标签:场景 book 投影 影视 自己 想象力 完成 开发 吸引
https://mp.weixin.qq.com/s/RTwhin4Bs8ShAA0iMEghlgBy 超神经
场景描述:近日,《三体》动画版的正式预告在 B 站放出,并宣布最终成片将于 2021 年推出,短短 3 分钟的视频吸引了数百万人的目光。这一次,我们要等多久能看到《三体》?
关键词:《三体》 预告片 动画制作 最近,《三体》动画版的首支正式 PV(Promotion Video 宣传概念片),在 B 站发布,视频一经放出,就得到了超高的人气和大量的点击,截止目前,这条视频在 B 站上已有近千万次播放。
《三体》动画首支正式 PV
《三体》小说最早在 2006 开始于《科幻世界》连载,因为其精彩的故事,高远的立意,恢弘的主题,很快就成为了万人追捧的科幻神作。
此后三部曲陆续发布单行本,畅销海内外,连扎克伯格、奥巴马都对其推崇备至,在 2015 年更是收获了科幻界的最高奖项雨果奖,也成为近代在全球影响力最大的中文小说之一。

多种语言版本的三体封面展示
但《三体》在走向荧幕的道路上,却显得异常艰难,2015 就已经开机年拍摄的《三体》电影版,却迟迟没有上映的音讯。
故事的复杂程度,硬核的科幻元素,极具丰富力的想象场景,都是十分巨大的挑战。
在电影版没法打开突破口的当下,将其制作成动画,或许就能够避免诸多的限制。因为动画本身也依赖于想象力,可以天马行空的发挥,对画面和视觉表现上没有过多的实际上限。
也许正是这个原因,促使 B 站联合了三体宇宙和艺画开天,开始合力打造动画版的《三体》。
近年来的好的动画作品,都花了不短的时间才得以问世。
为国产动画提气的《大圣归来》,花费了八年时间精心打磨,最终交出了一张满意的答卷,还获得了 9.56 亿的票房。
耗时五年、历经 1600 多人参与制作的《哪吒之魔童降世》,更是斩获了 49 亿票房,成为了中国影史上的票房第二名。

《哪吒》有 1600 多人参与制作
共有 1400 多个特效镜头
优质的动画是一项浩大的工程,而且完全是个「苦力活」:大量人物形象制作、分镜动画绘制、以及特效的制作,短短十几秒画面,可能就需要几个团队几个月的努力。
所幸的是, AI 技术的发展,正在为动画的制作带来一些帮助,也许一些新的 AI 技术,能够帮助提供更高效的方法或者思路,以打造出更完美的《三体》动画。
对于熟练的动画师来说,完成一个符合人物形象的角色构建不是难事,但要让他们按照要求动起来,也许就多出了许多额外的工作。
比如二维动画中的绘制多个运动分镜头,或者是三维动画中的动作捕捉技术。但现在,AI 可以自动地将照片「唤醒」,让它们运动起来。
华盛顿大学和 Facebook 的研究人员,前段时间发布过一项研究,利用 AI 可以将静态的图片或者绘画中的角色或人物,转化成 3D 的动画形式。

