标签:系统 而在 地方 合作 时间 数据集 完全 质量 成熟
https://mp.weixin.qq.com/s/Ct0Vhwcc1maN1VV_pdAQUgBy 超神经
内容概述:方言是语音识别技术发展中必须要迈过去的坎儿,那么如何让模型能够听懂和理解方言呢?使用优质的数据集是一种的方法,本文将介绍一个经典的方言录音数据集 TIMIT。
关键词:语音识别 方言识别 数据集随着科技的成熟,语音识别技术已经走进生活的方方方面,但在方言识别和处理上却还是略显吃力。
就拿美式英语来说,虽然书面表达接近标准化,但不同的地区,由于方言,口音,俚语等存在,发音的方式方法、词汇的拼法千差万别。
这导致语音系统在识别方言时会出现差错,甚至会闹出笑话。

方言,让智能音箱不懂你
2018 年,华盛顿邮报,Globalme 和 Pulse Labs (语音研究公司)合作,对主流的智能音箱做了一份测试,探究方言、口音对语音识别系统的影响。
美国 20 多个城市、超 100 名参与者进行了测试,他们发出的数千条方言语音命令,被主流智能音响识别时,识别结果存在着显著的差异。
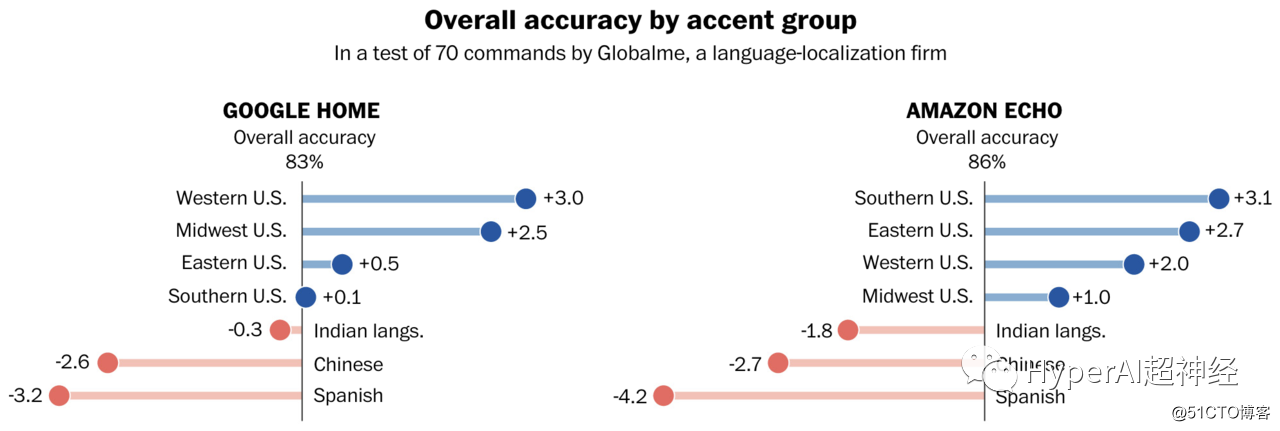
不同口音的识别准确率区别很大
其中,Google Home 识别西岸口音的准确率,比识别南方口音高 3%;而亚马逊的语音助手 Alexa,识别中西部口音的准确率,要比东岸口音低 2%。
也就是说,智能音箱并不能对各地方言进行通吃。而最严重的问题,发生在识别非本土口音时。
对于移民群体的发音,Google Home 或者 Amazon Echo 的英语识别,准确率都特别低。其中对于拉丁裔和华裔群体,用 Alexa 识别的内容,不准确率达到了 30%。
想要解决这个问题,就需要让 AI 听懂不同方言的语音,从而在交互中分辨出真要表达的语句。
对于这个困境,谷歌和亚马逊都曾提到了基于数据的解决方案。
亚马逊在一份声明中称,随着使用不同方言的人和 Alexa 进行交流,它的理解能力会得到改善。」而谷歌表示,「在扩大多样化数据集的同时,将继续提高 Google Home 的识别能力。」
某种层面来将,语音识别中的方言、口音识别问题,可归咎于数据不足。语料库的质量越高,语言模型越多种多样,理论上来说语音识别系统的准确率越高。
美国英语口音分布地图
所以要解决方言识别的,有效的一种方式是拥有优质的数据集。
而 TIMIT 方言录音数据集,就是早期的数据科学家们,意识到此类问题后构建而来,它也很好地背负起了训练方言识别的使命。
TIMIT 方言录音数据集,于 1993 年推出,涵盖了 8 种主要美国英语方言共 6300 个录音片段,旨在帮助语音系统中方言识别的开发和评估。
TIMIT 方言录音数据集
包含数量:6300 个方言录音片段
数据格式:wav\txt\wrd\phn
采样方式:16 KHz 16 bit
数据大小:419.82 MB
发布时间:1993 年
包含内容:录音片段、句子、单词、因素内容
下载地址:https://hyper.ai/datasets/5684
该数据集由麻省理工学院、SRI 国际和德州仪器公司合作而得到,具有 630 位采集者,每人提供 10 个语音丰富的句子录音。
因为指定了测试和培训集,数据集很好地平衡了语音和方言的覆盖范围。
训练集和测试集的分配
其内容包括一些与话语句子相关的文件,除了语音波形文件(.wav)外,还包括对应的句子内容(.txt),经过时间对齐(time-aligned)的单词内容(.wrd),经过时间对齐(time-aligned)的音素内容(.phn)三种类型的文件。
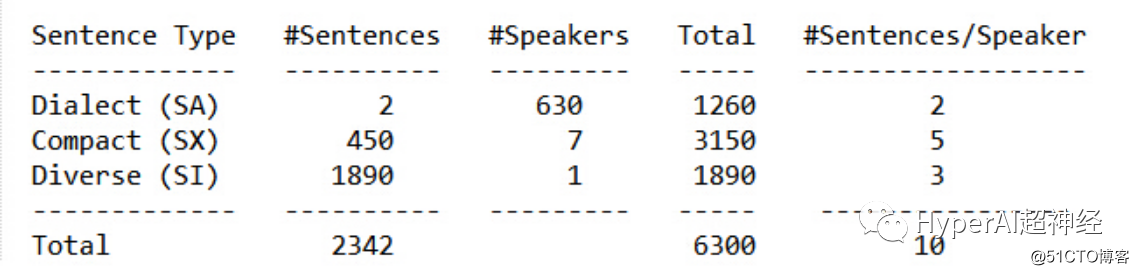
数据集包含多种句子类型
作为语音识别领域的经典数据集,TIMIT 方言录音数据集被广泛使用,在谷歌学术列表中,有多篇高质量的论文引用,由此推动了语音识别实验的进展。
二十多年后,该数据集仍然被广泛使用在语音识别的研究之中。
由于数据集每个句子都在音素级别上进行了手动标记,同时提供了说话人的编号,性别,方言种类等多种信息,在今日仍然不显落后。
另外数据集很小,能在短时间内完成模型训练,同时又足以展示出系统的性能。
虽然数据并不能完全解决语音识别中的方言和口音问题,但拥有更好的方言数据集,将是破解这个问题的关键一步。
—— 完 ——
扫描二维码,加入讨论群
获得更多优质数据集
了解人工智能落地应用
关注顶会&论文
回复「读者」了解更多
更多精彩内容(点击图片阅读)
标签:系统 而在 地方 合作 时间 数据集 完全 质量 成熟
原文地址:https://blog.51cto.com/14929242/2533378