标签:article 不可 image pre 下载 python 技术 ons size
什么是scrapy框架:
scrapy是一个基于Twisted异步框架的爬虫框架,scrapy具有异步性,效率高。
scrapy是用于爬取结构化数据
适合构建大型爬虫应用。
scrapy安装配置
lxml, wheel, Twisted, pywin32, scrapy
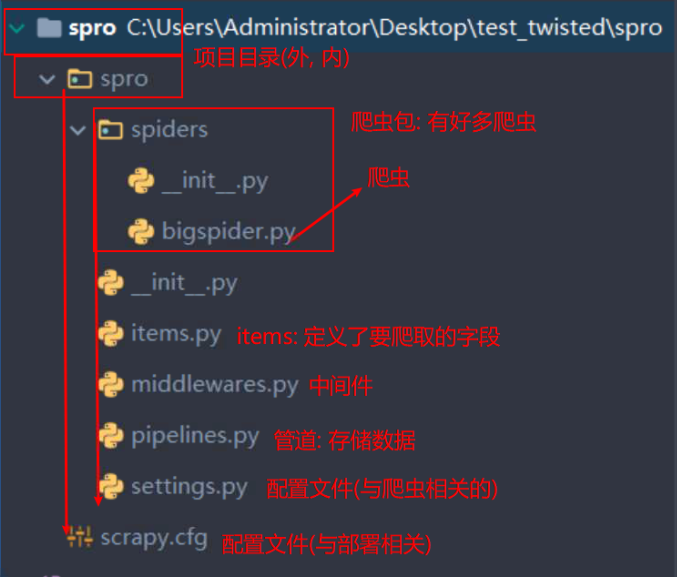
项目的常见与运行
创建:
1. scrapy startproject 文件名
2.cd 文件名
3.scrapy genspider 目录名 域名
运行:
scrapy crawl 目录名
scrapy crawl 目录名 --nolog 加个--nolog取消日志 但不会提示报错吗
爬虫:
# 爬虫类
# scrapy.Spider爬虫类, 最牛逼的一个爬虫类
class ZetaotaigouSpider(scrapy.Spider):
# name为爬虫名
# name唯一的标识了爬虫, 运行爬虫的时候会用的到, 所以爬虫名必须有, 且不能重复
# 有时候运行并不需要爬虫名, 但是爬虫名不可以删掉, 删掉了就不是爬虫类
name = ‘zetaotaigou‘
# allow: 允许, domain: 域名
# allowed_domains限定爬虫爬取的范围的.
# allowed_domains = [‘baidu.com‘]
# start_urls: 起始url
# 项目一启动, 会自动的对start_urls中的url发起请求
start_urls = [‘http://www.kekenet.com/Article/15577/‘]
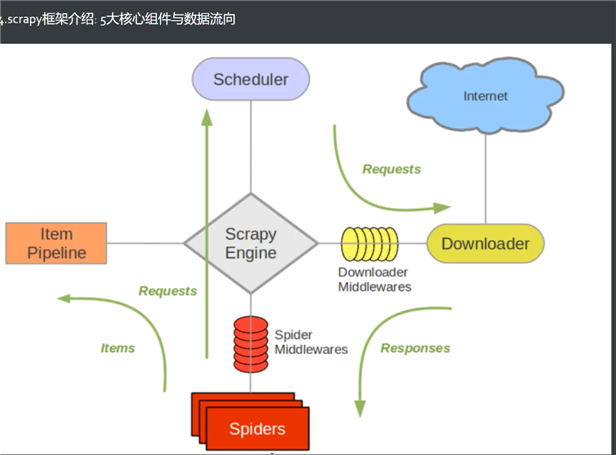
五大核心组件与数据流向
组件: 爬虫 引擎 调度器 下载器 管道
数据流向:
爬虫 --(1.请求) --> 引擎 -- (2.请求) --> 调度器 --(3.请求) -->引擎 -- (4.请求) -->下载器 -- (5.请求) -->服务器-- (6.响应) -->下载器 -- (7.响应) -->引擎 -- (8.响应) --> 爬虫 --(9.item) -->管道
scrapy框架中的数据解析
response.xpath("xpath表达式")
response.css("css选择器")
标签:article 不可 image pre 下载 python 技术 ons size
原文地址:https://www.cnblogs.com/gaodenghan/p/13679600.html