可将图片、卡通或者绘画中的人物动起来
这项技术是在 PyTorch 框架上,开发而出的一套深度学习模型。软件从图像中分割出人物,然后将 3D 网格叠加上去,接着对网格进行动画处理,使照片或绘画达到栩栩如生的效果。
通过现成的算法,执行对图片的人物检测,2D 姿态估计和人物分割。然后,将 SMPL(蒙皮多人线性模型,一种 3D 人物模型)模板模型,拟合到 2D 姿势并将其投影到图像中,作为法线贴图和蒙皮贴图。
这一步的核心在于,找到人的轮廓和 SMPL 轮廓之间的映射,将 SMPL 法线/蒙皮贴图传送到输出,并通过整合运动的法线贴图来构建深度图。
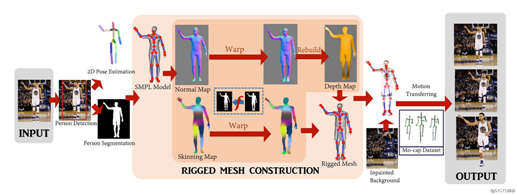
模型所用原理示意图(以真人照片为例)
重复此过程以模拟模型的后视图,并结合深度贴图和蒙皮贴图,以创建完整的装配 3D 网格。最后将网格被进一步纹理化,并使用在修复背景上的运动捕获序列,进行最终的动画处理。
也就是说,只要有了角色全身的正面图像,运用此技术,就可以得到运动起来的场景。它从单个图像中,重建了虚拟形象的途径,同时探索了从图片到人物建模的技术可能。
对于改编的作品来说,要想彻底地忠实于原著,而且最大程度地简化操作,可能最理想的方式,还是利用文本直接生成动画。在这一点上,AI 技术正在不断地进步。
在 2018 年,伊利诺伊大学和艾伦人工智能研究所的研究人员,开发了一种称为 CRAFT(组成、检索和融合网络)的 AI 模型,该模型根据文字描述(或标题),可从《摩登原始人》的素材中生成相应的动画场景。

每个动画下方是输入的描述
最终的 AI 模型,通过对 25,000 多个视频剪辑进行训练而得来。素材中的每个视频为 3 秒钟,长 75 帧,并被标记和注明场景中的角色以及场景的内容。
AI 模型学习将视频与文字描述进行匹配,并建立出一组参数。最终可以将提供的文字描述,转换为该动画系列的同人衍生,包含从视频中学到的角色,道具和场景位置等等。
如果说这还只是简单的剪辑拼接,那么现在的 AI ,已经可以做的更多。
在今年 4 月份,迪士尼和罗格斯大学的科学家发表了一篇论文,通过喂给 AI 模型 996 个剧本,最终让 AI 学会了够按照文本描述,自动生成动画。
要让 AI 实现从文本到视频的生成,需要其「理解」文本,然后生成对应的动画。为此他们采用了多个模块组件的神经网络。
模型包含三个部分,一是脚本解析模块,自动将剧本文本中的场景解析出来,然后是自然语言处理模块,能够提取出主要描述句子,并提炼出动作表示,最后是一个生成模块,将动作指令转化成动画序列。
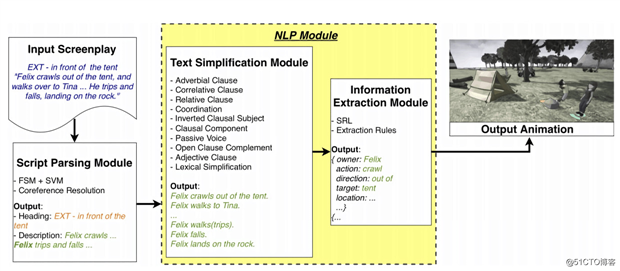
模型的流程示意
研究人员从可自由获取的电影剧本中,搜集并整理后,编写了场景描述语料库。 它由 525,708 个描述组成,包含 1,402,864 个句子,其中 920,817 个包含有至少一个动作。
建立起描述语言和视频的映射后,就能通过输入剧本,生成出简单的动画片段。在测试实验中,生成动画的合理性为 68%。
如果技术再成熟一点,想必改编过程会出现的信息偏离,也就不存在了。
虽然这些技术,想要用在《三体》动画的制作上,还存在一定的距离,但这些新鲜的思路,将会给动画的制作带来一些新的思路。
从目前看来,只要有足够的数据量和训练,AI 模型学会生成动画的那一天应该不会太遥远。
说回《三体》动画,因为有三体宇宙、艺画开天这样强大的制作班底,以及 B 站的大力支持,给这部动画加入了不少的筹码。
2021,风里雨里,我们等你!
—— 完 ——
扫描二维码,加入 AI 讨论群
获得更多优质数据集
了解人工智能落地应用
关注顶会&论文
回复「读者」自动入群
更多精彩内容(点击图片阅读)
标签:场景 book 投影 影视 自己 想象力 完成 开发 吸引
原文地址:https://blog.51cto.com/14929242/2534254