标签:高并发 利用 系统设计 第三方 错误 bsp 使用 通信 nbsp
除了运维团队对于机器CPU、内存、磁盘、网络等基础监控,还要完成应用程序对数据库的链接、服务报错异常、以及请求超时等问题能做到及时发现。
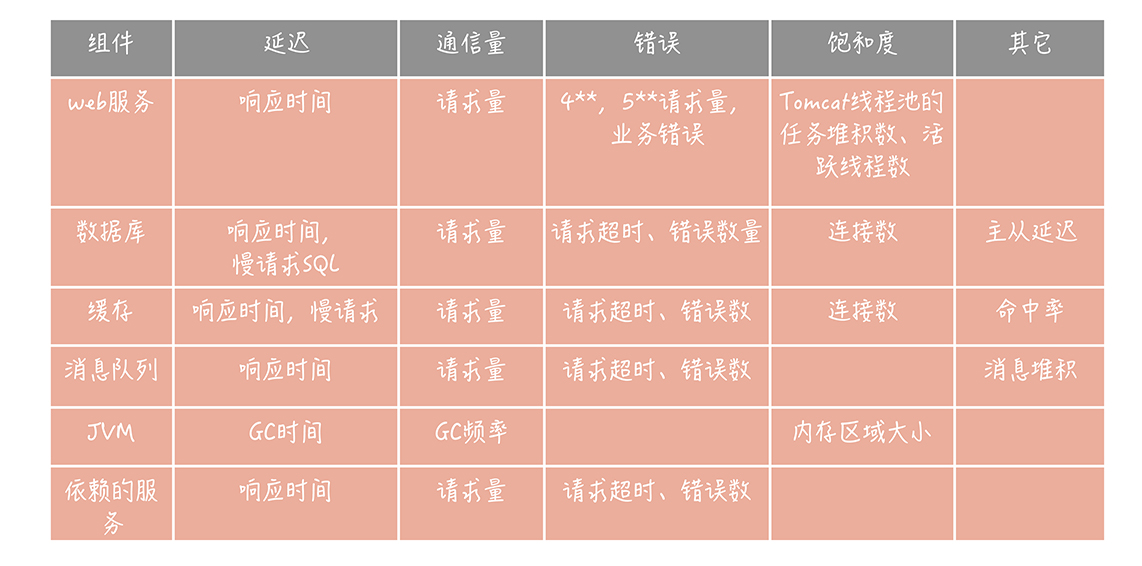
监控四个指标
分别是延迟,通信量、错误和饱和度。
延迟指的是请求的响应时间。比如,接口的响应时间、访问数据库和缓存的响应时间。
通信量可以理解为吞吐量,也就是单位时间内,请求量的大小。比如,访问第三方服务的请求量,访问消息队列的请求量。
错误表示当前系统发生的错误数量。这里需要注意的是, 我们需要监控的错误既有显示的,比如在监控Web服务时,出现4 * *和 5 * *的响应码;也有隐示的,比如,Web服务虽然返回的响应码是200,但是却发生了一些和业务相关的错误(出现了数组越界的异常或者空指针异常等),这些都是错误的范畴。
饱和度指的是服务或者资源到达上限的程度(也可以说是服务或者资源的利用率),比如说CPU的使用率,内存使用率,磁盘使用率,缓存数据库的连接数等等。
除了以上细节上的监控之外,还有一些监控开源了解下
监控手段还是不少的,Grafana 连接时序数据库,Skywalking,CNCF Prometheus等,APM系统 另外还可以结合Nginx、 Flume 、Kafka 、ELK 等日志收集做自己的系统分析
标签:高并发 利用 系统设计 第三方 错误 bsp 使用 通信 nbsp
原文地址:https://www.cnblogs.com/wt645631686/p/13865608.html