标签:etc yar trap htm prope print you last bootstra
Hadoop HA 集群搭建Hadoop 完全分布式环境搭建集群规划集群部署前提Hadoop伪分布式环境搭建配置IP映射安装 Java 与 Hadoop配置 Hadoop配置 MapReduce 与 YARN集群配置配置基本参数配置 SSH 免密登录格式化 HDFS启动 Hadoop 服务测试测试访问Hadoop HA 高可用高可用简介HDFS 高可用** **故障转移(fail-over)YARN高可用分布式协调服务ZooKeeperZookeeper 的架构ZooKeeper 的特点HA 集群规划ZooKeeper 的安装HDFS HA 配置在 ZooKeeper 中初始化 HA 状态Hadoop HA 启动YARN HA 配置
使用 Hadoop2.7.3和 jdk1.8 搭建3个节点的完全分布式一个namenode,3个datanode,集群规划如下:
| 主机名 | IP地址 | 服务进程 |
|---|---|---|
node01 |
192.168.22.101 |
namenode datanode nodemanager secondarynamenode resourcemanager |
node02 |
192.168.22.102 |
datanode nodemanager |
node03 |
192.168.22.103 |
datanode nodemanager |
克隆模板Linux节点需要做如下配置:
配置网络环境,修改网卡配置文件 ( /etc/sysconfig/network-scripts/ifcfg-ens32 ) IPADDR 属性
修改主机名 ( hostnamectl set-hostname node01 | /etc/hostname)
配置映射地址 ( /etc/``hosts )
关闭防火墙 ( systemctl stop firewalld systemctl disable firewalld )
关闭Linux 安全子系统 SELinux ( /etc/sysconfig/selinux | /etc/selinux/config )
重启 Linux 系统 ( reboot ),并使用 MobaXterm 连接测试,使用 ping www.baidu.com 测试网络是否联通
配置主机的 hosts 映射 ( C:\Windows\System32\drivers\etc\hosts )
# 修改 网卡配置文件
$ vi /etc/sysconfig/network-scripts/ifcfg-ens32
TYPE=Ethernet
BOOTPROTO=static
NAME=ens32
DEVICE=ens32
ONBOOT=yes
IPADDR=192.168.22.101
NETMASK=255.255.255.0
GATEWAY=192.168.22.2
DNS1=8.8.8.8
?
# 修改主机名
$ hostnamectl set-hostname node01
?
# 配置映射地址
$ echo 192.168.22.101 node01 > /etc/hosts
?
# 关闭防火墙
$ systemctl stop firewalld
$ systemctl disable firewalld
?
# 关闭 linux 安全子系统
$ vi /etc/selinux/config
SELINUX=disabled
?
# 重启系统
$ reboot
在 node01 节点搭建伪分布式环境,后续两个节点就在该基础上进行克隆复制。
这里就直接配置整个集群的IP映射,后面直接克隆就好了,不用后面每个都改
[root@node01 ~]# echo -e ‘192.168.242.102 node02 \n192.168.242.103 node03‘ > /etc/hosts
# 解压 tar 包到当前目录
[root@node01 local]# tar -zxvf jdk-8u111-linux-x64.tar.gz
[root@node01 local]# tar -zxvf hadoop-2.7.3.tar.gz
?
#设置软连接方便后续配置
[root@node01 local]# ln -s jdk1.8.0_111/ jdk
[root@node01 local]# ln -s hadoop-2.7.3 hadoop
?
# 配置 jdk 和 hadoop 环境变量
[root@node01 local]# vim + /etc/profile
# JAVA_HOME
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
?
# HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
?
# 重新加载 环境变量文件,使配置生效
[root@node01 local]# source /etc/profile
?
# 测试配置是否OK
[root@node01 local]# java -version
java version "1.8.0_111"
?
[root@node01 local]# hadoop version
Hadoop 2.7.3
修改 hadoop-env.sh 设置 Hadoop 环境对应的 JDK
[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
修改 core-site.xml 配置文件,可以使用 NotePad++ 进行配置
[root@node01 local]# vim + /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<!--NameNode的访问URI,也可以写为IP,8020为默认端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
?
