标签:分割 size 路径 com 之间 不可 排序 字母 大小写
1,stat 查看文档信息
格式:stat (文档路径)234.txt
如图
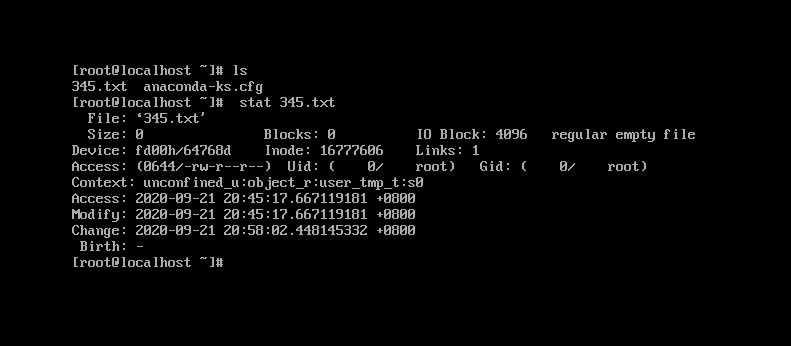
-File:显示文件名
-Size:显示文件大小
-Block:显示文件快内容
-IO Block:IO块大小
-regular empety file:常规空的文件
-Device:设备编号
-Inode:Inode号
-Links:链接数
-Access:文件权限
-Gid,Uid:文件所有权的Gid和Uid
-Access Time:文件的访问时间。用户访问时更新时间
-Modify Time:文件内容的修改时间。当文件数据被修改时更新时间
-Change Time:文件的状态信息。当文件的状态(链接数,权限,大小,Blocks数)被改变时更新时间
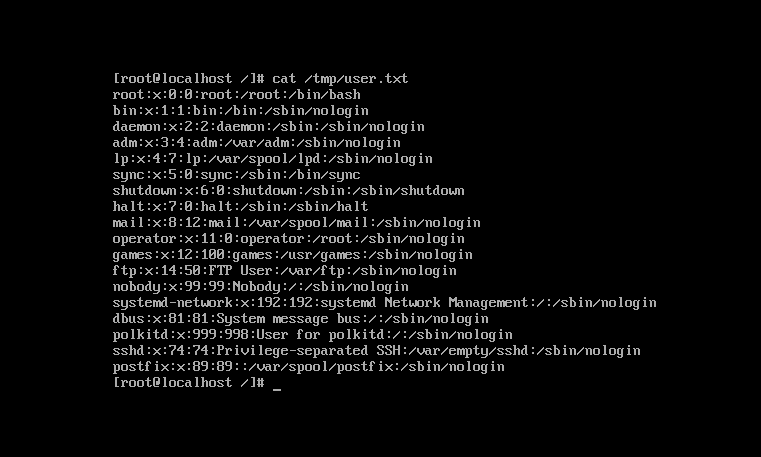
2,cat 显示文件中读取的内容
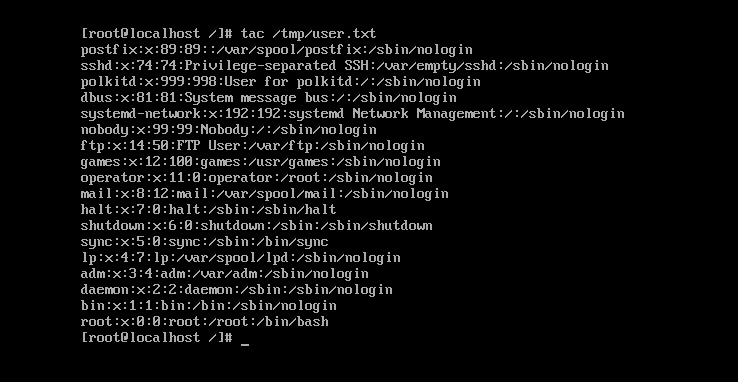
tac 逆序显示文件中读取的内容
cat 选项内容:
-n或-number:有1开始对所有输出的行数编号;
-b或--number-nonblank:和-n相似,只不过对于空白行不编号;
-s或--squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行;
-A:显示不可打印字符,行尾显示“$”;
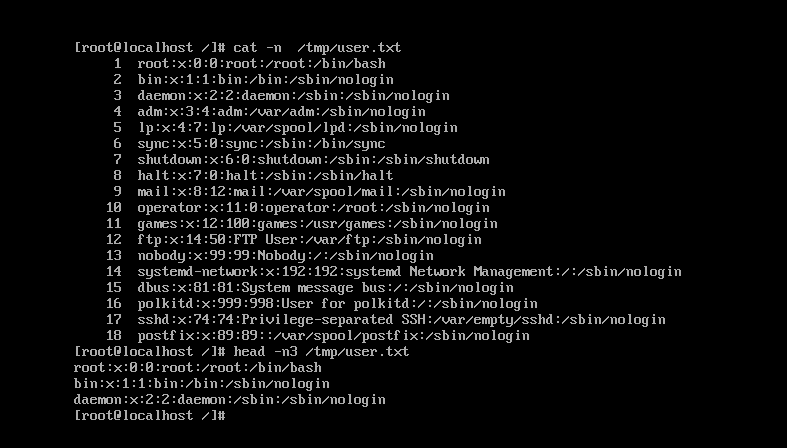
3,head 从头截取前几行
tail 从尾部截取后几行
以head为例
格式:head -n3(n后数字代表截取前几行)(路径)
如图
head选项内容:
-n或-number:有1开始对所有输出的行数编号;
-b或--number-nonblank:和-n相似,只不过对于空白行不编号;
-s或--squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行;
-A:显示不可打印字符,行尾显示“$”;
