标签:vdc 位置 梯度 ima rtc 使用 目标 feed color
标签一般指的是我们要预测的真实事务,在图3中,我们用y坐标的值进行表示。
特征是指用于描述数据的输入变量,一般使用{x1,x2,…,xn}进行表示,在图3所示的线性回归问题中只有一个x轴。
样本是指数据的特定实例:x ,有标签样本具有{特征,标签}:{x,y},被用于训练模型;无标签样本具有{特征,?}:{x,?},用于对新数据做出预测。
模型可将样本映射到预测标签:y’,由模型的内部参数定义,这些内部参数值是通过学习得到的。
3、 训练(学习)
训练模型表示通过有标签样本来学习(确定)所有权重和偏差的理想值,在监督式学习中,机器学习算法通过以下方式构建模型: 检查多个样本并尝试找出可最大限度地减少损失的模型, 这一过程称为经验风险最小化。
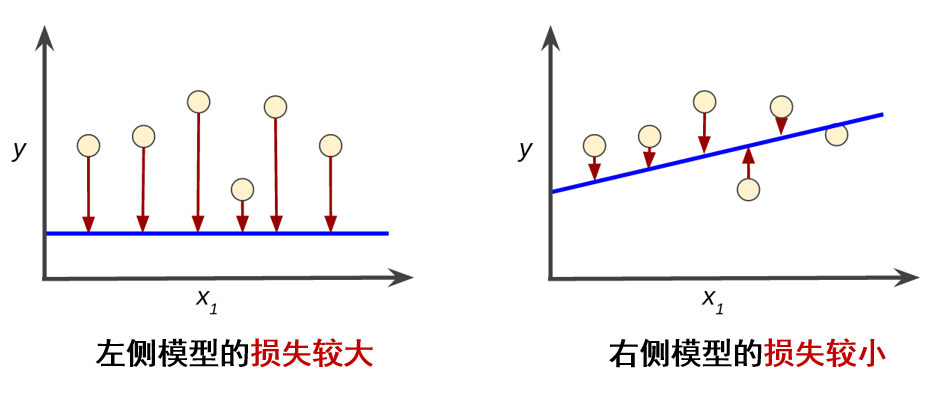
损失是对糟糕预测的惩罚,损失是一个数值,表示对于单个样本而言模型预测的准确程度。
如果模型的预测完全准确,则损失为零,否则损失会较大。
训练模型的目标是从所有样本中找到一组平均损失“较小”的权重(w)和偏差(b)。
损失函数(Loss Function)也称为代价函数(Cost Function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。
下面介绍三个比较常见的损失函数。
1、L1损失
L1范数损失函数,也被称为最小绝对值偏差(LAD),最小绝对值误差(LAE)。总的说来,它是把目标值(Yi)与估计值(f(xi))的绝对差值的总和(S)最小化:
2、L2损失
L2范数损失函数,也被称为最小平方误差(LSE)。总的来说,它是把目标值(Yi)与估计值(f(xi))的差值的平方和(S)最小化:
3、均方误差 (MSE)
均方误差 (MSE) 指的是每个样本的平均平方损失
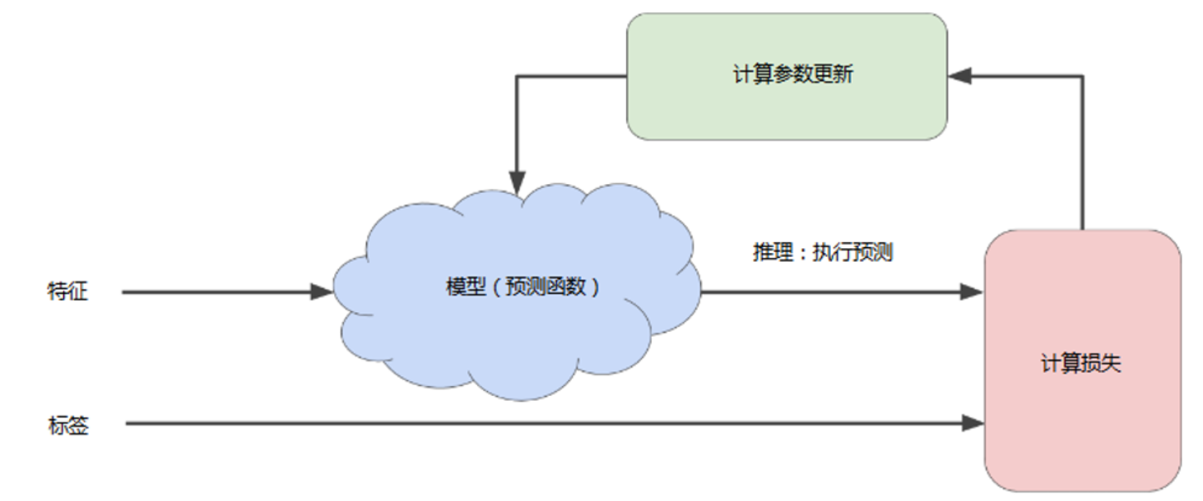
首先我们先对模型的中的权重w和偏差b进行猜测,然后将特征点输入,执行预测和推理(Inference),将计算出的值和该样本的标签值进行对比,计算出损失值,我们的目标是使推理的值和标签值的差距越小越好,也就是损失的值越小越好,所以需要不断对计算参数进行更新,直到损失值尽可能地最低为止。
在学习优化过程中,机器学习系统将根据所有标签去重新评估所有特征,为损失函数生成一个新值,而该值又产生新的参数值。
通常,您可以不断迭代,直到总体损失不再变化或至少变化极其缓慢为止。这时候,我们可以说该模型已收敛
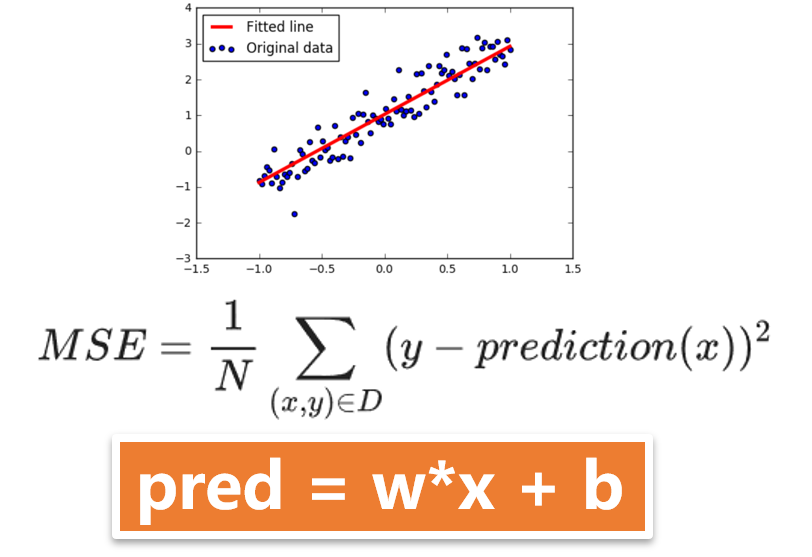
