标签:框架 etc hosts java 数据包 code 资源管理器 脚本 存储位置
一、大数据
大数据的特性
(一)大体量,可从数百TB,PB,EB
(二)多样性,大数据包括各种格式和形态的数据
(三)时效性,很多大数据需要在一定的时间限度下得到及时处理
(四)准确性,处理的结果一定要准备性
(五)大价值,大数据包含很多的深度的价值,大数据分析挖掘和利用将带来巨大的商业价值
二、Hadoop
使用java开发的是软件平台
(一)三大核心组件
1. HDFS,分布式文件系统(ceph差不多)Client交互NameNode数据存在那台DataNode上,Client交互把数据存在指定的DataNode上,DataNode会向NameNode返回数据存放的路径,NameNode在 FSimage中记录。
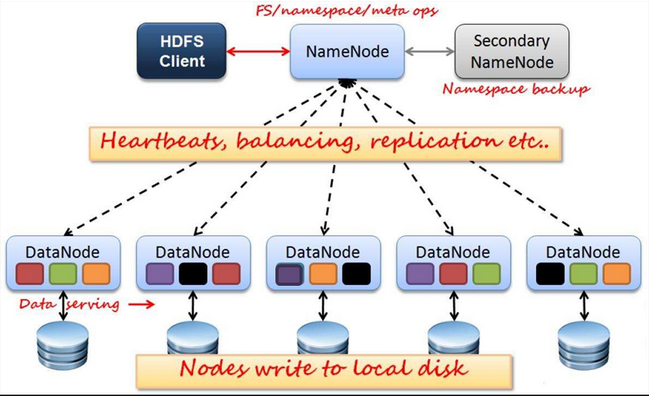
4个角色
(1)NameNode
Master节点,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理所有客户端请求
NameNode把名称空间和数据块映射信息存在 Fsimage
(2) Secondary NameNode
- 定期合并 Fsimage和 Fsedits推送给NameNode
Fsedits(文件变更日志,把每次修改的数据都以补丁样式修改,取数据的时候先取出整体的在打补丁)
- 紧急情况下,可辅助恢复NameNode
但是 Secondary NameNode 并非NameNode的热备
(3)DataNode
- 数据存储节点,存储实际的数据
- 汇报存储信息给NameNode
(4)Client
- 切分文件(切分每块128M 每块可以为多副本)
- 访问HDFS
- 与NameNode交互,获取文件的位置信息(切分数据存在什么地方有NameNode决定)
- 与DataNode交互,读取和写入数据(NameNode决定存储位置Client把数据写入DataNode中)
在读数据的时候Client交互NameNode获取文件位置,再从DataNode中读取文件(和写入文件一样)
2. YARN,集群资源管理系统
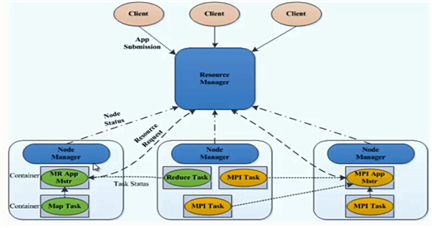
角色
(1)ResourceManager(重要)
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManage
- 资源分配预调度
(2)NodeManager(重要)
