标签:表拆分 添加文件 适合 com 就是 不同 性能 png serve
概述
分区表
1,分区表(水平分表)
分区表并不算高难度的技术点
传统分表:将一个大表在逻辑上拆分成多个小表;它们在业务上可能会保持整体;但是在逻辑上实际已经不是同一个表了
这种分表增加程序的复杂度,如要针对不同的表生成不同的sql语句;增加程序出错的可能性;增加了开发工作量
分区表:将大表分成若干个小表,它们逻辑上还是一张表;也叫物理分表;从物理上将一个大表拆分成多个小表
分区后的聚集索引是分布在各个分区中的;并不是在同一个分区
对于开饭者而言,都是对同一张表的访问;而数据库会自动将数据写入或读取相应数据所存放的表的物理文件;
它是将一个数据文件拆分成多个数据文件;文件的存放依托于一个文件组;或者是多个文件组,多个文件组实际上可以提高访问的并发量;
不同的分区的可以配置在不同的磁盘上,以提高IO;将多个文件组放在不同的磁盘上,提高IO效率
所以推荐分区的数量和文件组的数量保持一致,以提升IO
优势:
查询合理时,使用正确的查询列,可以减少IO,数据量;提升部分性能
分区表适合限定操作数据量,减小数据操作的数据量
面对大数据量时,可以提高一部分性能