如图4-5为线性回归计算损失的例子,图中给出了预测值的计算方法和均方误差的定义。
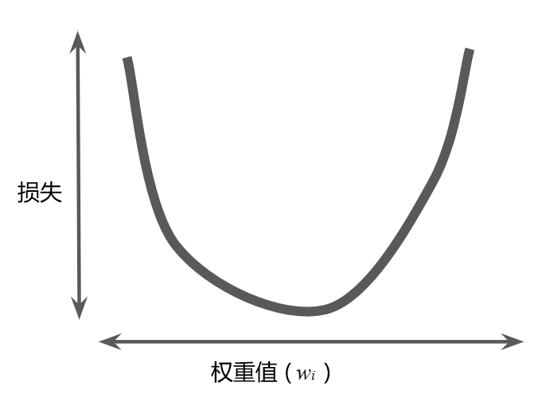
易知该线性回归问题产生的损失与权重的关系图为凸形,如图4-6所示。
梯度下降法的基本思想可以类比为一个下山的过程,假设一个人在山上,此时他要以最快的速度下山,就需要梯度下降来帮助自己下山。具体来说,就是以自己现在所处的位置为基准,寻找一个山势最陡峭的方向,沿着高度下降的方向走,就能以最快速度到山底。
同理,将上一节所提到的损失函数看作一座山,我们的目标就是找到这个损失函数的最小值(山底),那么我们就可以在初始点找到该点函数的梯度,沿着函数值下降的方向对参数进行更新,这就是梯度下降法。
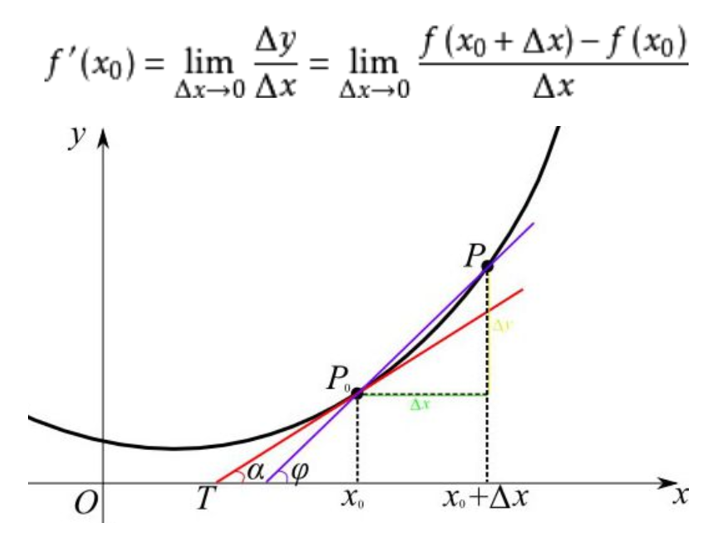
梯度是一个向量(矢量),具有大小和方向,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大。
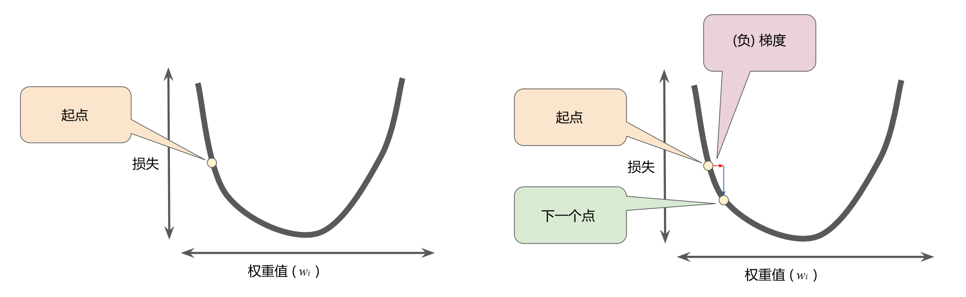
如图4-9所示,梯度下降法的第一个阶段是为 选择一个起始值(起点),起点并不重要,因此很多算法就直接将设为0或随机选择一个值。图4-9中我们选择了一个稍大于 0 的起点,然后梯度下降法算法会计算损失曲线在起点处的梯度,简而言之,梯度是偏导数的矢量——它可以让您了解哪个方向距离目标“更近”或“更远”。请注意,损失相对于单个权重的梯度就等于导数。
梯度始终指向损失函数中增长最为迅猛的方向,梯度下降法算法会沿着负梯度的方向走一步,以便尽快降低损失。
那么沿着负梯度方向进行下一步探索,前进多少才合适呢?这时我们就要引入学习率的概念了。
用梯度乘以一个称为学习率(有时也称为步长)的标量,以确定下一个点的位置。例如:如果梯度大小为 2.5,学习速率为 0.01,则梯度下降法算法会选择距离前一个点 0.025 的位置作为下一个点。
所以学习率是指导我们该如何通过损失函数的梯度调整网络权重的一个参数(也成为超参数)。学习率越低,损失函数的变化速度就越慢。
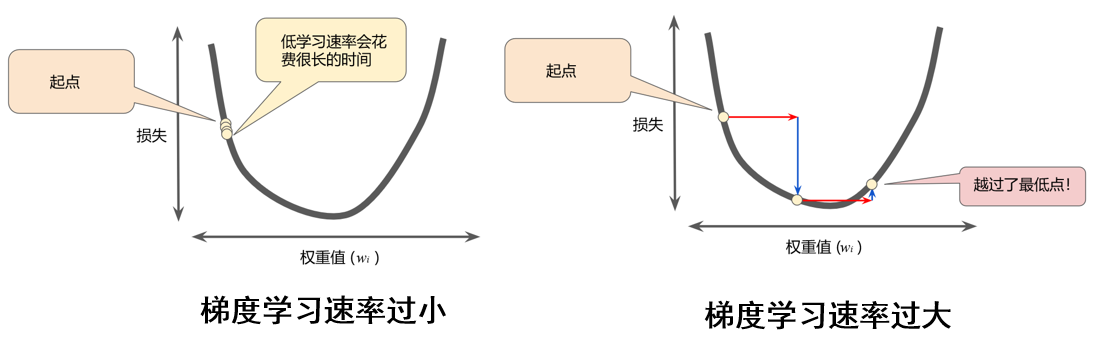
如图4-10所示,如果学习率选择过小,损失函数优化速度极慢,训练的实践会非常长。而如果学习率选择过小,容易越过损失函数的最低点,无法拟合。

所以选择学习率(乃至所有超参数的选择)就像一个和面的过程,水放的太多容易太稀,水放的太少没黏性。
