标签:也会 standards 推广 富士 workload 咨询 基础 今天 exp
前几天AWS中国开了在线技术峰会,宣布咱成了AWS中国的战略合作伙伴和第一家中国的授权增值推广商(Value Add Promoter),一起干从销售到渠道还有MSP服务的活,目测又有很多事情要折腾了。让我更感兴趣的其实是之后AWS CTO Werner Vogels谈的架构完善框架(Well-architected Framework)。这个框架是一整套的设计云上系统的方法论,包括卓越运营(Operational Excellence),安全性(Security), 可靠性(Reliability), 性能效率(Performance efficiency) 和成本优化(Cost optimization)五大支柱。通过描述关键概念,设计原则和架构的最佳实践,为架构师提供了一致性的方法论,评估架构和实施的设计原则。
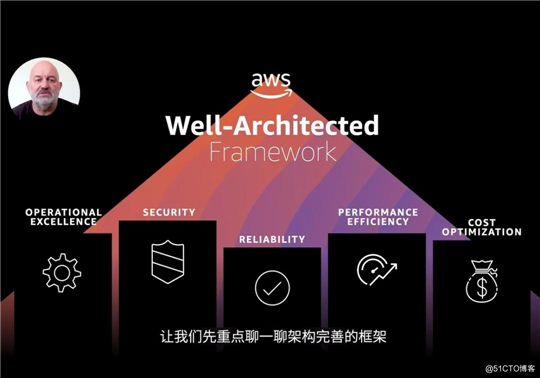
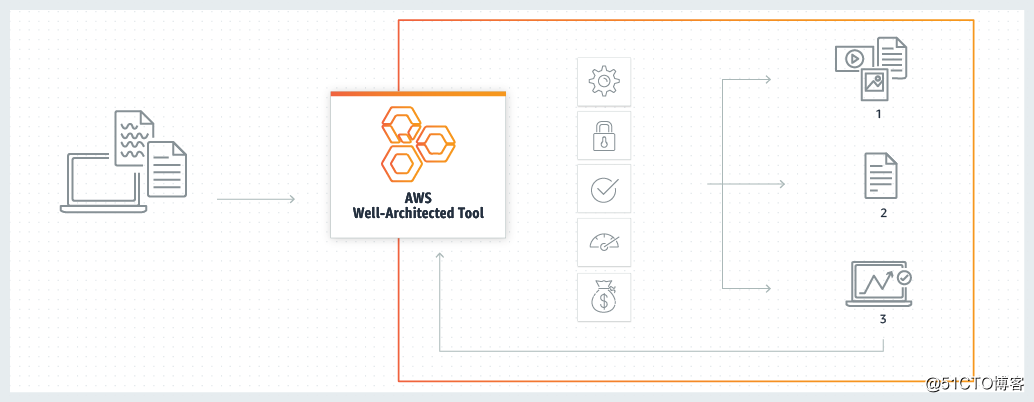
这部分的工作一直都是云托管服务(Managed Service)里专业服务(Professional Service)的重要组成部分。我们在具体的工作中,通常也使用类似的方法给客户提供这五个方面的建议和意见。我记得六七年前AWS已经有过一篇白皮书讲这个,我当年也看过。不曾想到了今天,这篇白皮书已经被扩展成了特定领域的框架设计,动手实验,还提供了一个自动分析的工具能给客户建议,关键还是免费的!这么折腾下去,怕是专业干高端咨询的团队要擦汗了,毕竟他们的吃饭家伙正在被蚕食。
AWS提供了特定行业和领域的架构完善框架白皮书,例如金融服务,分析,机器学习,IoT,HPC,Serverless等等。我个人觉得金融服务这个白皮书写得有点水,故意回避了银行核心系统架构,其他几个技术领域的白皮书还是很专业的。
不仅是AWS,微软也有类似的框架,叫做Microsoft Azure Well-Architected Framework,内容结构几乎完全一样,也是成本优化,卓越运营,性能效率,可靠性,安全性五部分内容,给出了基于Azure的各方面建议。不过微软只提供了一个Review的问卷,让客户自己选择得到相关的建议,跟AWS那个自动分析工具比还是有差距。

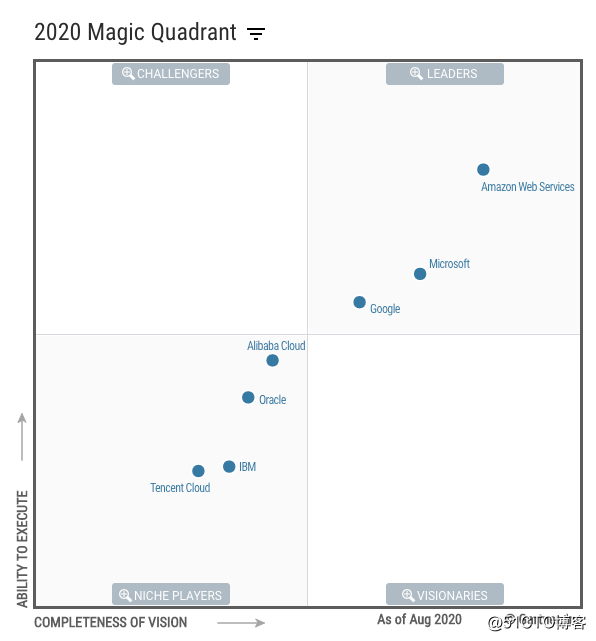
鉴于亚马逊在云计算领域的领先优势,让我来近距离再看一下这个框架里提到的内容。看看他有没有可能成为云计算的架构设计框架的事实标准。毕竟AWS在Gartner今年 9 月1日发布的云基础设施和平台服务魔力象限里排名第一,遥遥领先。
AWS架构晚上框架其实是一个平衡的方法论,在定义里他说得很清楚:在设计架构的时候,我们根据业务的上下文,在5个支柱之中取得平衡。根据商业决策决定工程上的优先级。我们可能因为要优化成本而降低开发环境的可靠性,或者为了关键的业务场景提高可靠性而增加成本。安全和卓越运营比较通用,虽然没有明显的取舍,但是依然对成本有重要的影响。
