标签:网页 很多 有关 计算机 硬盘 strong 基于 表示 客户
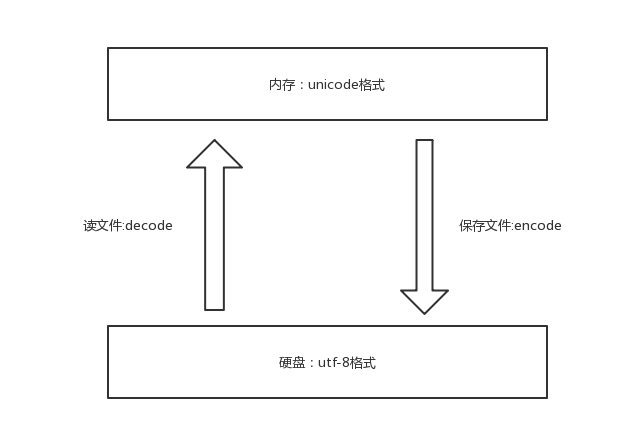
计算机只认识数字,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符?必须经过一个过程: 字符--------(翻译过程)------->数字 这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
#!/usr/bin/env python
# -*- coding:utf-8 -*-#将bytes转换为strname_b = b‘tom‘name_s1 = name_b.decode(‘utf-8‘)name_s2 = str(name_b,encoding=‘utf-8‘)print(name_b,type(name_b)) #b‘tom‘ <class ‘bytes‘>print(name_s1,type(name_s1)) #tom <class ‘str‘>print(name_s2,type(name_s2)) #tom <class ‘str‘>#将str转换为bytesgender = ‘male‘gender_b1 = gender.encode(‘utf-8‘)gender_b2 = bytes(gender,encoding=‘utf-8‘)print(gender,type(gender)) #male <class ‘str‘>print(gender_b1,type(gender_b1)) #b‘male‘ <class ‘bytes‘>print(gender_b2,type(gender_b2)) #b‘male‘ <class ‘bytes‘>标签:网页 很多 有关 计算机 硬盘 strong 基于 表示 客户
原文地址:https://www.cnblogs.com/Teyisang/p/13775980.html