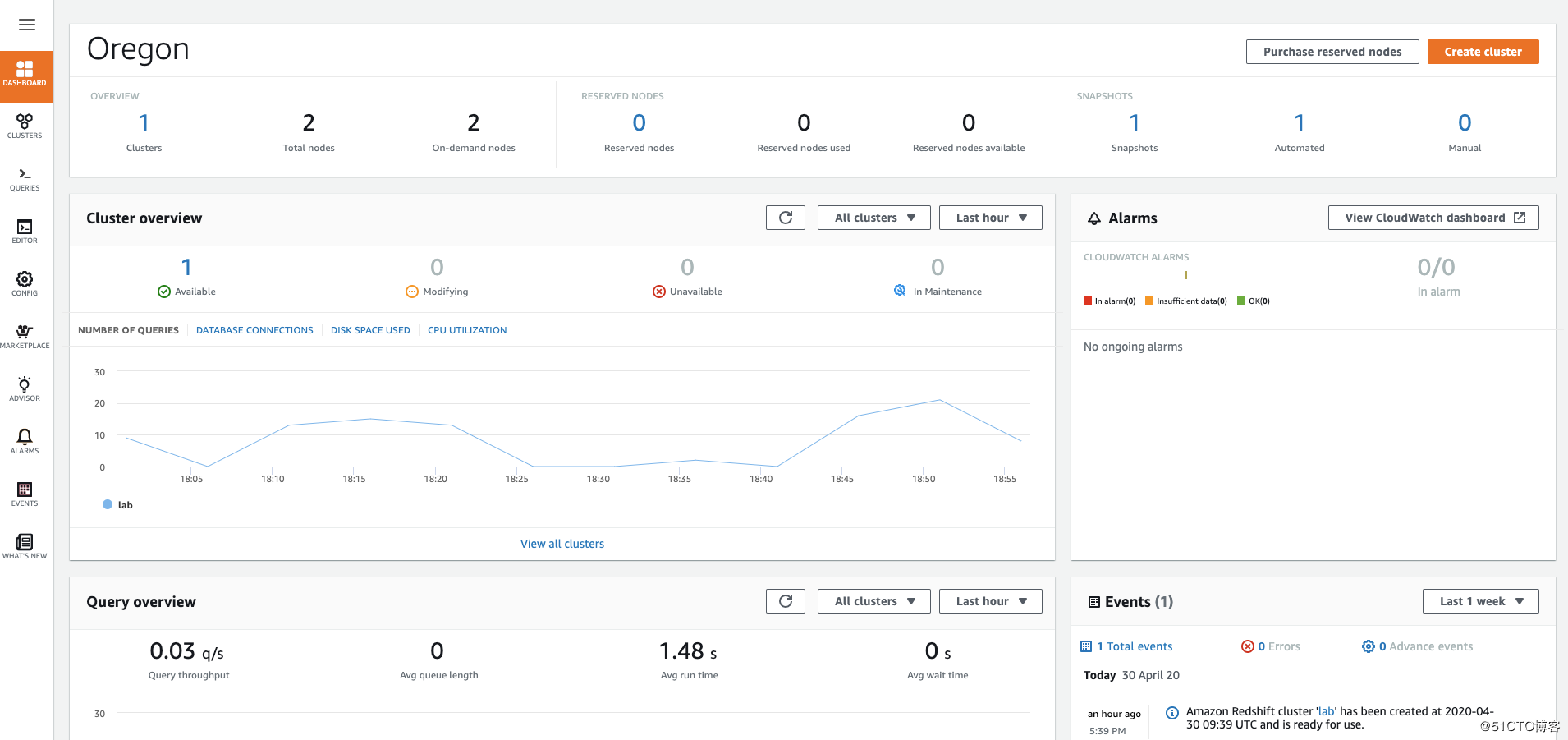
集群的监控概况:
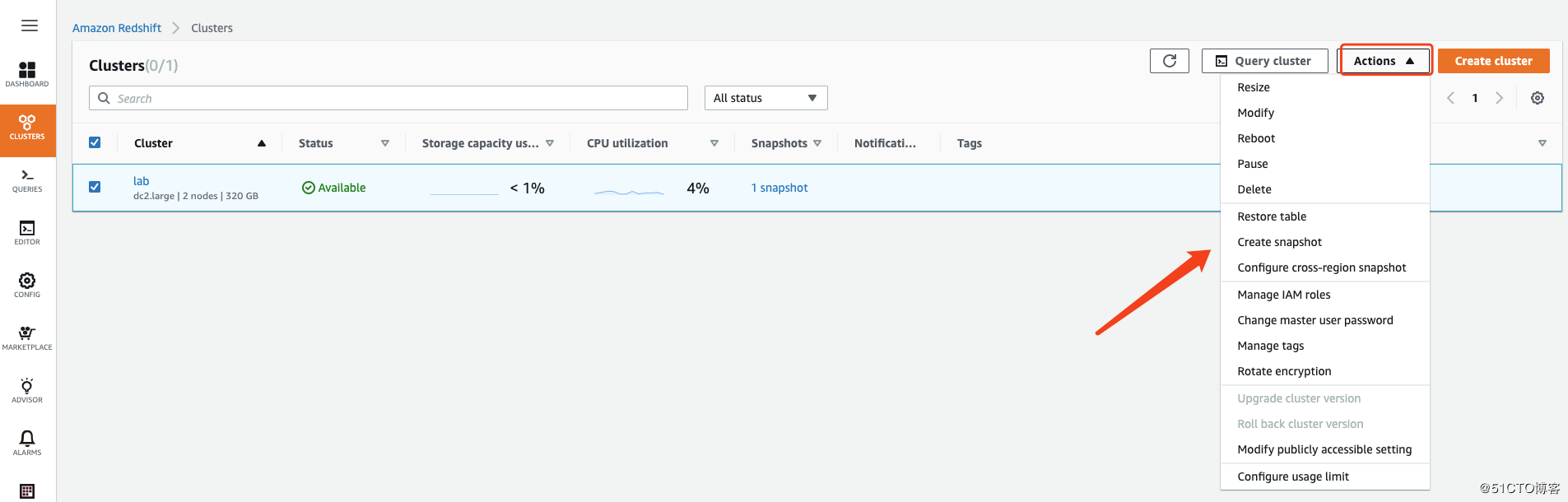
对现有集群的配置与更改:
加密、快照、还原、修改配置信息等等都在这里了。
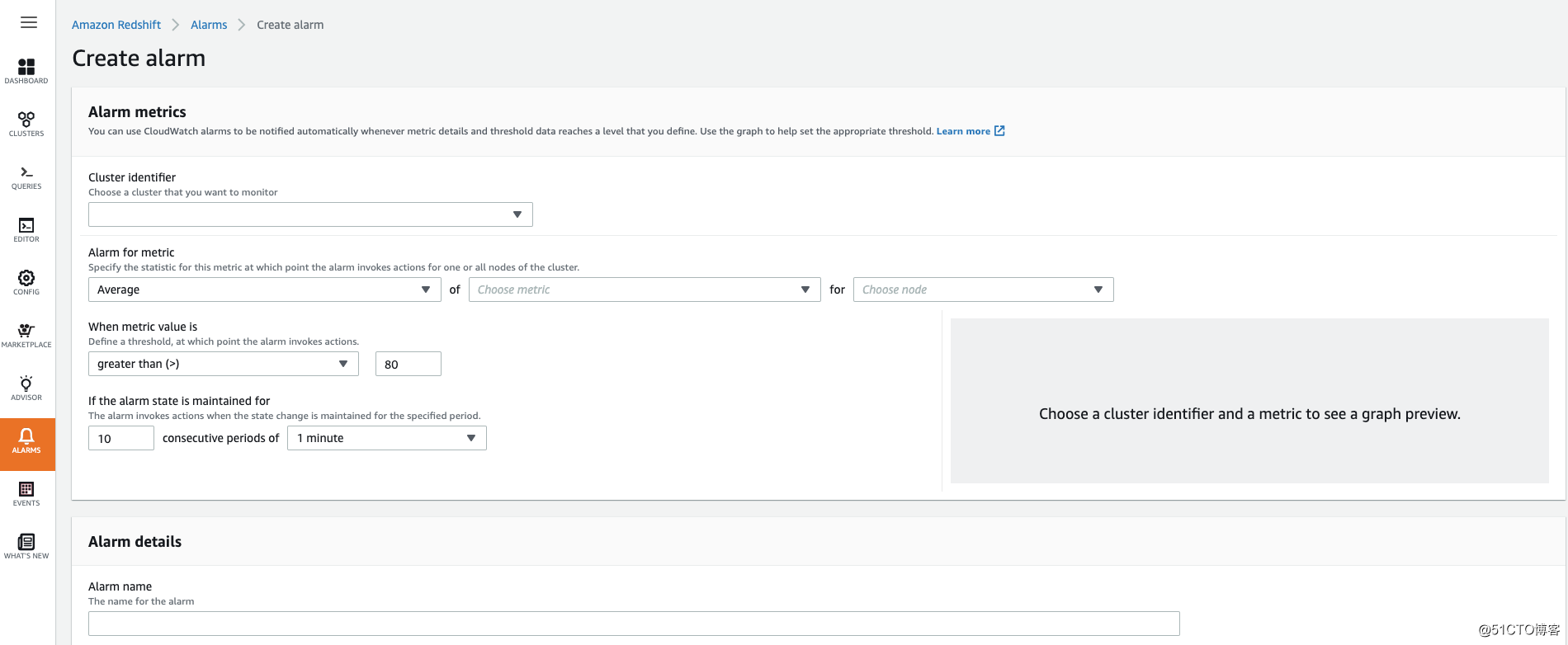
创建报警:
好,没想到一步一步的做,写了这么多。
最后别忘了关闭集群,土豪随意。
详细视频参考:
https://edu.51cto.com/center/course/lesson/index?id=558306
【AWS征文】[数据仓库]Redshift 动手实验---分析美联航airline数据
标签:table 注入 tps action erro editor 版本 copy zip
原文地址:https://blog.51cto.com/13746986/2531872