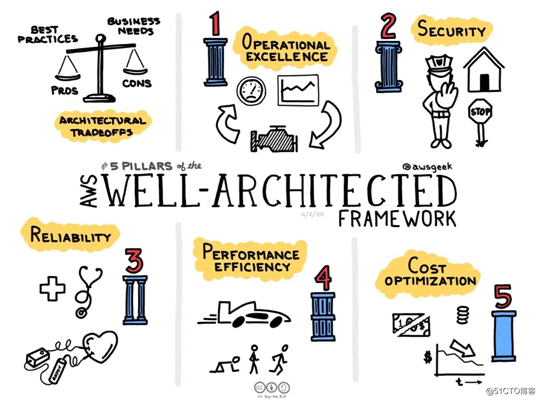
传统IT的环境下我们通常使用中心化的IT架构,基于TOGAF或者Zachman框架设计企业架构(像不像中台的概念?)。而在云上,AWS倾向于把能力分布到不同的团队,而不是用一个中心化的团队(像不像区块链里去中心化的概念?)。这种分布式的方法产生了决策的风险,不过AWS说他们通过实践(practices)和机制(mechanisms)减轻了这种风险,先让各团队满足内部标准,然后逐渐提高标准,推动技术和业务发展。AWS说,这种分布式的方法由亚马逊领导力原则支持,我顿时惊掉了下巴,这个高大上的帽子绝对是政治正确,但是写在一份技术文档里真的合适吗?
插一句,亚麻的领导力原则有14条,包括
顾客至尚(Customer Obsession)
主人翁精神(Ownership)
创新简化(Invent and Simplify)
决策正确(Are Right, A Lot)
好奇求知(Learn and Be Curious)
选贤育能(Hire and Develop the Best)
最高标准(Insist on the Highest Standards)
远见卓识(Think big)
崇尚行动(Bias for Action)
勤俭节约(Frugality)
赢得信任(Earn Trust)
刨根问底(Dive Deep)
敢于谏言 服从大局(Have Backbone; Disagree and Commit)
达成业绩(Deliver Results)

技术架构文档和领导力文化紧密相连,这个和阿里的政委思想政治玩法也是同出一辙。因为有了这个思想武器的指导,所以亚麻的框架也不断改进。不管是新团队,还是现有的团队,都能够在这个框架下满足广大客户日益苛刻的要求。
顺便吐槽一句,这14条领导力的原则真是条条反人性,能全部做到真是太难了。话说回来也确实蛮有道理,比虚无缥缈微言大义的《论语》《道德经》啥的,实操效果好多了。
这个框架的一般设计原则有六个:
停止对容量需求的猜测
以生产规模进行系统测试
通过自动化让架构试验更简单
允许不断演化的架构
利用数据来驱动架构
通过实际演练(Game Day)不断改进
接下来就是对五大支柱进行分析和讨论了。毕竟做一个软件系统就像造房子一样,结构问题会导致楼房倒塌。对五大支柱的分析和设计会帮助我们构建一个稳固有效的系统。这个讲得还是很有道理的,不管是软件系统,还是组织架构的设计,一开始大家都差不多,到了一定规模以后,不好的结构问题迟早会出现,严重的可能会导致系统崩溃。
卓越运营主要包括了对开发和有效运行的支持能力,获得运营的洞见以及持续改进支持流程和过程来获得业务价值。
卓越运营的设计原则包括:
运营即代码
用频繁的,小的和可逆的改变
经常改进运营程序