使用水平分区表的场景
出现数据分段时;如以年进行数据分段
对数据的操作只涉及到某一部分数据,这一部分数据具有自己的特征,一般特征比较明显
sql server2019使用分区表
1,给数据库添加文件组;如下给Foundation数据库添加5个文件组
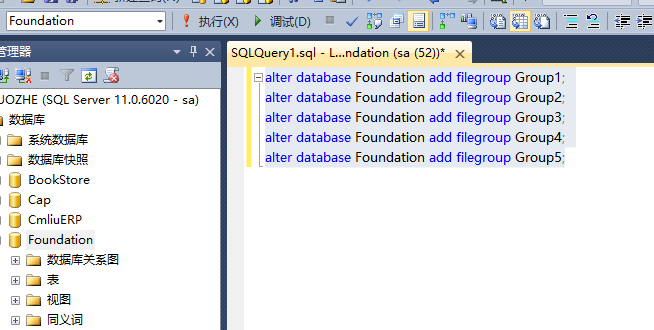
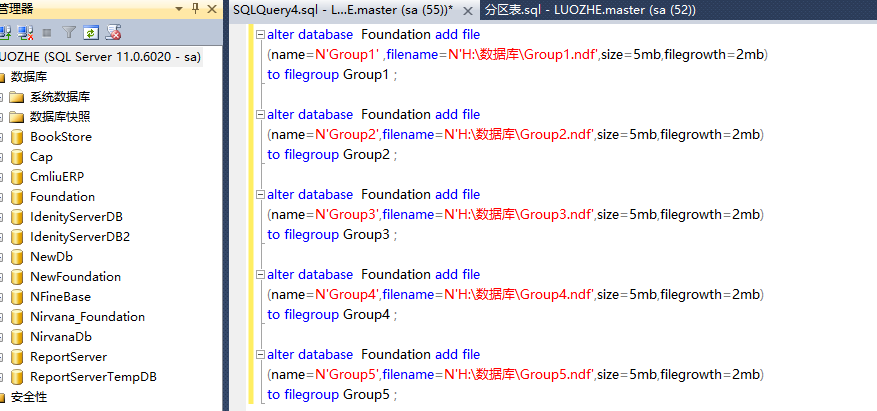
2,给每一个文件组创建文件
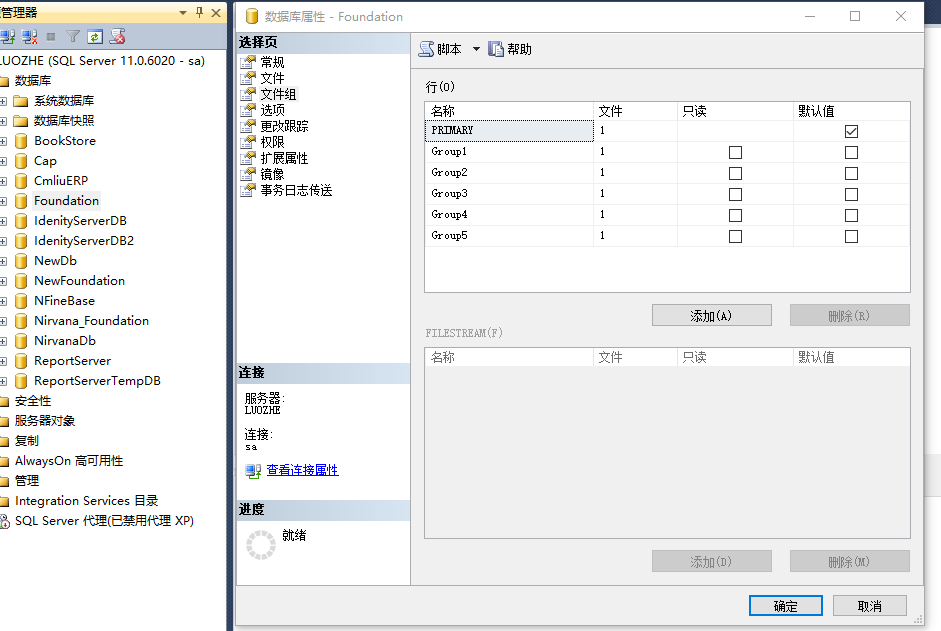
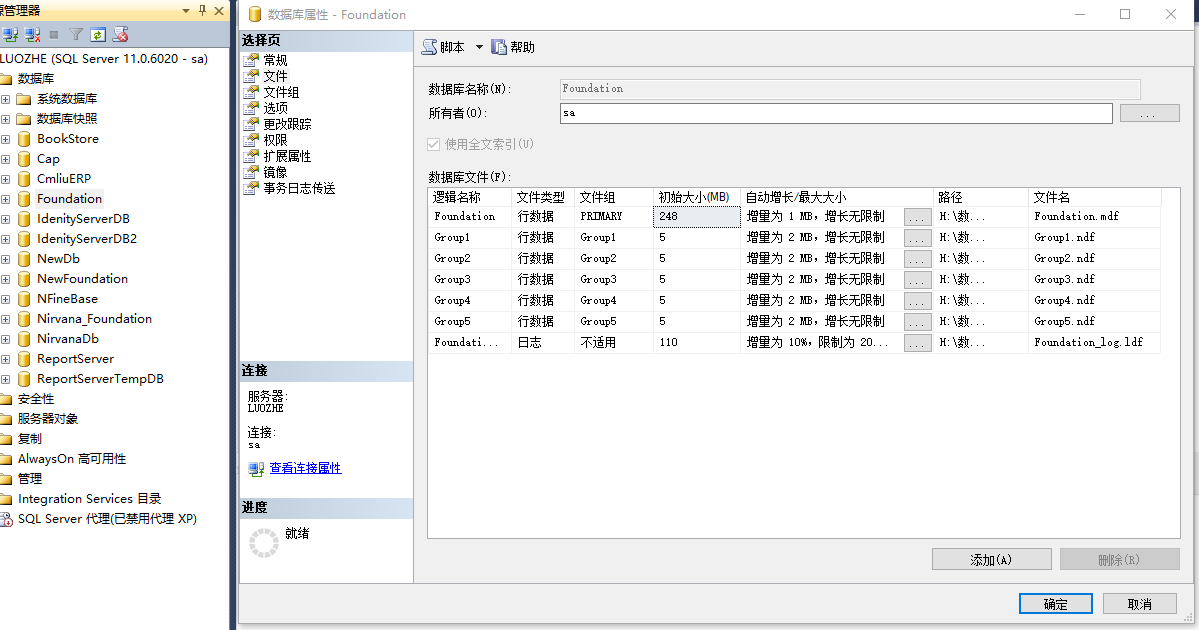
3,你可以在文件组的属性中查看到新增的文件组和文件
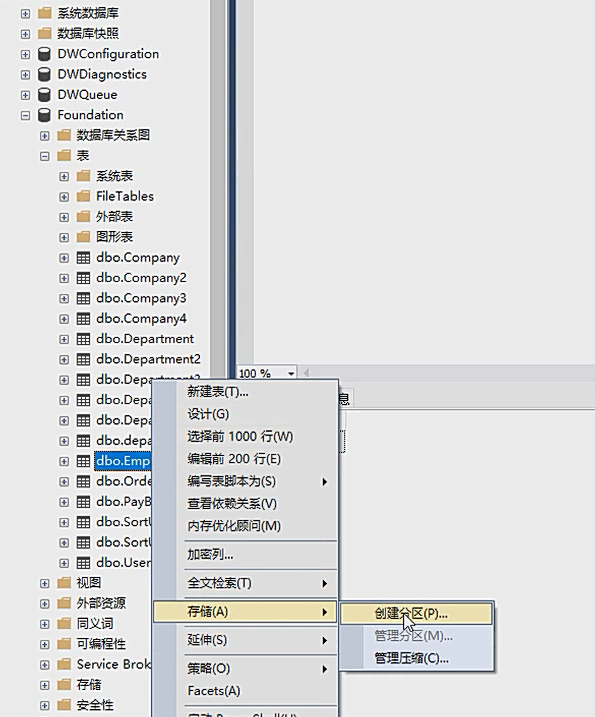
4,为表创建分区;如下示例;选择Employee表(100万行数据);右键->属性->存储->创建分区
5,选择分区列;
跟随分区向导,进入分区列选择页;分区列是根据列的范围进行划分表的分区
如选择int型列(id,编码等),1-100000在一个分区;100001-200000在另一个分区......
