标签:谷歌搜索 loading ddl enc open request width bsp --
最近看B站突发了想要爬一爬的想法,之前仅仅爬过某鬼畜的评论,(看到评论内容就应该知道是哪个鬼畜了叭)

然而当时并没有试着爬取视频,我们也知道网页版的B站要插件才可以下载视频,现在我不管,我就要下载,我就要白嫖。
首先随便找一个首页通知的视频得了:https://www.bilibili.com/video/BV1yp4y1a7VG?spm_id_from=333.851.b_7265706f7274466972737431.7
接着使用Fiddler进行抓包,我发现当视频不断播放的时候,一直会返回这样的一个数据
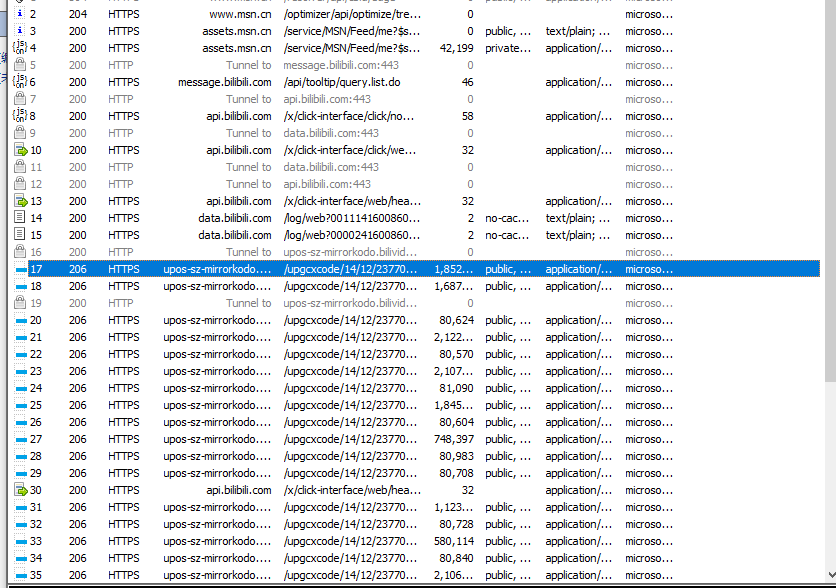
看到这里我内心就想破案了,现在看看这个视频界面源码有没有这个链接就可以了,提取出来写入保存为Mp4即可。
然而我打开这个链接出现的确是这个样子

看到这里就很奇怪,网址被移动了,移到哪里了呢?我继续往下翻,看到了几个js文件,可能在这里面嘛???
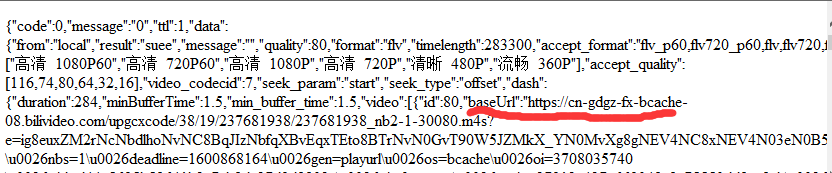
OHHHHHH!!!有baseURL,还是个m4s文件,基本稳了。赶紧复制打开看看对不对
(几分钟后)
emmmm结果出来了,不是空白就是403,不对劲啊,到底在哪???
后来为了多了解一下原因,想要多看看教程,我干脆谷歌搜索,也没找到,重新爬试试吧,结果有点奇怪。。。。。。
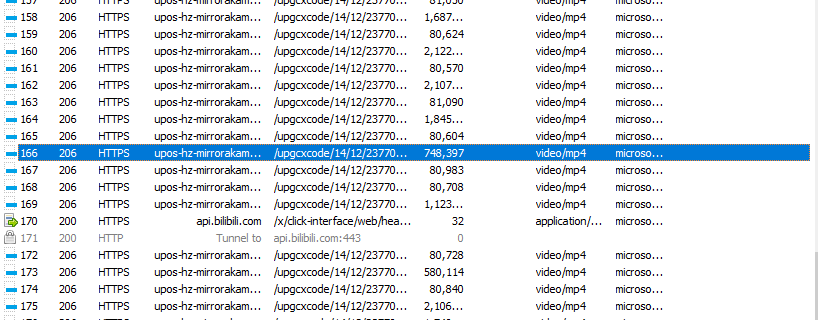
两个对比一下可以发现链接不一样了,而这个是可以打开的,就是没有声音,可能视频和音频数据分开传送了,这个待会会说到,我重新试了几次都是一样的结果,我现在坚信我第一次错了
然后我把这个视频的源码爬下来,找了找是否有这个url,果然没错,不过一如既往的没声音,这个后来我去问度娘,那个m4s之前的30080代表的是1080p,30064代表的是720p等等,音频的数字是30280等等,这个要自己看。既然到了这一步而且有源码了爬取视频和音频自然就简单了很多。以下是代码部分。
import requests
from bs4 import BeautifulSoup
import json
# 设置headers
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"}
# 首先爬取源码
url="https://www.bilibili.com/video/BV1yp4y1a7VG?spm_id_from=333.851.b_7265706f7274466972737431.7"
file=requests.get(url,headers=headers).text
file=BeautifulSoup(file)
# 为了方便寻找先写入一个txt文件里面,找到规律后就不用这一步了
# with open("1.txt",‘w‘,encoding="utf-8")as f:
# f.write(file)
# 提取出来想要的url,在一个<script>标签里面
data=file.select("script")[4].text
# data属于一个字符串,为了更方便提取,将其转换成json文件
data=json.loads(data[20:])["data"]["dash"]
# 开始寻找视频和音频,第一个是质量最高的,故索引值为0
video=data[‘video‘][0]["baseUrl"]
audio=data["audio"][0]["baseUrl"]
# 注意写入文件里面的时候video后缀是MP4,audio后缀是MP3。这里就不写出来了
print(video)
print(audio)
经过检验是没问题的。害,结束了,B站也好爬
-----------------------------------------------------------------------------------------------------------------------
等等,刚刚好像有个细节,我谷歌搜索后再次使用fiddler就变得正常了,难道说......
试试就试试,
呵呵,果然和之前第一次爬取的时候一样,我对比了两个源代码,发现里面那个所谓的baseUrl根本不一样,也就是说我第一次爬取的链接是假的,怪不得网页提示我网址被移动了
B站你真的不对劲!!!
标签:谷歌搜索 loading ddl enc open request width bsp --
原文地址:https://www.cnblogs.com/starpython/p/13721256.html