预期失败
从运营失败中学习
卓越运营有四方面的最佳实践:组织,准备,运营,演进。在这四个部分里,AWS提出了各种需要注意的点和需要回答的问题:
组织(Organization)
OPS 1:如何决定优先级
OPS 2:如何定义组织架构来支持业务产出
OPS 3:组织文化如何支持业务产出
准备(Prepare)
OPS 4:如何设计工作负载以理解它的状态
OPS 5:如何降低缺陷,简化修复,并改进生产流程
OPS 6:如何减轻部署风险
OPS 7:如何知道你准备好对工作负载的支持
运营(Operate)
OPS 8:如何理解你的工作负载的健康状态
OPS 9:如何理解运营的健康状态
OPS 10:如何管理工作负载和运营的事件
演进(Evolve)
OPS 11:如何演进运营

其实卓越运营的核心就是自动化(Automation),运营的错误都是人的问题,自动化越多,错误就越少,内部的流程不断改进可以不断降低运营错误的发生。
安全性包含了利用云技术来提高安全性,保护数据,系统和资产。它的设计原则包括:
实现严格的身份基础
启用可追溯性
在所有层上应用安全
自动化安全最佳实践
保护在传输中的和静态的数据
让人远离数据
为安全事件做好准备
安全的最佳实践分为六个部分:安全,身份和访问管理,侦查,基础设施保护,数据保护,事故响应。
安全(Security)
SEC 1:如何安全地运营工作负载
身份和访问管理(Identity and Access Management)
SEC 2:如何管理人和机器的身份
SEC 3:如何管理人和机器的权限
侦查(Detection)
SEC 4:如何检测和调查安全事件
基础设施保护(Infrastructure Protection)
SEC 5:如何保护网络资源
SEC 6:如何保护计算资源
数据保护(Data Protection)
SEC 7:如何对数据进行分类
SEC 8:如何保护静态数据
SEC 9:如何保护传输中的数据
事故响应(Incident Response)
SEC 10:你如何预测、应对和从事故中恢复
安全里最关键的设计要点叫做Zero Trust,就是零信任,所有的这些问题都是在问这个零信任的问题怎么解决。
可靠性谈的是工作负载如何按照预期的方式正确地,持续地运行。我们需要对工作负载全生命周期进行运营和测试。它的设计原则包括:
自动从故障中恢复
测试恢复流程
通过水平扩展增加聚合工作负载的可用性
停止猜测容量
自动化管理变更
可靠性的最佳实践有四个部分,分别是基础,工作负载架构,变更管理,故障管理。
基础(Foundations)
REL 1:如何管理服务配额和限制
REL 2:如何规划网络拓扑
工作负载架构(Workload Architecture)
REL 3:如何设计工作负载服务架构(面向服务架构SOA或者微服务架构)
REL 4:如何在分布式系统中设计交互以防止故障
REL 5:如何在分布式系统中设计交互以减轻或抵御故障?
