标签:info embed 锚点 删除 解释 归一化 没有 tps 最小
https://mp.weixin.qq.com/s/sRwjpW8cYxd2lw2yZD-MtwBy 超神经
场景描述:风靡各大直播平台的美妆博主,凭借高超的化妆技术吸金无数。而人工智能也已经开始学习这一本领。利用深度学习与计算机视觉技术,仅仅根据人的眼睛特征,就能给出适合用户的美妆搭配。
关键词:几何变换 triplet 损失函数 迁移学习近年来,网络上涌现出越来越多的美妆博主,他们讲解美妆技巧,分享化妆品试用效果,以此积累粉丝,与商家合作销售产品。
比如,前段时间大火的李佳琦,被称为「口红魔鬼」的美妆博主。他曾疯狂地在一次直播中一口气试了 380 种口红色号,并创下一分钟内售出 14,000 支口红的纪录。
然而,很多爱化妆的妹子应该早有领悟,明明买了和博主一模一样的口红,可画出来效果却不一样。看到「李佳琦」们试用的色号很美很仙很贵气,可到了自己嘴上怎么就……

口红界的「卖家秀」和「买家秀」
没错,正是因为每个人的脸型、肤色、唇形等等都不一样,才导致了「卖家秀」和「买家秀」的结果。
那么问题来了,怎样才能知道最适合自己的美妆产品是哪款呢?一个叫做 Mira 的公司给出的答案是:用深度学习。
许多人印象中,人工智能、深度学习这些名词和美妆应该八竿子打不着关系,但位于美国洛杉矶的创企 Mira 可不这么想。
这家公司决定用人工智能技术帮助广大爱美女士,比如获取化妆灵感,购买合适的美妆产品等。

美妆前后,效果堪比换脸
在随机和数十位美妆人士详聊后,Mira 团队了解到,目前女性消费者在寻找合适的化妆产品和美妆方法时,遇到的最大困难是,没有权威且可信的声音能针对她们个人的美容需求做出指导。
在本文我们就聊聊 Mira 的技术团队如何用深度学习和计算机视觉技术发现切中这个问题要害的实例:找到讲解人类具体眼型和面部肤色的美妆大咖、图片和视频等信息。
沿着这种方式, Mira 团队借助三个简单但强大的知识——几何变换、triplet 损失函数和迁移学习,只用最小限度的人类输入数据就能解决种种困难的美妆推断问题。
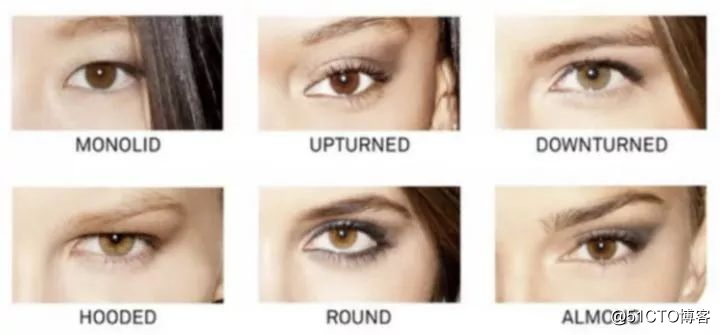
眼部分类示意图
爱化妆的女士都知道,找到适合自己眼睛的美妆产品和方法是很困难的——每个人的眼型和面部肤色都不一样。
即便是同一种眼妆(比如烟熏妆),根据眼型不同,所用的化妆方法也大不相同。
虽然像 Birchbox 等推出了一些有用的化妆指南,但 Mira 团队经过调查发现,美妆爱好者们通常还是喜欢听听专业且可信的建议,尤其是和自己眼型相似的人的化妆建议,她们对这些建议的重视程度甚至都超过了美容专家的意见。

利用人工智能技术,现在我们根据自己的眼部特征,以及自己其它独特的面部特征,就能让自己知道怎么化妆、买什么化妆品。
我们把问题形式化一下:根据一组面部照片,以及少许数量的人工标记的照片(标记了眼睛颜色、眼睑形状等),找到两个眼睛之间的视觉相似性度量(《红楼梦》中「这个妹妹我曾见过的」就是这个意思)。然后用分类器捕捉人工标记的属性。
本文先重点讲解如何确定眼睛之间的相似度,后面会详细解释如何进行分类任务。
原始图像并不是很适合计算视觉相似性或者进行分类任务。因为它们包含的很多相似性都是表面上的(比如画的妆很相似,由于强光才造成肤色看起来不同)。
而这些和人物真正的眼部结构及面部肤色并没有关系。而且,原始图像一般都处于高维空间,这就需要大量的有标记训练数据用于分类任务。

