标签:knn 人工 无法 包含 中国人 一个 也会 均衡 优化
https://mp.weixin.qq.com/s/_m0naPXtms4oW3X_qPx3hABy 超神经
场景描述:要问什么水果和夏天最搭,答案一定是西瓜。作为西瓜生产与消费大国,中国在 2018 年以全世界 20% 的人口消耗掉全世界 70% 的西瓜,人均 100 斤。如何挑选最甜的瓜,也成了「吃瓜群众」十分关心的问题。一位浙江大学的博士,用机器学习的方法判断西瓜的成熟度,十分接地气。
关键词:西瓜 声学特征检测 机器学习大数据表明,今年夏天,是 140 年来最热的夏天。「热」已成为全球热词,我们经历了最热六月,刚送走最热七月,正在进入最热八月……
在难熬的酷暑面前,抱着半块冰凉的西瓜大快朵颐,无疑是最佳解暑选择了。啃着吃,勺子挖着吃,打成沙冰吃,炒着吃,烤着吃,怎么吃都好吃……
世界上,恐怕没有比中国人更爱吃、更能吃也更会吃西瓜的了。
自从 1000 多年前南北朝时期,西瓜传入中国,它就慢慢开始登上夏日水果霸主的地位。
有史学家考证,1000 多年前北京地区已有西瓜种植,而古人最早的「吃西瓜」场面,是在内蒙古辽代墓葬壁画上发现的,此墓筑于公元 1026~1027 年间。

1000 多年来,西瓜的外貌基本没什么变化
刚传入中国时,西瓜还属于贵族专享。直到公元 1143 年,南宋官员洪皓出使金国回来之时,带回了金人种植的西瓜种子,从此江南有了西瓜,老百姓也能吃上西瓜了。

洪皓回到南宋后,将见闻整理成书
洪皓撰写的《松漠纪闻》中,有一段对西瓜的描述:「西瓜形如匾蒲而圆,色极青翠,经岁则变黄。其瓞类甜瓜,味甘脆,中有汁,尤冷。予携以归,今禁圃乡囿皆有。」
此后,西瓜开始频现于南宋文人笔端,「年来处处食西瓜」、「西瓜黄处藤如织」、「醉拾西瓜擘」等文字,都表明西瓜已经越来越普及。

湖北恩施发现了北宋咸淳年间的「西瓜碑」
碑文记载了当地所种植的四种西瓜
西瓜,已经成为了中国文化的一部分。很多成语都和西瓜有关:老王卖瓜,滚瓜烂熟,瓜熟蒂落,顺藤摸瓜……
2004 年,位于北京大兴区庞各庄镇的「中国西瓜博物馆」,正式开馆,其外形效果主题为「飞翔的西瓜」,寓意中国西瓜飞出国门。这是国内首家以「西瓜」为主题的博物馆。博物馆内向人们展示西瓜历史、西瓜种植、西瓜文化以及科技等内容。

中国西瓜博物馆里到处都是西瓜相关的照片、漫画、模型
根据联合国粮农组织 FAO 公布的数据,当前,我国已成为世界上最大的西瓜生产国和消费国,2018 年我国消化了超过 7000万吨西瓜,也就是人均消费掉了 100 斤。
所以,在西瓜面前,我们都可以骄傲地说:我终于实现了水果自由!
不过,吃瓜容易挑瓜难。面对一堆长相相似的西瓜,如何才能选中最好最甜的瓜?全球通用的办法是:敲它。

西瓜西瓜告诉我,你是不是最甜的瓜
但是,事实上,很多「吃瓜群众」最后敲来敲去,也听不到西瓜的回答。
于是,一位浙江大学的博士写了一篇 130 页的论文《西瓜成熟度和内部空心的声学检测技术及装置研究》(论文地址:http://t.cn/AiYcAYei),告诉我们,如何利用人工智能技术,从敲西瓜的声音来判别最甜的西瓜。