- 单个节点上的资源管理
- 处理来自ResourceManage的命令
- 处理来自ApplicationMaster的命令
(3)ApplicationMaster
- 数据切分
- 为应用程序申请资源,并分配给内部任务
- 任务监控与容错
(4)Container
- 对任务运行环境的抽象,封装了CPU、内存等
- 多为资源及环境变量、启动命令等任务运行相关的信息资源分与调度
(5)Client
- 用户与Yarn交互的客户端程序
- 提交应用程序、监控应用程序状态,杀死应用程序等
Yarn的核心思想
将JobTracker和TaskTracker 进行隔离,他有下面积大构成组件
- ResourceManager一个全局的资源管理器
- NodeManager每个节点代理
- ApplicationMaster 代表每个应用
- 每一个ApplicationMaster有多个Container在NodeManager上运行
3. MapReduce,分布式计算框架
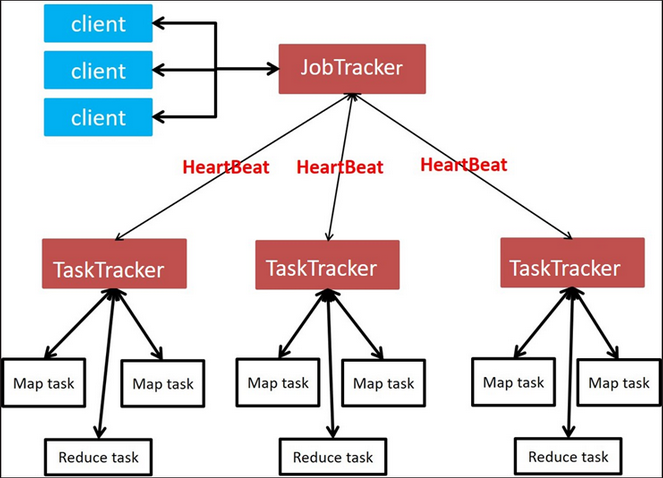
4个角色
(1) JobTracker
- Master节点只有一个
- 管理所有作业、任务的监控、错误处理等
- 将任务分解成一系列任务,并分派给TaskTracker
(2)TaskTracker
- Slave节点,一般为多台
- 运行Map Task 和 Reduce Task
- 并与JobTracker交互,汇报任务状态
(3)Map Task
解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入本地磁盘
- 如果为map-only作业 直接写入HDFS中
(4)Reducer Task
从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的Reduce函数执行
部署有三种模式(伪分布和完全分布的区别 伪分布就是把所有组件放在一台机器上 完全分布就是把组件放在各个机器上 分开放)
(1)单机
(2)伪分布
(3)完全分布
(二)安装单机
1. 单机
(1)安装
yum -y install java-1.8.0-openjdk-devel
(2)https://hadoop.apache.org 下载软件 是个tar包 java写的不需要编译放在那个目录下就安装在那个目录下
安装完之后需要声明 java环境还有装在哪个目录下(Hadoop的配置文件/etc/hadoop/hadoop-env.sh)