<!--临时数据目录,用来存放数据,格式化时会自动生成-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
</configuration>
修改 hdfs-site.xml 配置文件
[root@node01 local]# vim + /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<!--Block的副本数,伪分布式要改为1-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
?
<!--NameNode 元数据存放地址-->
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
?
<!--DataNode 副本存放地址-->
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
?
<!--HDFS 临时存放地址-->
<property>
<name>dfs.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
?
<!--配置有secondarynamenode的主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
</configuration>
修改 yarn-env.sh、mapred-env.sh 添加 JAVA_HOME 配置
[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/local/jdk
?
[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/mapred-env.sh
export JAVA_HOME=/usr/local/jdk
mapred-site.xml ,把 mapred-sit.xml.template 复制一份,修改为 mapred-site.xml 并添加如下信息。
[root@node01 local]# cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<!---计算框架的运行平台配置 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml 添加相应配置
[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!---YARN 的节点辅助服务配置 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<!--默认是0.0.0.0 本地访问-->
<value>node01</value>
</property>
</configuration>
在 slaves 配置文件中 添加 主机名,它指定了 DataNode 和 NodeManager所在的机器。
# 替换 slaves 中的节点名称 [root@node01 hadoop]# echo -e "node01\nnode02\nnode03" > slaves
使用 VMware 工具克隆两个上述配置好的节点,用于集群配置,注意:克隆需要先把节点关机
[root@node01 local]# poweroff
打开 VMware ,在关机状态,选中要克隆的节点,右键--> 管理 --> 克隆 , 或者直接找到要克隆的节点所在磁盘文件夹,直接复制两个也可以。
克隆完毕后,等待三台机器启动完毕,如下所示:

修改复制出来的 node02 和 node03 的 IP地址以及主机名,然后重启
# 修改 IP 地址 [root@node03 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens32 IPADDR=192.168.22.103 # 修改主机名 [root@node03 ~]# hostnamectl set-hostname node03 # 重启 [root@node03 ~]# reboot
使用
MobaXterm进行连接测试配置是否 OK
在每个节点上都需要生成 SSH 免密登录的密钥对。输入命令 ssh-keygen ,然后 4 个回车即可。
可以使用
MobaXterm的会话全选功能,直接操作 3 个节点。
[root@node01 ~]# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory ‘/root/.ssh‘. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:NntmNW1wpOtDSRSoq1RQPPx5PgPmyNggZ1bmcAm+dyA root@node01 The key‘s randomart image is: +---[RSA 2048]----+ | .=.. .o.. | | .o O .. o | | EB.+ .+ . | | . =o+.=..* | | =.*S=.+* o | | oo=+.++o | | . .. + oo | | . + . | | | +----[SHA256]-----+ [root@node01 ~]#
把每一个节点上的公钥文件发送到所有节点(包括自己),注意:每一条命令都需要在3个节点中执行
[root@node01 ~]# ssh-copy-id node01 [root@node01 ~]# ssh-copy-id node02 [root@node01 ~]# ssh-copy-id node03
使用 ssh 命令验证是否配置成功
[root@node01 ~]# ssh node01 Last login: Sun Aug 23 16:37:58 2020 from 192.168.22.1 [root@node01 ~]# exit 登出 Connection to node01 closed. [root@node01 ~]# ssh node02 Last login: Sun Aug 23 16:42:39 2020 from 192.168.22.1 [root@node02 ~]# exit 登出 Connection to node02 closed. [root@node01 ~]# ssh node03 Last login: Sun Aug 23 16:50:09 2020 from 192.168.22.1 [root@node03 ~]# exit 登出
在主节点 **node01** 上运行 HDFS 格式化命令
[root@node01 ~]# hdfs namenode -format 20/08/23 17:13:52 INFO common.Storage: Storage directory /usr/local/hadoop-2.7.3/data/namenode has been successfully formatted.