上一节已经提到了学习率这个超参数,在机器学习中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,选择一组好的超参数,就可以提高学习的性能和效果。可以这么说,超参数是编程人员在机器学习算法中用于调整的旋钮。
典型超参数:学习率、神经网络的隐含层数量……
使用TensorFlow进行算法设计与训练有以下四个核心步骤:
(1)准备数据
(2)构建模型
(3)训练模型
(4)进行预测
上述步骤是我们使用TensorFlow进行算法设计和训练的核心步骤,贯穿于后面介绍的具体实战中,本章用一个简单的例子来讲解这几个步骤。
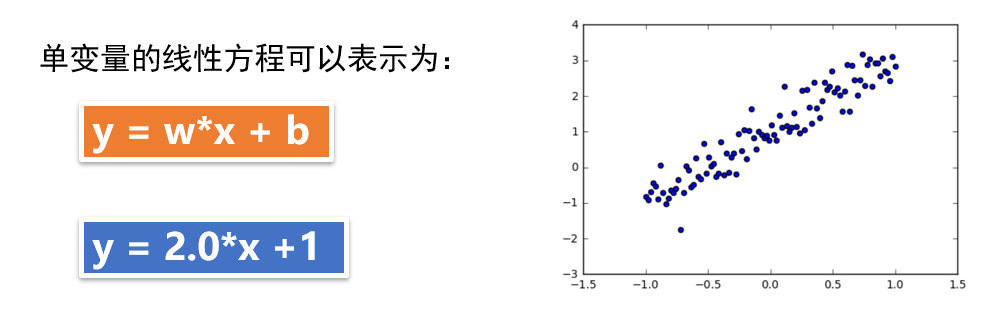
本例通过生成人工数据集。随机生成一个近似采样随机分布,使得w=2.0, b=1, 并加入一个噪声,噪声的最大振幅为0.4。
下面我们来展示具体代码,假设我们要学习的函数为线性函数 ??=2??+1。
#在Jupyter中,使用matplotlib显示图像需要设置为 inline 模式,否则不会现实图像 %matplotlib inline import matplotlib.pyplot as plt # 载入matplotlib import numpy as np # 载入numpy import tensorflow as tf # 载入Tensorflow np.random.seed(5) #我们需要构造满足这个函数的 ?? 和 ?? 同时加入一些不满足方程的噪声。 #直接采用np生成等差数列的方法,生成100个点,每个点的取值在-1~1之间 x_data = np.linspace(-1, 1, 100) # y = 2x +1 + 噪声, 其中,噪声的维度与x_data一致 y_data = 2 * x_data + 1.0 + np.random.randn(*x_data.shape) * 0.4 #画出随机生成数据的散点图 plt.scatter(x_data, y_data) # 画出我们想要学习到的线性函数 y = 2x +1 plt.plot (x_data, 2 * x_data + 1.0, color = ‘red‘,linewidth=3)
上面的代码产生了随机的-1到1的100个点,我们使用matplotlib库将这些点和要学习得到的线性函数可视化出来,得到图4-16。
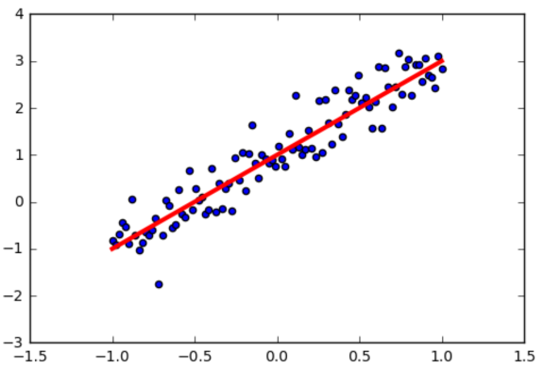
首先我们定义训练数据的占位符,这是后面数据输入的入口,x是特征值,y是标签值。
