标签:动态 源文件 缓存 网络连接 top 世界 效率 val ref
本文主要阐述软件性能测试中的一些调优思想和技术,节选自作者新书《软件性能测试分析与调优实践之路》部分章节归纳。
1、性能分析调优模型
性能测试除了为获取性能指标外,更多是为了发现性能瓶颈和性能问题,然后对性能问题和瓶颈进行分析和调优,在当今互联网高速发展的时代,性能调优的模型可以归纳总结如下图所示。
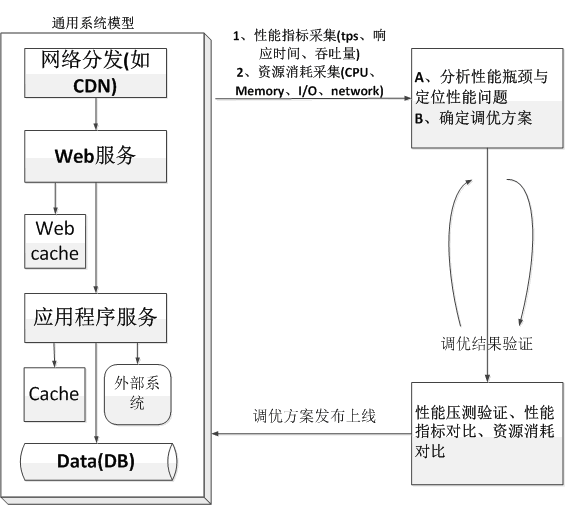
系统模型中相关的组件描述如下表所示
|
组件 |
描述 |
|
网络分发 |
网络分发是高速发展的互联网时代常用的降低网络拥塞,快速响应用户请求的一种技术手段,最常用的网络分发就是CDN(Content Delivery Network,即内容分发网络),依靠部署在世界各地的边缘服务器,通过中心平台的负载均衡、源服务器内容分发、调度等功能模块,使世界各地用户就近获取所需内容,而不用每次都到中心平台的源服务器获取响应结果,比如南京的用户直接访问部署在南京的边缘服务器,而不需要访问部署在遥远的北方的北京的服务器 |
|
Web服务器 |
Web服务器用于部署Web服务,Web服务器的作用就是负责请求的响应和分发以及静态资源的处理 |
|
Web服务 |
Web服务指运行在Web服务器上的服务程序,最常见的Web服务就是Nginx和Apache |
|
Web Cache |
Web Cache指Web层的缓存,一般都是临时缓存HTML、CSS、图像等静态资源文件 |
|
应用服务器 |
应用服务器用于部署应用程序,如Tomcat、WildFly、普通的Java应用程序(如jar包服务),IIS等 |
|
应用程序服务 |
应用程序服务指运行在应用服务器上的程序,比如Java应用,C/C++应用、Python应用,一般用于处理用户的动态请求 |
|
应用缓存 |
应用缓存指应用程序层的缓存服务,常用的应用缓存技术有Redis、Memcached等,这些技术手段也是动态扩展的高并发分布式应用架构中经常使用的技术手段 |
|
数据库(DB) |
用于数据的存储,可以包括关系型数据库以及NoSql数据库(非关系型数据库),常见的关系型数据库有Mysql、Oracle、Sqlserver、DB2等,常见的NoSql数据库有Hbase、MongoDB、ElasticSearch等 |
|
外部系统 |
指当前系统依赖于其他的外部系统,需要从其他的外部系统中通过二次请求获取数据,外部系统有时候可能会存在很多个 |
上图中的系统模型是一个互联网中常见的用户请求的分层转发和处理的过程,在性能调优时就是不断采集系统中的性能指标以及系统模型中各层的资源消耗,从中发现性能瓶颈和性能问题,然后对瓶颈和问题进行分析诊断来确定性能调优方案,最后通过性能压测进行验证调优方案是否有效,如果无效继续重复这个过程进行性能分析,直到调优方案有效,瓶颈和问题得到解决。这个过程一般是非常漫长,因为很多时候性能调优方案往往不是一次就能有效或者一次就能解决所有的瓶颈和问题,或者解决了当前的瓶颈和问题,但是继续性能压测又可能会出现新的瓶颈和问题。
转载请注明出处:来源于博客园,作者:张永清,https://www.cnblogs.com/laoqing/p/13660768.html
2、性能分析与调优思想
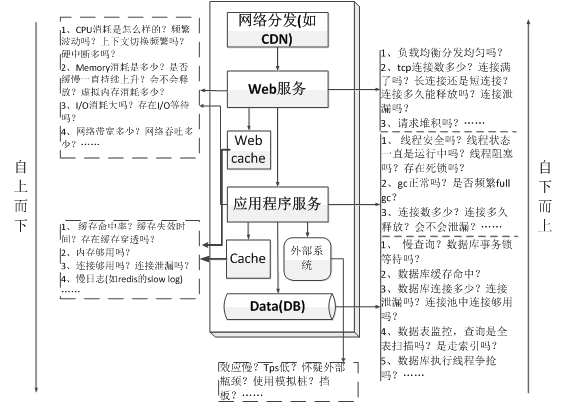