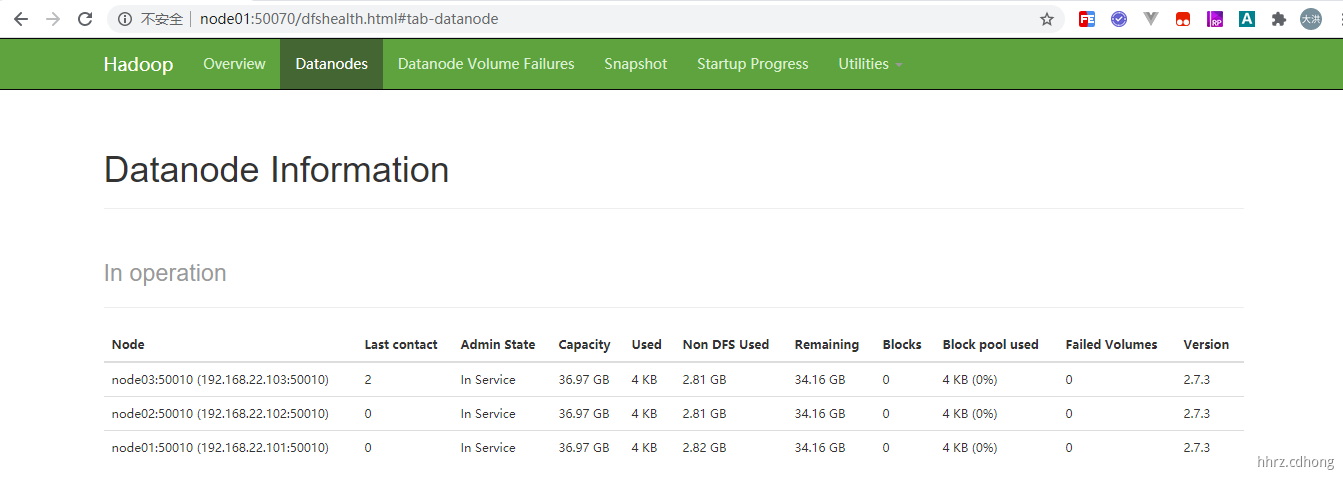
[root@node01 hadoop]# start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [node01] node01: starting namenode, logging to /usr/local/hadoop-2.7.3/logs/hadoop-root-namenode-node01.out node01: starting datanode, logging to /usr/local/hadoop-2.7.3/logs/hadoop-root-datanode-node01.out node03: starting datanode, logging to /usr/local/hadoop-2.7.3/logs/hadoop-root-datanode-node03.out node02: starting datanode, logging to /usr/local/hadoop-2.7.3/logs/hadoop-root-datanode-node02.out Starting secondary namenodes [node01] node01: starting secondarynamenode, logging to /usr/local/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-node01.out starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop-2.7.3/logs/yarn-root-resourcemanager-node01.out node01: starting nodemanager, logging to /usr/local/hadoop-2.7.3/logs/yarn-root-nodemanager-node01.out node02: starting nodemanager, logging to /usr/local/hadoop-2.7.3/logs/yarn-root-nodemanager-node02.out node03: starting nodemanager, logging to /usr/local/hadoop-2.7.3/logs/yarn-root-nodemanager-node03.out [root@node01 hadoop]# jps 3537 Jps 2931 DataNode 3284 ResourceManager 3097 SecondaryNameNode 3385 NodeManager 2827 NameNode [root@node01 hadoop]#
这里使用的是
node01服务名进行访问,需要在本机C:\Windows\System32\drivers\etc\hosts中配置地址映射。
Hadoop 高可用(High Availability)分为
Hadoop 中 HDFS 的高可用指的是同时启动2个NameNode。其中一个处于**工作状态(Active),另一个处于随时待命状态(Standby),外加一个** **Quorum Journal Manager** 日志管理器负责数据同步。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。
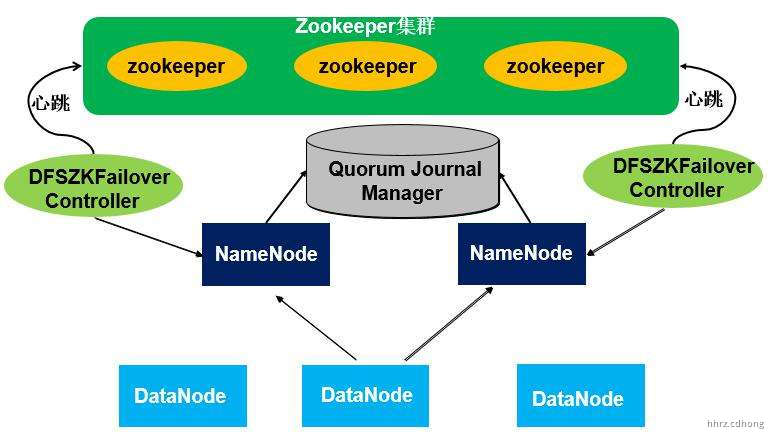
两个 NameNode 为了数据同步,会通过一组称作 JournalNodes 的独立进程进行相互通信。当 Active 状态的 NameNode 命名空间有任何修改时,会告知大部分的 JournalNodes 进程。Standby 状态的 NameNode会读取 JournalNodes 中的变更信息,并且一直监控 Edit Log 的变化,把变化应用于自己的命名空间。Standby可以确保在集群出错时,命名空间状态已经完全同步了。