# 定义训练数据的占位符,x是特征值,y是标签值 x = tf.placeholder("float", name = "x") y = tf.placeholder("float", name = "y") #然后我们定义模型函数,在本例中是个简单的线性函数。 def model(x, w, b): return tf.multiply(x, w) + b #接下来我们创建模型的变量,Tensorflow变量的声明函数是tf.Variable, #tf.Variable的作用是保存和更新参数,变量的初始值可以是随机数、 #常数或是通过其他变量的初始值计算得到。 # 构建线性函数的斜率,变量w w = tf.Variable(1.0, name="w0") # 构建线性函数的截距,变量b b = tf.Variable(0.0, name="b0") # pred是预测值,前向计算 pred = model(x, w, b) #定义一些超参数,包括训练的轮数和学习率。其中如果学习率设置过大, #可能导致参数在极值附近来回摇摆,无法保证收敛。 #如果学习率设置过小,虽然能保证收敛,但优化速度会大大降低, #我们需要更多迭代次数才能达到较理想的优化效果。 # 迭代次数(训练轮数) train_epochs = 10 # 学习率 learning_rate = 0.05 # 控制显示loss值的粒度 display_step = 10 #定义损失函数和优化器。损失函数用于描述预测值与真实值之间的误差, #从而指导模型收敛方向。 # 采用均方差作为损失函数 loss_function = tf.reduce_mean(tf.square(y-pred)) # 梯度下降优化器 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) 声明会话及初始化。 sess = tf.Session() init = tf.global_variables_initializer() sess.run(init)
模型训练阶段,设置迭代轮次,每次通过将样本逐个输入模型,进行梯度下降优化操作,每轮迭代后,绘制出模型曲线。
# 开始训练,轮数为 epoch,采用SGD随机梯度下降优化方法 for epoch in range(train_epochs): for xs,ys in zip(x_data, y_data): _, loss=sess.run([optimizer,loss_function], feed_dict={x: xs, y: ys}) b0temp=b.eval(session=sess) w0temp=w.eval(session=sess) plt.plot (x_data, w0temp * x_data + b0temp )# 画图
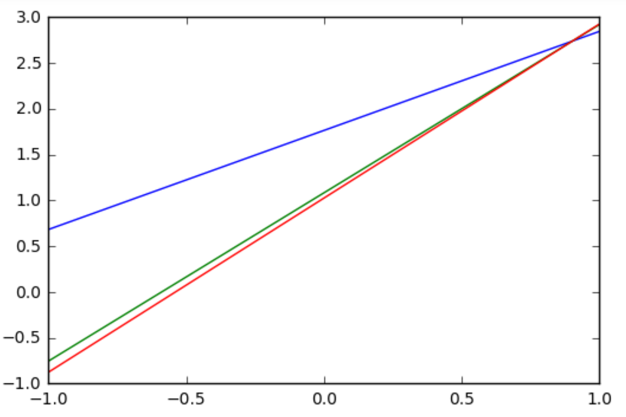