4,less(more)当西安市内容超出显示范围时,此命令可按页显示所需内容,可通过空格或方向键翻页
格式:命令 |less 如图

5,cut 从文本文件或文本流中提取文本列
cut选项内容:
-b:仅显示行中指定直接范围的内容;
-c:仅显示行中指定范围的字符;
-d:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f:显示指定字段的内容;
-n:与“-b”选项连用,不分割多字节字符;
--complement:补足被选择的字节、字符或字段;
--out-delimiter=<字段分隔符>:指定输出内容是的字段分割符;
--help:显示指令的帮助信息;
--version:显示指令的版本信息
其中“-b”,“-f”用的较多
如图显示/tmp/user.txt内容
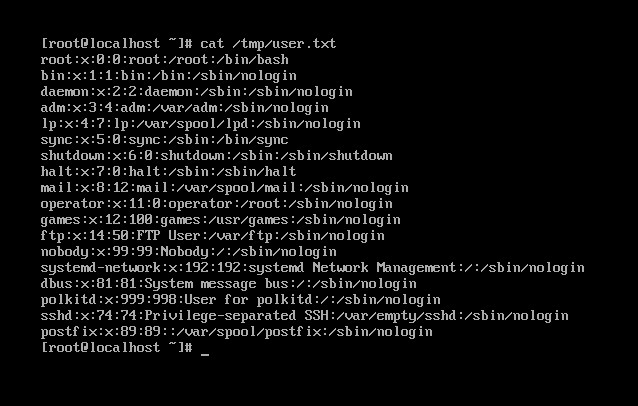
输入:cut -f3 -d":" /tmp/user.txt
“-f3”表示显示第三列
“ -d":" ”表示将“:”作为分隔符
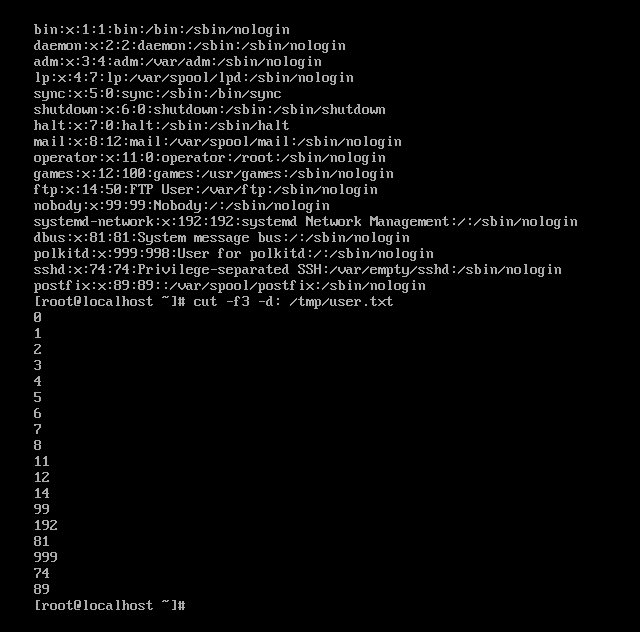
命令结果如图
6,grep 过滤出含有某关键字的内容
格式:grep 关键字
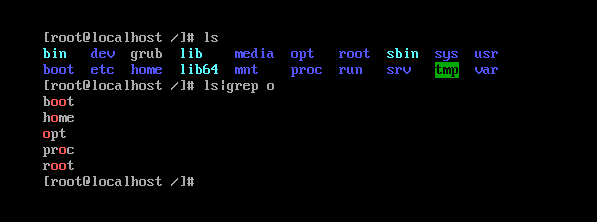
如图,在该目录下过滤出含有“o”的文件
grep选项内容:
-a 不要忽略二进制数据。
-A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c 计算符合范本样式的列数。
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
7,uniq 对重复行进行显示
uniq选项内容:
-c或——count:在每列旁边显示该行重复出现的次数;
-d或--repeated:仅显示重复出现的行列;
-f<栏位>或--skip-fields=<栏位>:忽略比较指定的栏位;
-s<字符位置>或--skip-chars=<字符位置>:忽略比较指定的字符;
-u或——unique:仅显示出一次的行列;