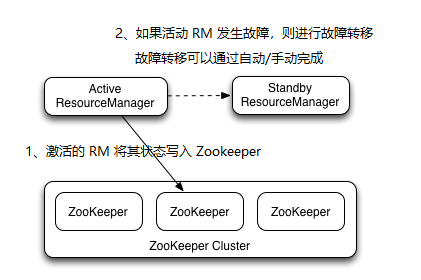
为了检测 NameNode 是否挂掉,HDFS 引入了 Zookeeper,当一个 NameNode 被成功切换为 Active 状态时,它会在 Zookeeper 内部创建一个临时的 ZNode,在这个 ZNode 中将保留当前 Active NameNode 的一些信息,比如主机名等等。当 Active NameNode 出现失败的情况下,监控程序会将 Zookeeper 上对应的临时 ZNode 删除,ZNode 的删除事件会主动触发到下一次的 Active NameNode 的选择。
为了解决故障转移的问题,HDFS 引入了 ZKFC(ZKFailoverController) 组件,它是 HDFS HA 自动切换的核心对象,是 NameNode 节点上启动的 ZKFC 进程,在这个进程内部,运行这 3 个服务对象:
**HealthMonitor**:监控 NameNode 是否不可用或是进入了一个不健康的状态
**ActiveStandbyElector**:控制和监控 ZK 上的节点状态
**ZKFailoverController**:当 HealthMonitor 检测到当前 NameNode 不健康时,ZKFailoverController 会让当前激活的 NameNode 暂时退出 Active 状态;如果 NameNode 恢复状态健康,则会让其参与 NameNode 的选举。
ZooKeeper是一个高可用的分布式数据管理与协调框架,是 Goole Chubby 的开源实现,它使用了一种称为**ZAB**``**(ZooKeeper Atomic Broadcast,ZooKeeper原子广播协议)**的协议作为其数据一致性**的核心算法(主要有 数据写入和 故障恢复(选举)模式)。能够很好地保证分布式环境中数据的一**致性。也是基于这样的特性,使得ZooKeeper成为了解决分布式一致性问题的利器。
ZooKeeper 本身支持单机部署和集群部署, 生产环境建议使用集群部署,因为集群部署不存在单点故障问题, 井且ZooKeeper 建议部署的节点个数为奇数个(有利于仲裁),只有超过一半的机器不可用整个 ZooKeeper 集群才不可用。
Zookeeper集群是一个基于主从复制的高可用集群,每个服务器承担如下两种角色中的一种:
**Leader** 一个Zookeeper集群同一时间只会有一个实际工作的Leader(ZooKeeper 集群的所有机器通过一个Leader 选举过程来选定),它会发起并维护与各Follwer间的心跳。所有的写操作必须要通过Leader完成再由Leader将写操作广播给其它服务器。
Follower 一个Zookeeper集群可能同时存在多个Follower,它会响应Leader的心跳。Follower可直接处理并返回客户端的读请求,同时会将写请求转发给Leader处理,并且负责在Leader处理写请求时对请求进行投票。
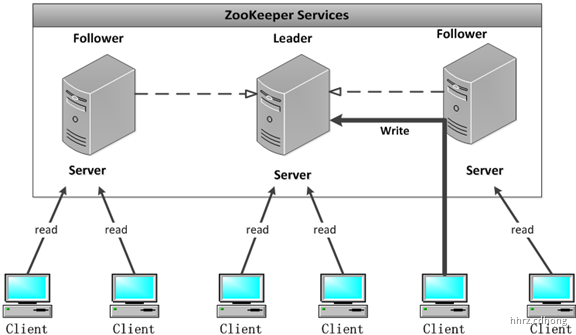
Zookeeper 集群由一组 Server 节点组成,Server 节点的数量一般为奇数,防止投票出现平局的问题。** **
ZooKeeper 工作在集群中,对集群提供分布式协调服务,它提供的分布式协调服务具有如下的特点。
顺序一致性:从同一个客户端发起的事务请求,最终将会严格按照其发起顺序被应用到ZooKeeper 中。
原子性:所有事物请求的处理结果在整个集群中所有机器上的应用情况是一致的, 即:要么整个集群中所有机器都成功应用了某一事务,要么都没有应用,一定不会出现集群中部分机器应用了该事务,另外一部分没有应用的情况。
最终一致性: 无论客户梢连接的是哪个ZooKeeper 服务器,其看到的服务端数据模型都是一致的。