从上图可以看出,本案例所拟合的模型较简单,训练3次之后已经接近收敛 对于复杂模型,需要更多次训练才能收敛。
x_test = 3.21 predict = sess.run(pred, feed_dict={x: x_test}) print("预测值:%f" % predict) target = 2 * x_test + 1.0 print("目标值:%f" % target)
6、在训练中显示损失值
为了使训练时结果更加直观,我们将每一轮的训练损失值都显示出来,只需在之前的训练的代码中加入几行显示代码
# 开始训练,轮数为 epoch,采用SGD随机梯度下降优化方法 step = 0 # 记录训练步数 loss_list = [] # 用于保存loss值的列表 for epoch in range(train_epochs): for xs,ys in zip(x_data, y_data): _, loss=sess.run([optimizer,loss_function], feed_dict={x: xs, y: ys}) # 显示损失值 loss # display_step:控制报告的粒度 # 例如,如果 display_step 设为 2 ,则将每训练2个样本输出一次损失值 # 与超参数不同,修改 display_step 不会更改模型所学习的规律 loss_list.append(loss) step=step+1 if step % display_step == 0: print("Train Epoch:", ‘%02d‘ % (epoch+1), "Step: %03d" % (step),"loss=", "{:.9f}".format(loss)) b0temp=b.eval(session=sess) w0temp=w.eval(session=sess) plt.plot (x_data, w0temp * x_data + b0temp )# 画图
7、可视化
首先,如果要在TensorBoard中查看,要在前面训练时将TensorBoard的日志图写入日志。

在Anaconda Prompt中进入日志目录,运行TensorBoard:tensorboard –logdir=D:\log
标签:vdc 位置 梯度 ima rtc 使用 目标 feed color
原文地址:https://www.cnblogs.com/zhangxianrong/p/13772154.html