除了这位博士,还有很多硕博士也都在做这方面的研究
当然,他做这项研究的初衷,是为了提高瓜农收入,扩大西瓜的对外出口。也顺便造福一下我们广大「吃瓜群众」。
传统方法如何判断西瓜成熟
我国西瓜产量和种植面积居世界第一,但是出口量却不到产量的 1%,不仅是因为我们自己消耗的多,还因为西瓜产后检测和处理的手段落后,导致质量良莠不齐,商品化程度较低。
西瓜是否适时采收对西瓜品质影响极大,过熟或者不熟采摘都会影响西瓜的品质与口感。在我国,采收时机主要还是依赖于瓜农的主观经验,他们往往通过生长周期、气候(主要是气温)以及观察瓜皮颜色、纹理来判断西瓜成熟情况。
当然,还有一个技巧,就是上文提到的,敲瓜皮听声音。这是目前瓜农最常用的方法。

从左至右西瓜成熟度分别为:未熟,成熟,过熟
一般来说,未熟西瓜声音较清脆,敲打时会发出「咚咚咚」的声音,成熟瓜声音比较低浊,发声为「嘭嘭嘭」,而过熟西瓜则会发出「扑扑扑」的声音。靠人工一个一个去检测,费时费力且依赖经验,准确率无法保证。
如今,计算机、图像处理、传感器等技术飞速发展,将这些技术广泛用于农产品品质检测中,可以大大提高检测效率与准确率。
用机器学习判断,准确又高效
通过研究,论文作者发现西瓜成熟度的变化,一般与内部成分(如糖度)和结构(如体积质量变大、内部空心)的变化密切相关,而这些变化也会导致声学特征参数发生变化,因此他认为利用声学无损检测方法,通过不同建模方法与技术,来判断西瓜熟度比较合适。
而且,对比其他检测方法,比如激光、核磁共振等技术,声学特征检测具有价格低廉、检测效率高、准确度高的优点。试验之后,作者得出结论,LS-SVM 方法在西瓜成熟度分类建模中表现最佳,预测准确率为 73.6%。