可靠性: 一旦服务端成功地应用了一个事务,并完成对客户端的响应, 那么该事务所引起的服务端状态变更将会一直保留下来,除非有另一个事务又对其进行了改变。
及时性:保证客户端在一定的时间间隔范围内获得服务器的最新状态。
Hadoop HA( High Availability ) 集群的搭建依赖于 Zookeeper,所以选取三台当作 Zookeeper 集群,我们准备 3 台主机,分别是 node01,node02,node03,按照高可用的设计目标:需要保证至少有两个NameNode(一主一备)和两个ResourceManager(一主一备),同时为满足“过半写入则成功”的原则,需要至少要有3个JournalNode节点。这里使用3台主机进行搭建,其中 node01 和 node02 作为 NameNode 和 ResourceManager 的主备切换。
使用 Hadoop2.7.3和 jdk1.8 来完成 HA 搭建,集群规划如下:
| 主机名 | IP地址 | 服务进程 |
|---|---|---|
node01 |
192.168.22.101 |
NameNode(``active``) ResourceManager(``active``) DataNode NodeManager JournalNode Zookeeper |
node02 |
192.168.22.102 |
NameNode(``standby``) ResourceManager(``standby``) DataNode NodeManager JournalNode Zookeeper |
node03 |
192.168.22.103 |
DataNode NodeManager JournalNode Zookeeper |
因为ZooKeeper是用Java开发的,所以先要安装好JDK 1.8(或更新版本)。
在
# 解压到 /usr/local 目录 [root@node01 local]# tar -zxvf zookeeper-3.4.12.tar.gz # 创建文件软连接,简化配置 [root@node01 local]# ln -s zookeeper-3.4.12 zookeeper
配置环境变量
[root@node01 conf]# vim /etc/profile ## ZOOKEEPER_HOME export ZOOKEEPER_HOME=/usr/local/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin [root@node01 conf]# source /etc/profile
修改配置文件
Zookeeper 的核心服务器属性配置文件是zoo.cfg。在主安装目录下的 conf 子目录内,系统为用户准备了一个模板文件 zoo_sample.cfg,我们可以将这个文件复制一份,命名为 zoo.cfg,然后修改配置文件。注意修改服务名称
[root@node01 conf]# cp zoo_sample.cfg zoo.cfg [root@node01 conf]# vim zoo.cfg # 通信心跳的时间间隔 tickTime=2000 # 初始通信时限 initLimit=10 # 同步同学时限 syncLimit=5 # 数据文件目录(保存的数据与日志) dataDir=/usr/local/zookeeper/data dataLogDir=/usr/local/zookeeper/datalog # 客户端连接端口 clientPort=2181 #服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口) server.1=node01:2888:3888 server.2=node02:2888:3888 server.3=node03:2888:3888
在 **/zookeeper/data**下创建一个文件 myid,并添加服务编号(选举票数) 1.