2.1、分层分析
分层分析指的就是按照系统模型以及系统架构分层按照调用链进行监控分析和问题排查,如下图所示。
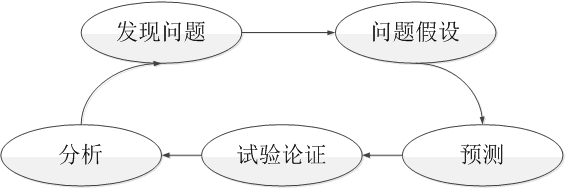
2.2、科学论证
科学论证一般包括发现问题、问题假设、预测、试验论证、分析这5个步骤,如下图所示。
科学论证法进行性能分析与调优的示例如下图所示。

2.3、问题追溯与归纳总结
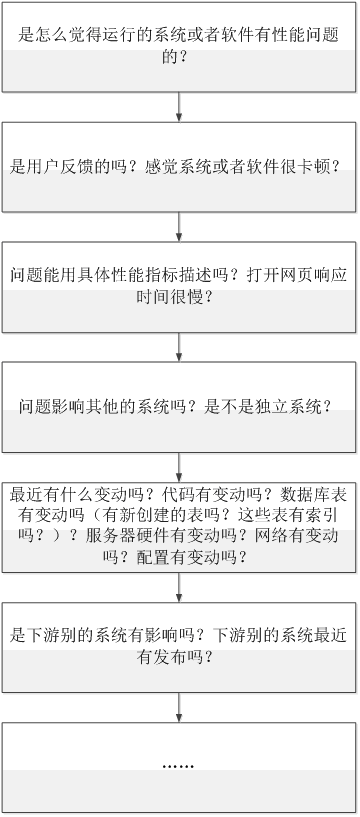
(1)、问题追溯分析指的是根据问题去追溯最近系统或者环境发生的变化,一般适用于生产已上线系统的版本发布或者环境变动导致的性能问题,问题追溯的步骤一般如下图所示,问题追溯分析是通过在追溯和描述中去逐步排查可能导致问题的原因。
(2)、归纳总结指的根据经验的总结,在出现某种性能瓶颈或者性能问题时根据以往总结的原因进行逐一排查。
1、缓存调优
互联网高速发展的这个时代,缓存使用已经成为了很多大型系统或者电商网站使用的一个关键技术,合理的设计缓存直接关系到了一个系统或者网站的并发访问能力和用户体验。网站按照存放地点的不同可以分为用户端缓存和服务端缓存,如下图所示。

缓存调优的关键点说明如下:
(1) 要处理好缓存数据全部丢失后,如何能快速把数据重新加载到缓存中。
(2) 缓存数据的分布式冗余备份,当出现数据丢失时,可以迅速切换使用备份数据。
2、同步转异步推送
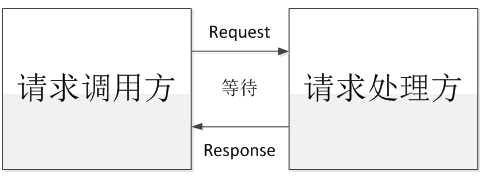
同步:指的是系统收到一个请求后,在该请求没有处理完成时,就一直不返回响应结果,直到处理完成了才返回响应结果,如下图所示。
转载请注明出处:来源于博客园,作者:张永清,https://www.cnblogs.com/laoqing/p/13660768.html
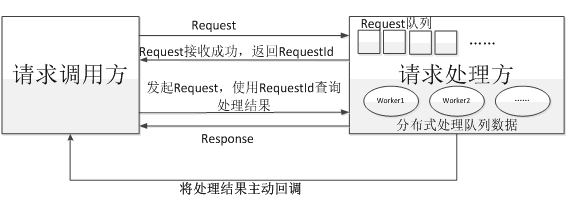
异步:与同步相比,异步指的是系统收到一个请求后,只立即返回请求调用方请求接收成功,在请求处理完成后,再异步推送处理结果给调用方,或者请求调用方在间隔一定时间再重新来获取请求结果。如下图所示。
转载请注明出处:来源于博客园,作者:张永清,https://www.cnblogs.com/laoqing/p/13660768.html
同步转异步主要是解决同步请求时的阻塞等待,一直处于阻塞等待的请求,往往会造成连接不能快速释放,从而导致高并发处理时,连接数不够用,通过队列异步接收请求后,请求处理方再进行分布式的并行处理,从而达到处理能力扩展,并且网络连接也可以快速释放。
3、拆分
拆分指的是将系统中的复杂的业务调用拆分为多个简单的调用,如下图所示,一般遵循的原则如下:
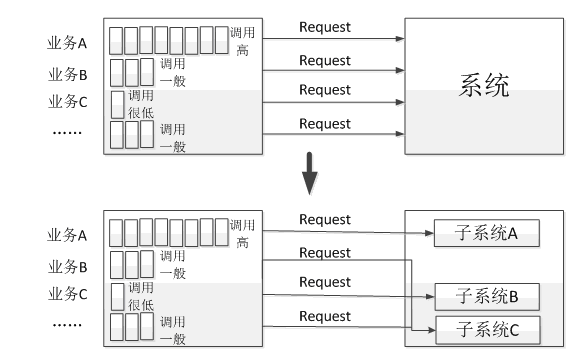
系统拆分带来的好处就是高并发的业务不会对低并发业务的性能造成影响,而且系统在硬件扩展时,也可以有针对性的进行扩展,避免资源的浪费。
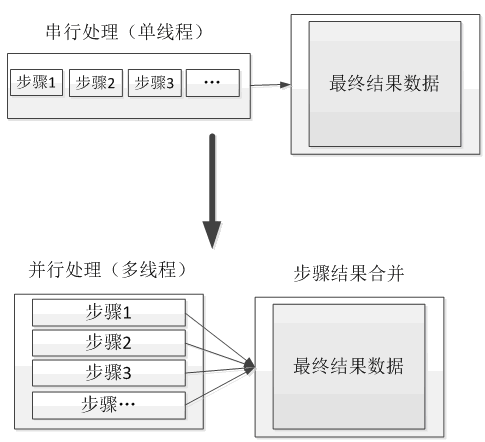
4、任务分解与并行计算
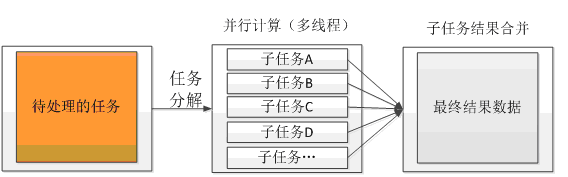
任务分解与并行计算指的是将一个任务拆分为多个子任务,然后将多个子任务并行进行计算处理,最后只需要再将并行计算的结果合并在一起返回即可。目的是通过并行计算的方式来增加处理性能,如图所示。