变更管理(Change Management)
REL 6:如何监控负载资源
REL 7:如何设计工作负载来适应需求变化
REL 8:如何实现变更
故障管理(Failure Management)
REL 9:如何备份数据
REL 10:如何使用故障隔离来保护工作负载
REL 11:如何设计工作负载以抵御组件故障
REL 12:如何测试可靠性
REL 13:如何规划灾难恢复(DR)
在考虑可靠性的时候,我们可以考虑一个叫做爆炸半径(Blast radius)的概念。爆炸半径的意思是是系统发生故障时可能承受的最大影响,要构建可靠的系统,需要最小化任何单个组件的爆炸半径。
性能效率包括了有效使用计算资源来满足系统需求,以及在需求变更和技术演化过程中维持效率。它的设计原则有:
让先进技术平民化
分钟级全球化
使用无服务架构
多做实验
考虑“机械同情”(Mechanical Sympathy)。这里解释一下,Mechanical Sympathy是赛车手Jackie Steward最早说的,然后被Martin Thompson用在了软件设计上。原话是:“You don’t have to be an engineer to be a racing driver, but you do have to have Mechanical Sympathy.” 你不必成为一名工程师才能成为一名赛车手,但你必须有机械同情。编写代码也是一样,你不需要成为一名硬件工程师,但是需要了解底层的运作模式,并在设计软件时考虑到这一点。我们有太多的码农没有打破砂锅问到底的精神,只是随便搭搭积木把功能实现了就好,不知道底层模块的实现方式,出现问题了完全没有办法解决。
好吧,搞技术的码农还是非常有文化的。性能效率的最佳实践包括选择,复查,监控和权衡。
选择(Selection)
PERF 1:如何选择最优性能架构
PERF 2:如何选择计算方案(实例,容器,函数)
PERF 3:如何选择存储方案(对象存储,块存储和文件存储)
PERF 4:如何选择数据库方案
PERF 5:如何配置网络方案
复查(Review)
PERF 6:如何利用新的发布演进工作负载
监控(Monitoring)
PERF 7:如何监控资源以保证他们正常工作
权衡(Tradeoffs)
PERF 8:如何利用权衡改进性能(降低一致性,持久性,空间换时间,延迟)
在考虑性能效率的时候,把服务想成牛,而不是宠物(cattle, not pets)。在传统机房模型下,服务器又贵又经不起折腾,所以我们把他理解成宠物,要很多关爱。而在云的模型下,服务器就是老黄牛,几秒钟就可以创建,完全不需要关爱。
成本优化包括用最低的成本运行系统来交付商业价值,它的设计原则包括:
实现云的财务管理
采用消费模式
衡量总体效率
别再把钱花在毫无差别的重担上
分析并确定支出
成本优化的最佳实践包括:实践云财务管理,支出和使用意识,成本效益的资源,管理需求和供给资源,随时间优化。
实践云财务管理(Practice Cloud Financial Management)
COST 1:如何实现云财务管理
支出和使用意识(Expenditure and usage awareness)
COST 2:如何控制用量
COST 3:如何监控用量和成本
COST 4:如何解除资源使用
成本效益的资源(Cost-effective resources)
COST 5:在选择服务时如何评估成本
COST 6:在选择资源类型、规模和数量时,如何达到成本目标
COST 7:如何使用价格模型降低成本
COST 8:如何规划数据传输费用
管理需求和供给资源(Manage demand and supply resources)
COST 9:如何管理需求和供给资源
随时间优化(Optimize over time)
COST 10:如何评估新服务
在我们考虑云上的成本优化的时候,考虑OpEx而不是CapEx,即考虑运营性支出,而不是资本性支出。云毕竟是租用的生意,需要不断考虑持续的成本。
价值观又来了!
在这个框架下,AWS建议建立持续轻量级的Review流程,用不责备的方法不断进行深度分析,对架构进行改进。通过根原因分析(Root Cause Analysis),在关键的节点和产品发布的时候开始Review。
不断分析提高当然是必须的,也是反人性的,大量的工程师和技术人员是不愿意的,所以还是得通过价值观来推进。在这个技术框架的文章里,它提到了一些新的团队对这种框架设计的抵触可能,例如:
“我们太忙了!”
“我们没有时间对结果做任何事情“
“我们不希望别人知道我们解决方案的秘密”
说得真是挺到位的,我们的一些技术团队在要求提高效率或者横向对比的时候,也会找到类似的借口和理由。我也理解了AWS的员工流失率有点高的原因。刚才提到的AWS领导力原则条条都是反人性,多数人是做不到的,这里也是一样。不过正因为如此,才让AWS成为一家如此成功的伟大公司吧。
这个框架本身是一个云计算架构里很好用的方法论,如果有兴趣的同学还可以去AWS官方网站上找到更详细的内容。作为北美富士康的亚马逊在技术文档里也融入了他的文化主张,就更有意思了。从这个角度上来说,这个框架成为业界标准似乎是没可能了。
对于数字化转型而言,数字化技术并不是转型的关键,文化才是。在这点上亚马逊做得越来越有趣。当然,优秀的公司都是能找到一群认可公司价值观的人一起把事情做好的,亚马逊是这样,特斯拉是这样,连阿里巴巴和华为也是这样,凡事搞到最后,其实都是人事。
标签:也会 standards 推广 富士 workload 咨询 基础 今天 exp
原文地址:https://blog.51cto.com/14921703/2532951