[root@node01 local]# cd /usr/local/zookeeper/data [root@node01 tmp]# vim myid 1
使用 Linux scp 远程 文件拷贝命令,把 zookeeper 程序 分发到 node02 和 node03 的 /usr/local 目录下
[root@node01 local]# scp -r zookeeper root@node02:/usr/local/ [root@node01 local]# scp -r zookeeper root@node03:/usr/local/
修改 node02 节点上的 myid 文件,内容为2 ,修改 node03 节点上的 myid 文件,内容为3。
修改 node02 和 node03 的环境变量
分别在每台机器上运行 zkServer.sh start 命令,运行 zkServer.sh status 命令可以查看服务运行的状态,有一个节点显示:Mode: leader,其他机器显示:Mode: follower。
[root@node03 tmp]# jps 2449 Jps 2378 QuorumPeerMain [root@node02 tmp]# zkServer.sh start ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@node02 tmp]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Mode: leader [root@node03 tmp]# zkServer.sh start ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@node03 tmp]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Mode: follower
修改 hdfs-site.xml 设置 NameNode 集群
<configuration>
<!--完全分布式集群名称-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--集群中 NameNode 节点指定-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1 的 RPC 通信地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<!--nn2 的 RPC 通信地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<!--nn1 的 http 通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<!--nn2 的 http 通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
<!--指定 NameNode 元数据在 JournalNode 上的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<!--访问代理类:client,mycluster,active 配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制,即同一时刻只能有一台服务器对外响应-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 关闭权限检查 -->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!--是否开启自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