声学检测装置实物图
在声学检测装置结构和材料优化基础上,并对敲击信号去噪之后,作者进行了两种试验,分别为成熟度分类试验和空心判定试验。
试验中选用了麒麟西瓜作为样本,为杭州市余杭区仓前镇吴山前村五组瓜农于温室瓜棚分批次采摘,采摘后便立刻搬至实验室。
成熟度分类试验中,选用 147 个非空心瓜,随机分为两组:建模集 75 个,预测集 72 个。
空心判定试验中,选取 190 个样本(包含有空心瓜),随机分为两组,建模集 97 个,预测集 93 个。
建模集用来建立样本的分类或空心判定模型,预测集用来测试模型的性能。
试验采用了四种常见有监督机器学习算法和模式识别算法,分别是线性判别分析法(LDA)、K-最小近邻法(KNN)、BP 神经网络技术(ANN)和最小二乘-支持向量机法(LS-SVM),以声学特征对未熟、成熟和过熟三种西瓜进行了分类,此外还对空心瓜进行鉴别。
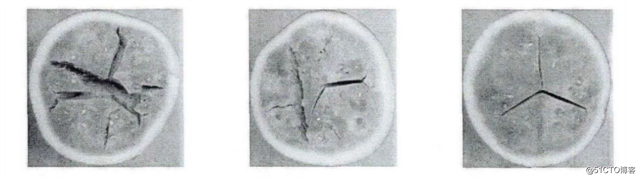
空心瓜样本中,空心体积位置与形状都有所不同
为了消除敲击西瓜声音频谱中峰值分裂所造成的不利影响,作者定义了一阶矩指数 MI1 和二阶矩指数 MI2,因为在西瓜穿刺试验中(判断果肉坚实度)判定这两个参数与西瓜成熟度关联性较高,因此将其作为西瓜成熟度分类的声学特征参数。
最适配辨瓜算法:LS-SVM
试验结果表明,LS-SVM 算法建模集和预测集的准确率分别为 76% 和 73.6%,均高于其他三种分类器的分类结果。
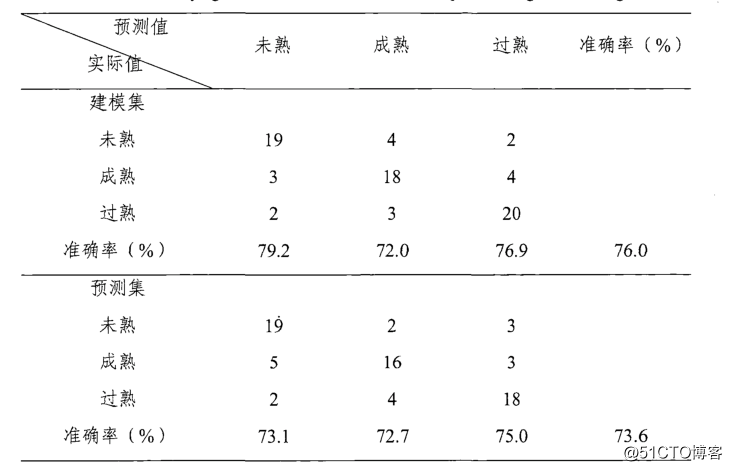
三种不同成熟度西瓜的 LS-SVM 分类结果
另外,神经网络建模集和预测集准确率分别 73.3% 和 66.6%,仅次于 LS-SVM。
作者由此得出结论:LS-SVM 采用了线性方程组对 SVM 的二次规划问题加以简化,分类效率得到大幅度提高,并且引入惩罚因子使结构风险化最小。该方法更适用于处理小样本集合不均衡样本集不均衡西瓜样本集的分类;
而 LDA 算法适用于线性分类问题;KNN 算法对不均衡样本集分类时,易使位置样本偏向数量多的样本类,造成分类误差变大;神经网络分类器则存在过拟合、易陷入局部极值的缺点。
此外,作者还采用了上述四类方法以及能量比经验阈值法,以 MI1、MI2 和能量比 Er为特征参数,对不均衡样本进行空心瓜判别。
作者采用 Fβ 分数作为分类器的评价指标,其物理含义是通过给予准确率和召回率不同的权重,将二者合并一个分数,综合评判分类器对样本总体和某类样本分类的准确程度。

Fβ 的定义
定义公式中,TP 为被正确划分为空心瓜的样本数,TN 为被正确划分为好瓜的样本数,P 为实际的空心瓜样本数,N 为实际的好瓜样本数。本文中 β = 2.
这些判别方法中,仍然是 LS-SVM 分类效果最佳,其建模集和预测集的 Fβ 分数分别为 88.1% 和 74.7%。
看来,关于如何挑到最甜的瓜,浙大博士已经帮我们算得清清楚楚了。
上千年的积累之下,西瓜已经越来越成为国人生活中的一部分。所谓「夏天没有吃过西瓜的人,不足以语人生。」
如今非常流行的网络热词「吃瓜群众」,也充分显示了我们对于西瓜的热爱。原本「吃瓜群众」中的「瓜」,指的是瓜子,但是由于西瓜的深入民心,这个「瓜」就渐渐演变成了「西瓜」。

而对于人工智能领域的同学来说,最熟悉的「瓜」一定是南大周志华教授撰写的《机器学习》西瓜书了。

这本机器学习入门著作,就是以挑西瓜开篇
并处处用西瓜来解释各种术语和问题
(周志华教授也一定很喜欢吃西瓜吧)
日本 Shibuya 公司的挑西瓜设备,下次大家可以带着它去买瓜
—— 完 ——

扫描二维码,加入讨论群
获得更多优质数据集
回复「进群」自动入群
更多精彩内容(点击图片阅读)
标签:knn 人工 无法 包含 中国人 一个 也会 均衡 优化
原文地址:https://blog.51cto.com/14929242/2534889