如上图,如果仅直接比较图像像素,人物的眼睛都高度相似,但仔细注意会发现,虽然人物的眼影、光线和视线方向一致,但她们的眼睛颜色和面部肤色却各不相同。
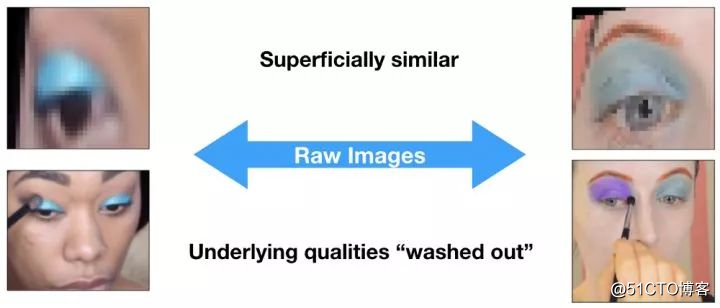
处理原始图像的困难所在:虽然上图两人的眼睛大不相同,但初始数据比较起来却很相似
那么 Mira 的首要任务就是:要获得眼部照片的低维和密集的数学表达形式,也就是我们所说的「嵌套」(embeddings)。
它只会捕捉任务所需的图像品质(嵌套是一种分类特征,以连续值特征表示。通常,嵌套是指将高维度向量映射到低维度的空间。)这样一来,「嵌套」应当忽略这些信息:
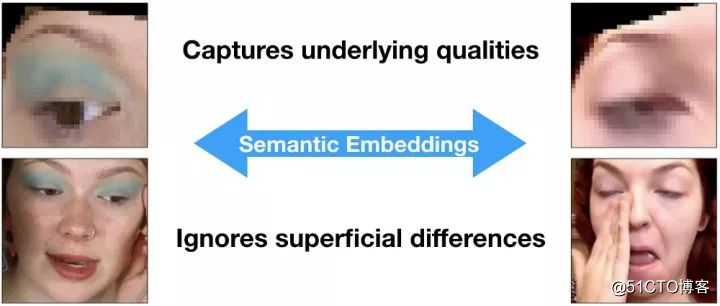
当用三重函数训练眼睛嵌入时,系统学会了忽略不相关特征
我们可以通过一个简单的预处理步骤——投影变化删除一整个类别的表面相似性。
虽然裁减过的眼部照片会出现很多明显的结构性差异(比如眼睛不在照片中心,或者由于头部倾斜的原因出现旋转等),但投影变化能让我们「扭曲」照片,这样就能保证相同的眼部标志处于相同的坐标。
借助一丁点的线性代数原理,我们就可以将一张图像「扭曲」,这样一组点会映射为一个新的理想的形状。旋转和拉伸图像的过程如下所示:

使用投影变化,可以将上面的图像进行扭曲处理,上图中的 4 个红点会组成一个矩形,从而将红点围住的文本「拉直」。Mira 团队在将眼部照片进行正常化处理时,应用了同样的方法。
研究人员接用 dlib 检测出脸部标记(如果你对 dlib 感兴趣,可以在以下链接中了解:http://blog.dlib.net/2014/08/real-time-face-pose-estimation.html)。
剪裁照片中的眼部部位,将其「扭曲」处理,确保它们对齐和一致。这步操作能让他们专注于让「嵌套」不受人物头部姿势和倾斜角度的影响。
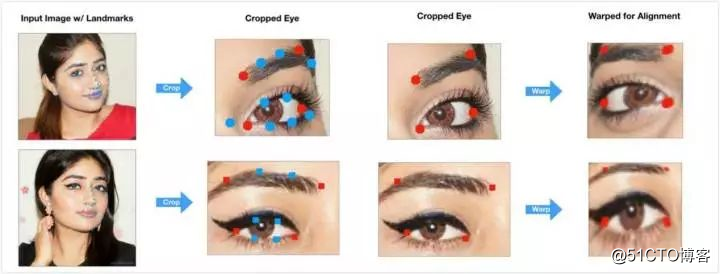
接着进行图像归一化:检测出面部标志,剪裁眼部图像,然后用投影转换将眼部图像「扭曲」至标准位置。