修改 core-site.xml 配置文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
<!--指定对外暴露的服务集群地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--声明 JournalNode 服务本地文件系统存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/data/jn</value>
</property>
<!--zookeeper 集群配置-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
</configuration>
分发修改配置到 **node02** 和 **node03** 上
[root@node01 hadoop]# scp core-site.xml hdfs-site.xml root@node02:/usr/local/hadoop/etc/hadoop/ [root@node01 hadoop]# scp core-site.xml hdfs-site.xml root@node03:/usr/local/hadoop/etc/hadoop/
ZooKeeper 中初始化 HA 状态先关闭所有的
NameNode和DataNode
# 停止所有服务节点 [root@node01 hadoop]# stop-all.sh # 删除三个节点上的 data , logs 文件夹 [root@node01 hadoop]# rm -rf data/ logs/ # 先启动3个节点上的 Zookeeper [root@node01 hadoop]# zkServer.sh start # 在ZooKeeper中初始化所需的状态。可以通过一个NameNode主机运行以下命令来执行此操作。 # 先启动三个节点的 journalnode [root@node01 hadoop]# hadoop-daemons.sh start journalnode # 初始化 HA 在 Zookeeper 中的状态,NameNode启动的时候进行节点注册 [root@node01 hadoop]# hdfs zkfc -formatZK 20/09/06 21:39:17 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
# 在[nn1]上,格式化 HDFS,并启动 NameNode [root@node01 hadoop]# hdfs namenode -format [root@node01 hadoop]# hadoop-daemon.sh start namenode # 在[nn2]上,同步 nn1 的元数据信息,并启动 NameNode [root@node02 hadoop]# hdfs namenode -bootstrapStandby [root@node02 hadoop]# hadoop-daemon.sh start namenode # 启动所有 datanode # [root@node01 hadoop]# hadoop-daemons.sh start datanode # 在[nn1,nn2] 上启动 zkfc 守护进程 # [root@node01 hadoop]# hadoop-daemon.sh start zkfc # [root@node02 hadoop]# hadoop-daemon.sh start zkfc # 启动所有其他服务 [root@node01 hadoop]# start-dfs.sh
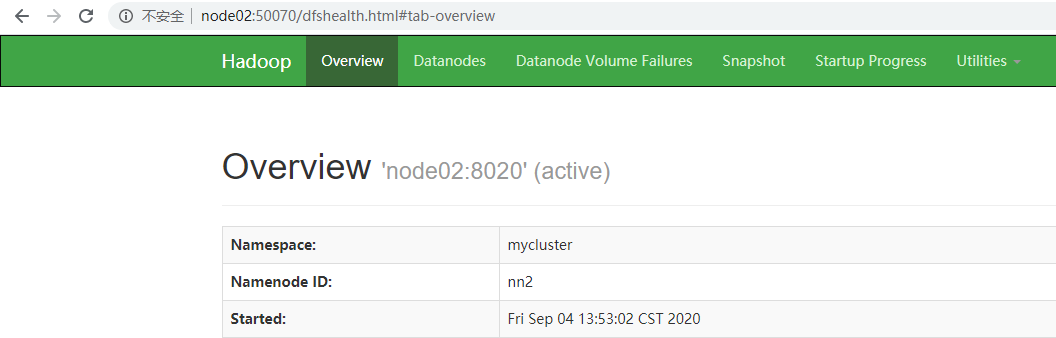
浏览器查看服务情况
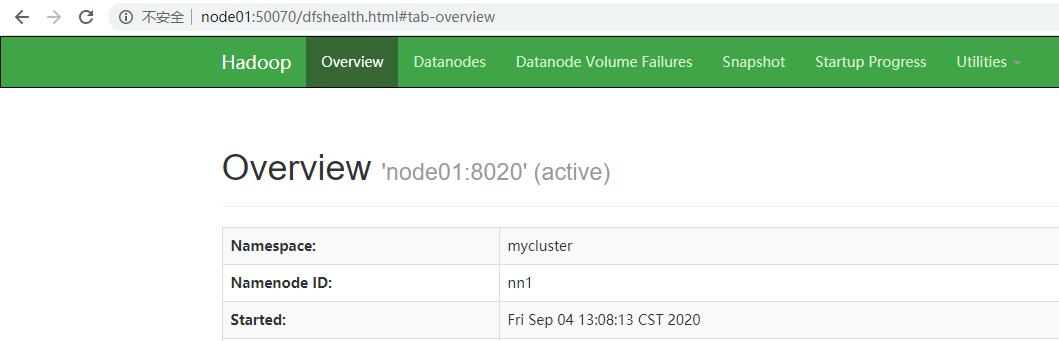