查看java安装在哪个目录 rpm -ql java-1.8.0-openjdk
如果不声明的话敲下面命令 会报错

(3)测试(那个词汇 出现的频率最高)
主机名必须要ping通

在结果目录中会有两个文件 一个是结果文件 一个是 是否成功的文件(是成功的话 _SUCCESS)
workcount 这个jar脚本中 其中一个算法里面还有 grep、jion、sort等等
(三)完全分布式
1. 搭建HDFS(/etc/hosts 文件中绑定主机名)
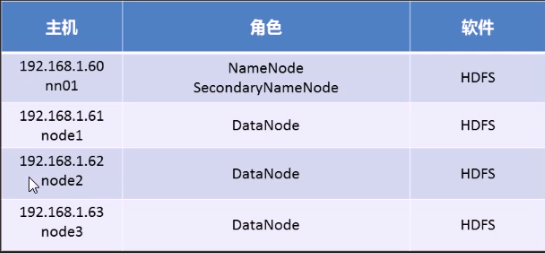
2. 基础环境准备
(1)禁用SElinux
(2)禁用firewalld
(3)安装java-1.8.0-opnejdk-devel
(4)关闭 ssh yes检测 (/etc/ssh/ssh_config中 StricHostKeyChecking 这行改为no)

如果是注释的不用 取消注释 复制 粘贴到 Host * 下面
(5)配置免密钥登录(给所有主机 传送密钥,包括本机)
ssh-keygen -f /root/.ssh/id_rsa -N ‘‘
ssh-copy-id 主机ip
3. 配置 (地址 http://hadoop.apache.org/docs 按照安装的Hadoop的版本 选择文档)
(1) 第一个配置文件 core-site.xml (Hadoop核心配置文件)
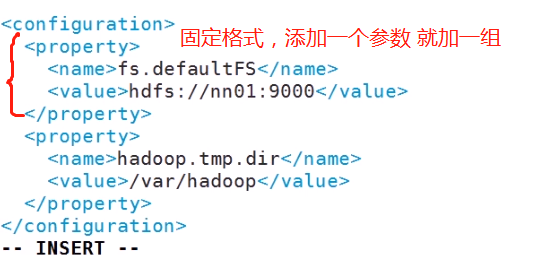
第一个表示 是用什么文件系统存储数据 (nn01 是NameNode的主机名)
第二个是 Hadoop的数据存储目录(NameNode和DateNode 一样都是这个目录)
(2) 配置 HDFS文件hdfs-site.xml
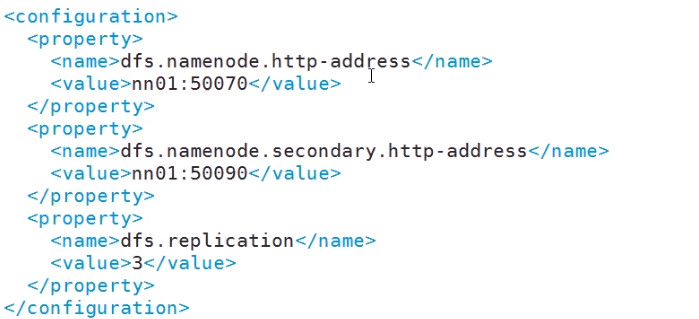
第一个参数 指定 NameNode的主机
第二个参数 指定NameNode.Secondary的主机
第三个参数 副本数是多少
(3)第三个配置文件 Slaves,声明DateNode主机 (默认的localhost 删除了)

(4)把Hadoop的文件夹 同步到 其他HDFS主机上(HDFS的配置都一样的 配置一台 把配置文件传给其他主机)
(5) 格式化
在NameNode上创建 /var/hadoop 文件夹
在NameNode上执行格式化操作
./bin/hdfs namenode -format
启动集群(启动之后 会在Hadoop配置文件下自动创建一个 logs 文件)
./sbin/start-dfs.sh
(6)验证
在所有的主机上敲 jps 这个命令 如果 角色都有说明 启动成功
在NameNode上敲 .bin/hdfs dfsadmin -report 查看集群信息,成功的话在显示的虚线下面会有每个DateNode的信息
4. 安装Yarn/MapReduce
在我们机器不是很充足的时候可以吧不同软件放在同一个机器上,放在同一台机器上的软件要避免资源冲突
(1)没有MapReduce配置文件 在Hadoop配置文件下

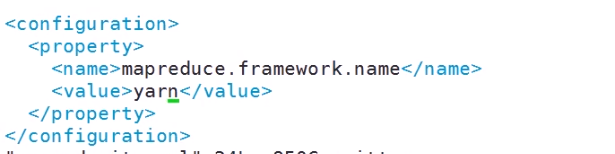
参数是 谁来管理 MapReduce 默认是 local 咱们使用yarn管理
(2)配置Yarn文件

第一个参数指定 ResourceManager主机
第二个参数指定 什么运算框架 咱们是使用的MapReduce
(3) 同步配置文件到其他Yarn主机
启动Yarn
./sbin/start-yarn.sh
(4)检测
jps 查看角色
./bin/yarn node -list 能看到下面yarn节点就说明配置成功
二、使用hadoop
和shell命令 差不多./bin/hadoop fs -ls / 需要在 命令前加上 ./bin/hadoop fs -后面跟shell
在shell中 touch 是创建 文件的 Hadoop中 touchz 加一个z
由于上面配置文件中定义 存储的位置是 HDFS 我们创建的文件/文件夹 都在 HDFS://nn01:9000/的 根目录下
从本地上传到文件系统中 ./bin/hadoop fs -put *.txt /aaa
从文件系统中到本地下载 ./bin/hadoop fs -get /aaa
(1)分析数据测试
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /aaa /bbb
我们也可以直接分析 本地的文件 把 /aaa 换成 file:///本地文件下 (/aaa的全写是 hdfs://nn01:9000/aaa 是Hadoop主配置文件中我们定义的 default下面的values)
标签:框架 etc hosts java 数据包 code 资源管理器 脚本 存储位置
原文地址:https://www.cnblogs.com/zshBlos/p/13646847.html