转载请注明出处:来源于博客园,作者:张永清,https://www.cnblogs.com/laoqing/p/13660768.html
另外对于包含多个处理步骤的串行任务,也可以尽量按照如下图所示的方式转换为并行计算处理。
5、索引与分库分表
索引指应用程序在查询时,尽量走数据库索引查询,数据库表在创建时也尽量对查询条件的字段建立合适的索引,这里强调一定是合适的索引,如果索引建立不合适,不仅对查询效率没有任何的帮助,反而会使数据库表在插入数据时变的更慢,因为一旦建立了索引后,数据在插入时,索引也会自动更新,这样就加大数据库的插入时的资源消耗。比如数据库表中有一个字段为“status”,而“status”的取值只有0、1、2 三个值,这时候如果对“status”建立索引,对查询效率就没有任何帮助,因为“status”字段的值只有1、2、3这三个值,建立索引后根据“status”去检索时,需要扫描的数据还是非常的大,因为“status”字段的取值范围太少,过滤出来的数据量还是非常的庞大。
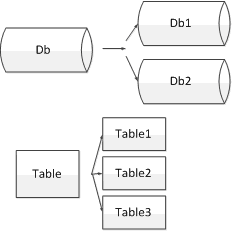
正确的使用索引可以很好的提高查询效率,但是如果一个表的数据量非常的庞大,比如达到了亿万级别了,此时索引查询很慢了,并且新数据插入时也很慢,此时就需要对数据进行分表或者分库了,分库一般指的是一个数据库的存储已经很大了,查询和插入时I/O消耗非常大,此时就需要将数据库拆分成2个库来减轻读写时I/O的压力,如下图所示。
转载请注明出处:来源于博客园,作者:张永清,https://www.cnblogs.com/laoqing/p/13660768.html
常见的分库分表方式如下:
数据分库分表后,带来的另一个好处就是,如果单次查询时,需要查询多个分表,那么此时就可以通过多线程并行的方式去查询每个分表,最后对每个分表的查询结果做一次合并即可,这样也可以使得查询的效率更高。
关于软件性能分析调优,可以加微信号yq597365581或者微信号hqh345932,进入专业的性能分析调优群进行交流沟通。

备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。
本文作者:张永清 文章选自 作者2020年初即将出版的《软件性能测试、分析与调优实践之路》一书。文章链接:https://www.cnblogs.com/laoqing/p/13660768.html

个人介绍:从事功能测试、自动化测试、性能测试、Java软件开发、大数据开发、架构师等工作十多年,在自动化测试设计、性能测试设计、性能诊断、性能调优、分布式架构设计等方面积累了多年经验,参与过的系统涉及公安、互联网、移动互联网、大数据、人工智能等领域。先后任职于江苏飞搏软件、苏宁大数据研发中心、苏宁研究院、苏宁人工智能研发中心、紫金普惠研发中心等公司,历任测试经理、技术经理、部门经理、高级架构师等职位,重点关注大数据、图像处理、高性能分布式架构设计等领域,著有《robot framework 自动化测试框架核心指南》、《软件性能测试、分析与调优实践之路》,apache dolphinscheduler 贡献者。
软件性能测试分析与调优实践之路-性能分析调优思想与调优技术总结
标签:动态 源文件 缓存 网络连接 top 世界 效率 val ref
原文地址:https://www.cnblogs.com/laoqing/p/13660768.html