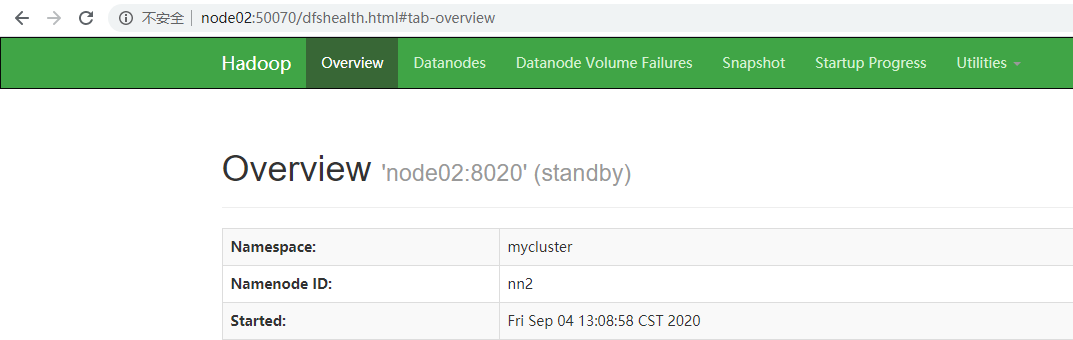
制造故障,查看是否自动转移激活
# 杀死 namenode 进程 [root@node01 hadoop]# kill -9 5909 # 重新启动 namenode ,因为 zookeeper 选举需要3个节点 [root@node01 hadoop]# hadoop-daemon.sh start namenode
yarn-site.xml 添加相应配置
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node01</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node02</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>node01:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node02:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>node01:2181,node02:2181,node03:2181</value> </property> <!--启用RM自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--配置状态存储以保留RM状态--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property>
使用 scp 把 yarn-site.xml 文件分发到 node02 和 node03 中
[root@node01 hadoop]# scp yarn-site.xml root@node02:/usr/local/hadoop/etc/hadoop/ yarn-site.xml 100% 1935 1.0MB/s 00:00
启动 YARN 服务
# 全部启动,只会启动当前节点的 resourcemanager [root@node01 hadoop]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop-2.7.3/logs/yarn-root-resourcemanager-node01.out node03: starting nodemanager, logging to /usr/local/hadoop-2.7.3/logs/yarn-root-nodemanager-node03.out node02: starting nodemanager, logging to /usr/local/hadoop-2.7.3/logs/yarn-root-nodemanager-node02.out node01: starting nodemanager, logging to /usr/local/hadoop-2.7.3/logs/yarn-root-nodemanager-node01.out # 单独启动Node02 的 resourcemanager [root@node02 hadoop]# yarn-daemon.sh start resourcemanager
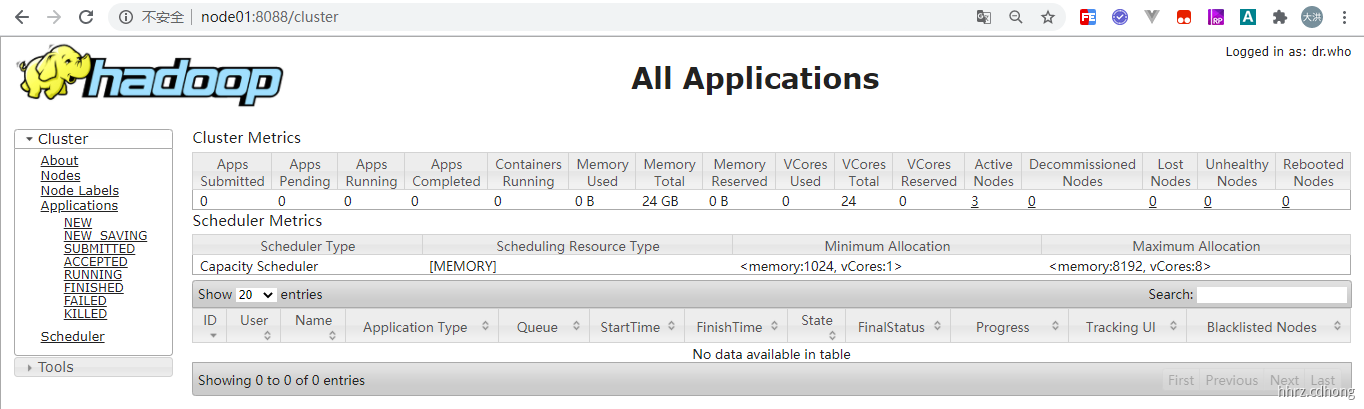
测试 8088 端口
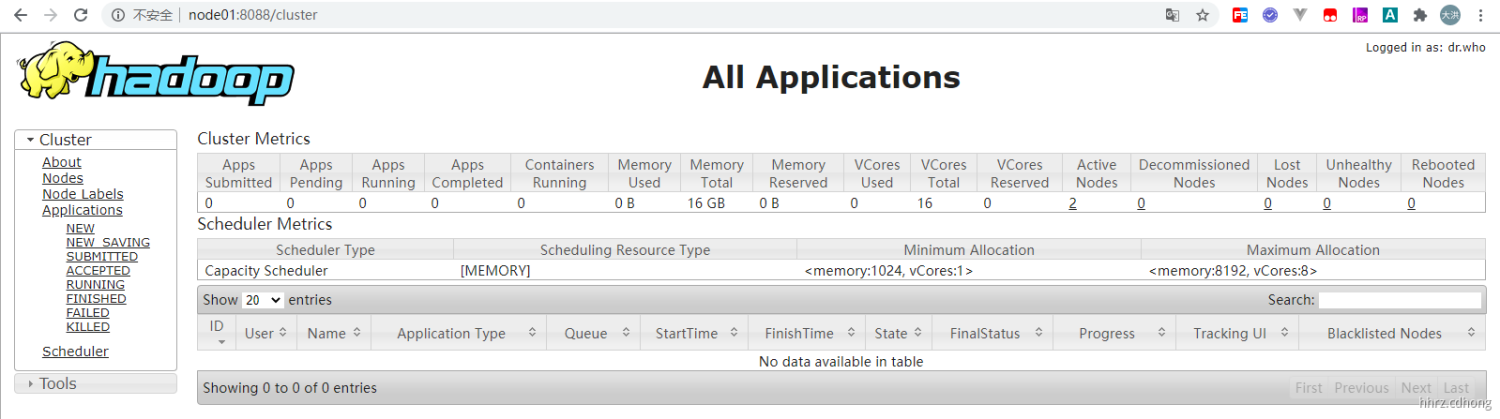
这里不管你输入的是
node01还是node02它会自动调整到activeResourceManager
标签:etc yar trap htm prope print you last bootstra
原文地址:https://www.cnblogs.com/shijingwen/p/13682042.html