如选择datetime型列(交易时间,创建时间等),2018年,2019,2020年的数据分别在不同的分区.....
datetime类型列一般在【业务】逻辑上也具有分区,int类型的相对而言【业务】上的分区没那么强
在此处,我们选择了一个名为shardId的int型自增的字段作为分区列
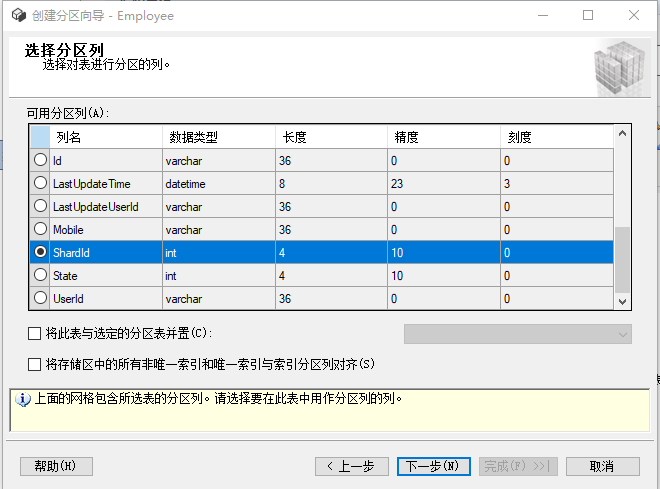
这里选择的shardid是一个自增的int字段
6,设置分区;
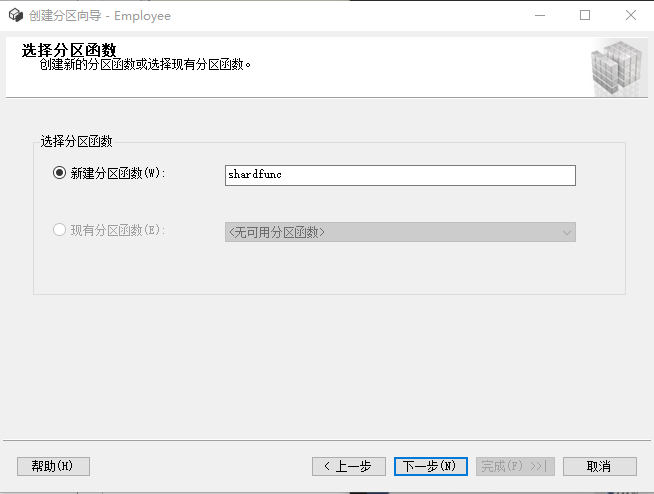
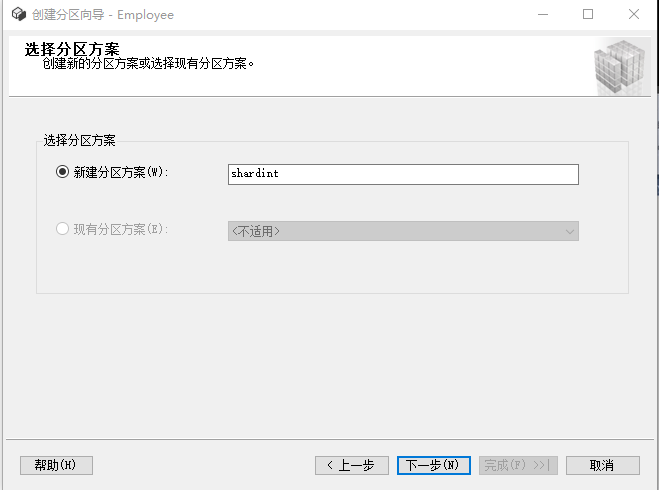