图像预处理流程中的图像样本
「扭曲」处理后的图像进行直接比较时,仍会表现出一些表面相似性,包括视线方向和相似的化妆等。深度学习技术就是解决这个问题的药方。
研究人员训练了一个卷积神经网络,用眼部照片输入它后会输出向量,相比不同人之间,同一个人眼部照片输出的向量更具相似性。神经网络会学习输出每个人眼在不同环境下的稳定持续的表示形式。
当然,这里所以靠的正是前面所说的 triplet 损失函数,其公式如下所示: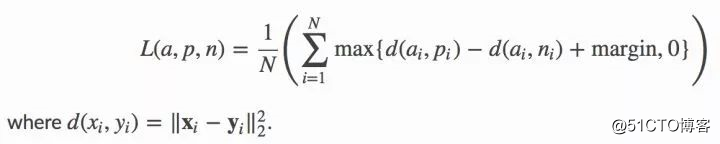
这详细说明了当函数将具体个体(锚点和正样本)的两个「嵌套」放置的位置比锚点和无关个体(负样本)的位置更近时,模型的损失和优化目标会递减。
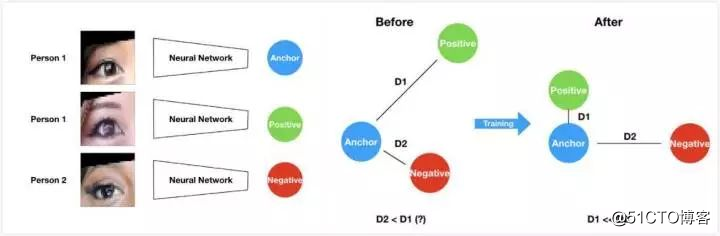
模型架构示意图
当研究人员将眼部照片应用到模型中时,他们发现生成的「嵌套」很好地指出了具有相似眼部结构和面部肤色的两张照片。

眼部嵌套相似的照片示例
这里所用的方法其实和谷歌的 FaceNet 很像,也就是通过对照片进行「扭曲」和一致性处理,应用 triplet 损失函数,生成脸部级别的图像嵌套。
研究人员对生成的嵌套进行了简单调试,让其同样适用于支持人级(Person-level)的眼部表示——提取出每个帧的全部噪声数据。
通过使用上面神经网络的预训练权重,研究人员又采用了新的损失函数,该函数将多组嵌套的平均值放在极为相近的位置(相对于无关个体),如下所示:
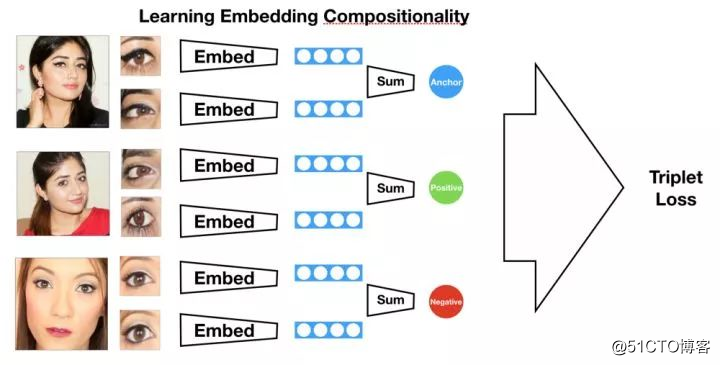
使用先前神经网络的预训练权重,研究人员可以让网络能够以求平均值的方式将眼部嵌套合并在一起,能看到模型快速收敛。这个过程就是常说的迁移学习。
迁移学习让嵌套能够合并为一个个体眼睛的更为整体的表示。虽然此时神经网络架构非常复杂了,但模型由于采用了迁移学习的原因能够快速收敛。
最终,研究人员用数据集对模型进行了验证,发现模型生成的嵌套能够捕捉个体之间的很细微的相似性,如下所示:

每一行人物的眼部嵌套之间非常相似
通过获得单张照片中人眼的高质量数学表示,研究人员就能找出人物眼睛构造的相似性,这就为只根据人的眼睛,为他/她匹配合适的眼妆风格打下了基础。
Mira 技术团队表示接下来的任务是应用几种监督式学习方法(分类眼型、回归眼睛颜色等),以及一些分析方法,搭建出能为人们提供化妆建议的 AI 模型。
也就是说,未来,妹子们不必再发愁画什么样的妆最适合自己的眼睛和肤色了,更不必机械地参考标准化妆指南和美妆博主试色效果,AI 会为你推荐更适合你自己的美妆术。
如此一来,美妆博主们恐怕要被抢饭碗了?不过,李佳琦也不用再那么辛苦地,在一次直播中试色 380 次了。
注:本文所有代码和结果的实现用到了 NumPy,SciPy,Matplotlib,Chainer,dlib 和 SqueezeNet 架构。
迁移学习
迁移学习是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。
深度学习中,在计算机视觉任务和自然语言处理任务中,将预训练的模型作为新模型的起点是一种常用的方法,通常这些预训练的模型在开发神经网络的时候已经消耗了巨大的时间资源和计算资源,迁移学习可以将已习得的强大技能迁移到相关的的问题上。
以下是两个常用的方法:

标签:info embed 锚点 删除 解释 归一化 没有 tps 最小
原文地址:https://blog.51cto.com/14929242/2535366