-w<字符位置>或--check-chars=<字符位置>:指定要比较的字符。
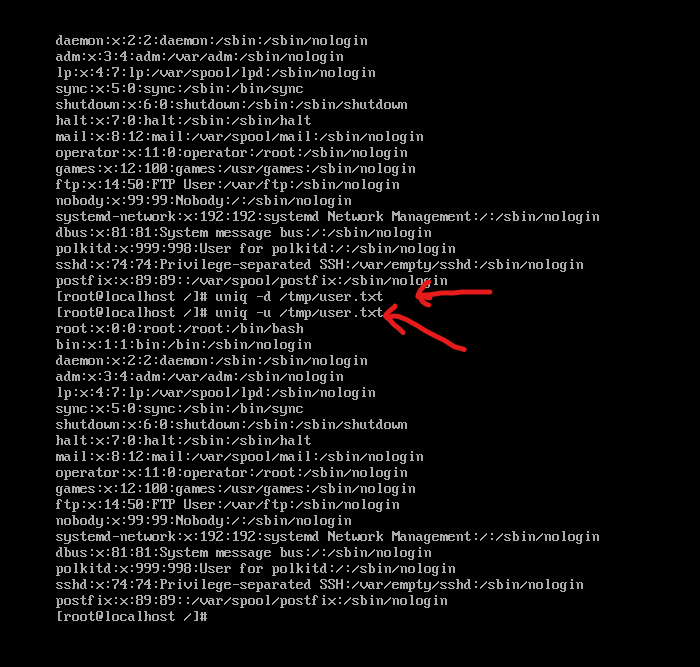
如图,第一行命令显示user.txt中不重复的内容,第二行命令显示出现一次的内容
8,sort 对内容进行排序
sort内容选项:
-b:忽略每行前面开始出的空格字符;
-c:检查文件是否已经按照顺序排序;
-d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符;
-f:排序时,将小写字母视为大写字母;
-i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符;
-m:将几个排序号的文件进行合并;
-M:将前面3个字母依照月份的缩写进行排序;
-n:依照数值的大小排序;
-o<输出文件>:将排序后的结果存入制定的文件;
-r:以相反的顺序来排序;
-t<分隔字符>:指定排序时所用的栏位分隔字符;
+<起始栏位>-<结束栏位>:以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
如图,对user.txt行列进行由英文a-z序列排序
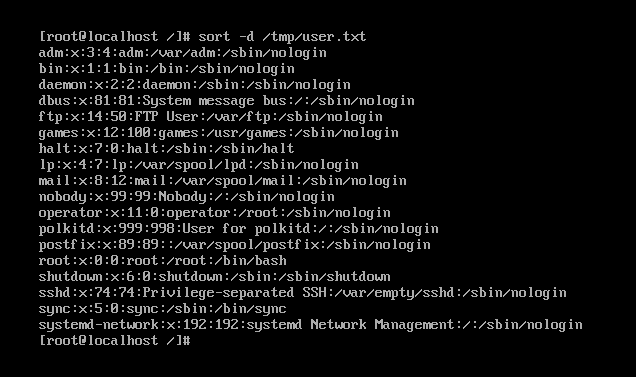
9,wc 对文本的内容统计
wc内容选项:
-c或--bytes或——chars:只显示Bytes数;
-l或——lines:只显示行数;
-w或——words:只显示字数。
如图对user.txt显示行数及字数
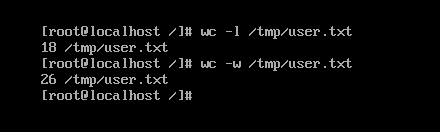
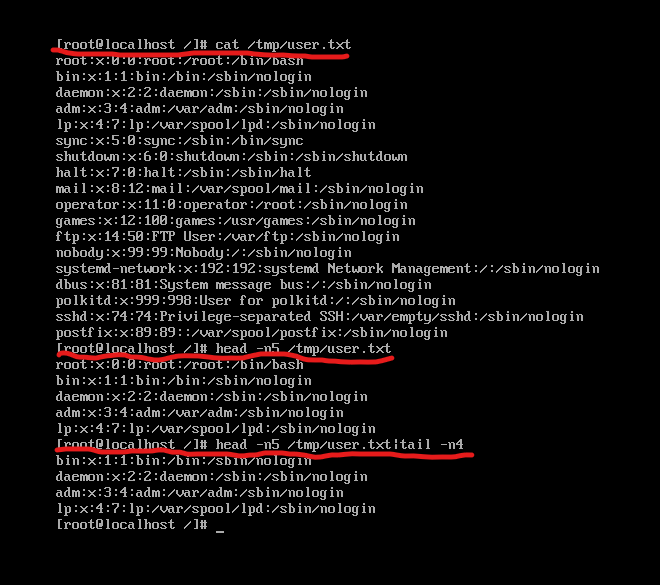
10,当我们需要在一个命令下运行又一个命令时可用次格式:命令1 | 命令2
例如,当我们需要显示user.txt中前2到5行时,可用此命令:head -n5 /tmp/user.txt | tail -n4
如图
标签:分割 size 路径 com 之间 不可 排序 字母 大小写
原文地址:https://www.cnblogs.com/wjl001122/p/13866207.html