点击"下一步”,输入分区函数(实际上就是一个命名);再点击"下一步”,输入分区方案(实际上就是一个命名)
7,设置分区详细规则
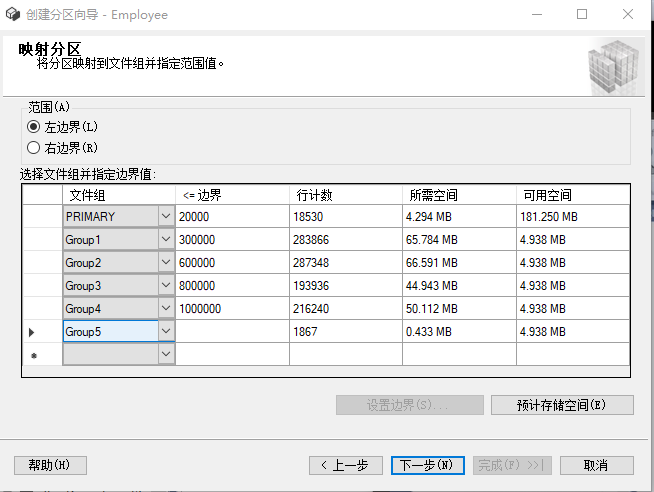
规则有两种,左边界,右边界;在此我们使用左边界
选择文件组,设置边界值;
注,最后一个文件组的边界我设置为了空,表示超过上一个边界的都存放在最后一个边界
点击预计存储空间,可以看到对应的存储空间
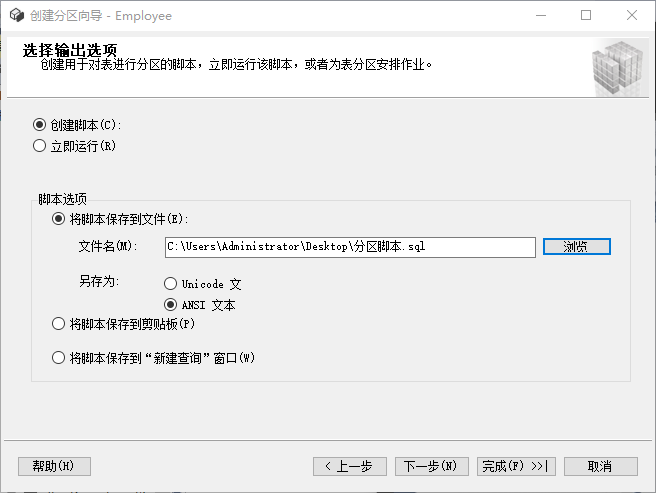
8,点击下一步,生成分区执行的脚本
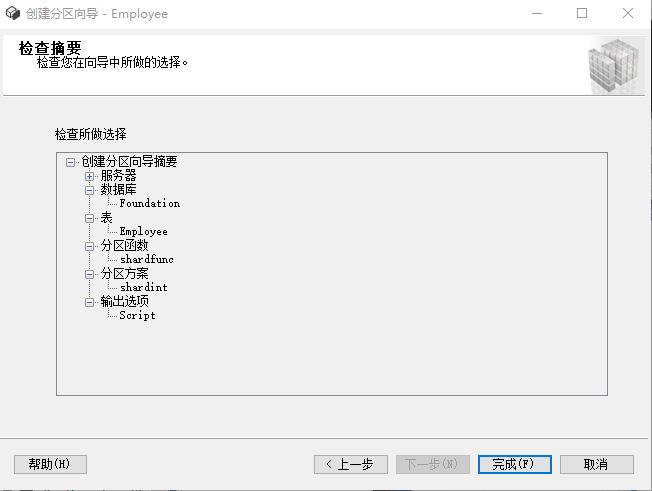
9,执行生成的分区脚本
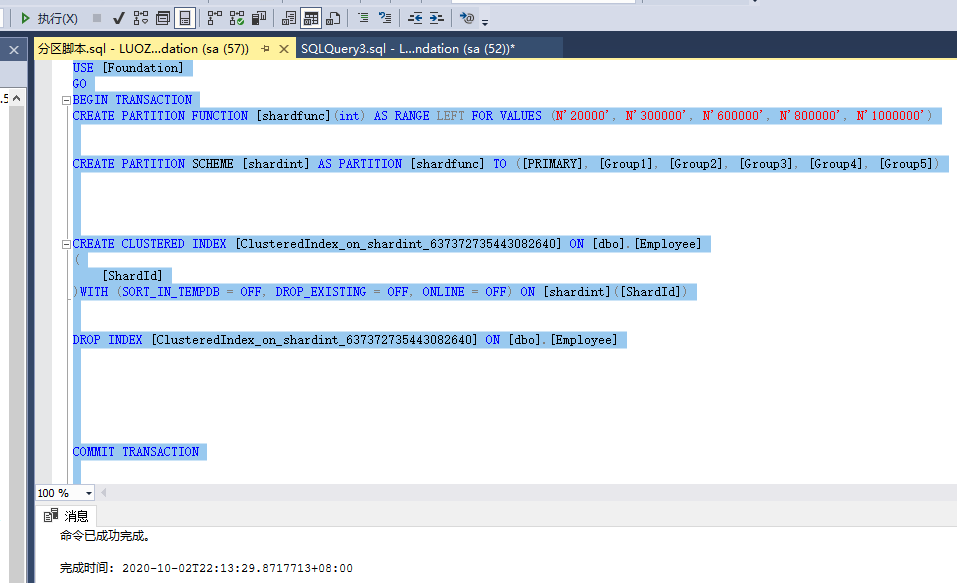
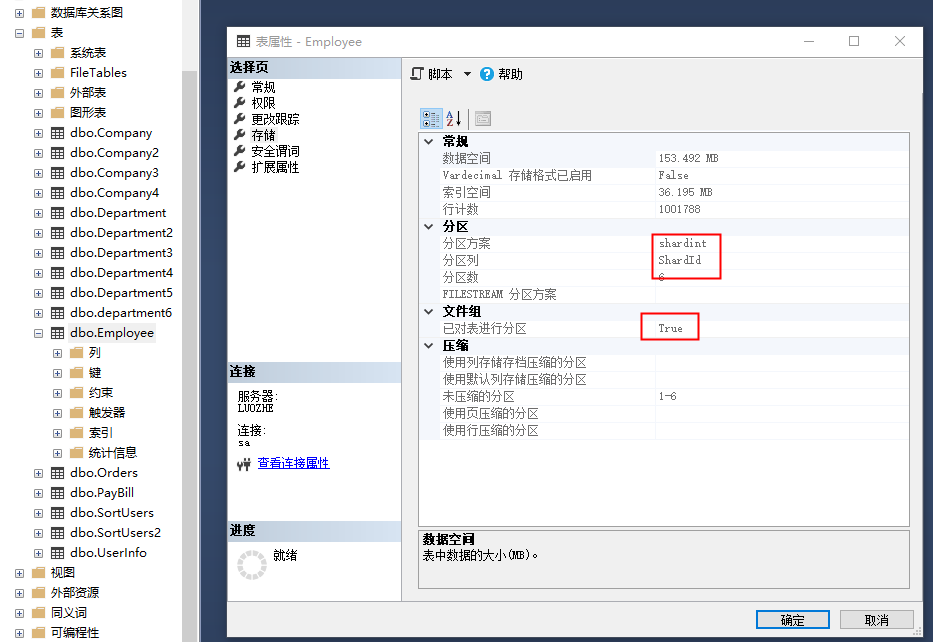
10,查看被分区的表的分区情况
在表属性的存储页签中,你可以看到表的分区方案,分区列,分区数,是否执行分区等;
按以下步骤操作查看;选择Employee表,右键->属性->存储
总结:分区表整体上还是一个表,但是物理上已经分成了若干个不同的文件;
当对分区表进行全表扫描时,由于数据分布在不同的文件上,会比未分区的表会有性能下
标签:表拆分 添加文件 适合 com 就是 不同 性能 png serve
原文地址:https://www.cnblogs.com/cmliu/p/13682163.html