标签:重点 size long 一个队列 限制 duration 效率 技术 str
继上周的《Kafka生产者的使用和原理》,这周我们学习下消费者,仍然还是先从一个消费者的Hello World学起:public class Consumer {
public static void main(String[] args) {
// 1. 配置参数
Properties properties = new Properties();
properties.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("bootstrap.servers", "localhost:9092");
properties.put("group.id", "group.demo");
// 2. 根据参数创建KafkaConsumer实例(消费者)
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 3. 订阅主题
consumer.subscribe(Collections.singletonList("topic-demo"));
try {
// 4. 轮循消费
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
} finally {
// 5. 关闭消费者
consumer.close();
}
}
}前两步和生产者类似,配置参数然后根据参数创建实例,区别在于消费者使用的是反序列化器,以及多了一个必填参数group.id,用于指定消费者所属的消费组。关于消费组的概念在《图解Kafka中的基本概念》中介绍过了,消费组使得消费者的消费能力可横向扩展,这次再介绍一个新的概念“再均衡”,其意思是将分区的所属权进行重新分配,发生于消费者中有新的消费者加入或者有消费者宕机的时候。我们先了解再均衡的概念,至于如何再均衡不在此深究。
我们继续看上面的代码,第3步,subscribe订阅期望消费的主题,然后进入第4步,轮循调用poll方法从Kafka服务器拉取消息。给poll方法中传递了一个Duration对象,指定poll方法的超时时长,即当缓存区中没有可消费数据时的阻塞时长,避免轮循过于频繁。poll方法返回的是一个ConsumerRecords对象,其内部对多个分区的ConsumerRecored进行了封装,其结构如下:
public class ConsumerRecords<K, V> implements Iterable<ConsumerRecord<K, V>> {
private final Map<TopicPartition, List<ConsumerRecord<K, V>>> records;
// ...
}而ConsumerRecord则类似ProducerRecord,封装了消息的相关属性:
public class ConsumerRecord<K, V> {
private final String topic; // 主题
private final int partition; // 分区号
private final long offset; // 偏移量
private final long timestamp; // 时间戳
private final TimestampType timestampType; // 时间戳类型
private final int serializedKeySize; // key序列化后的大小
private final int serializedValueSize; // value序列化后的大小
private final Headers headers; // 消息头部
private final K key; // 键
private final V value; // 值
private final Optional<Integer> leaderEpoch; // leader的周期号相比ProdercerRecord的属性更多,其中重点讲下偏移量,偏移量是分区中一条消息的唯一标识。消费者在每次调用poll方法时,则是根据偏移量去分区拉取相应的消息。而当一台消费者宕机时,会发生再均衡,将其负责的分区交给其他消费者处理,这时可以根据偏移量去继续从宕机前消费的位置开始。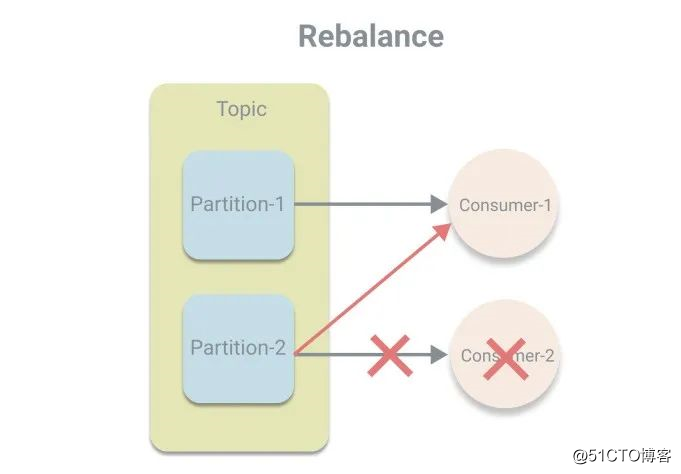
而为了应对消费者宕机情况,偏移量被设计成不存储在消费者的内存中,而是被持久化到一个Kafka的内部主题__consumer_offsets中,在Kafka中,将偏移量存储的操作称作提交。而消息者在每次消费消息时都将会将偏移量进行提交,提交的偏移量为下次消费的位置,例如本次消费的偏移量为x,则提交的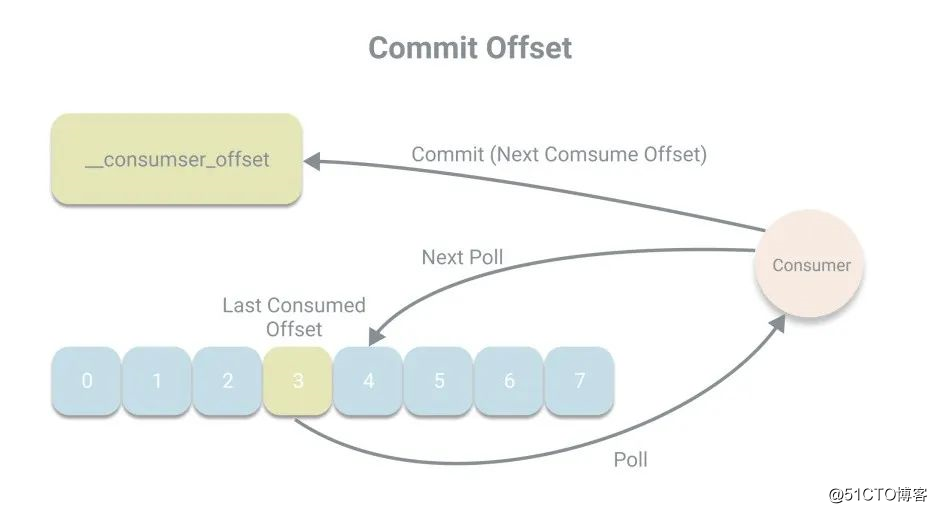 是x+1。
是x+1。
在代码中我们并没有看到显示的提交代码,那么Kafka的默认提交方式是什么?默认情况下,消费者会定期以auto_commit_interval_ms(5秒)的频率进行一次自动提交,而提交的动作发生于poll方法里,在进行拉取操作前会先检查是否可以进行偏移量提交,如果可以,则会提交即将拉取的偏移量。
下面我们看下这样一个场景,上次提交的偏移量为2,而当前消费者已经处理了2、3、4号消息,正准备提交5,但却宕机了。当发生再均衡时,其他消费者将继续从已提交的2开始消费,于是发生了重复消费的现象。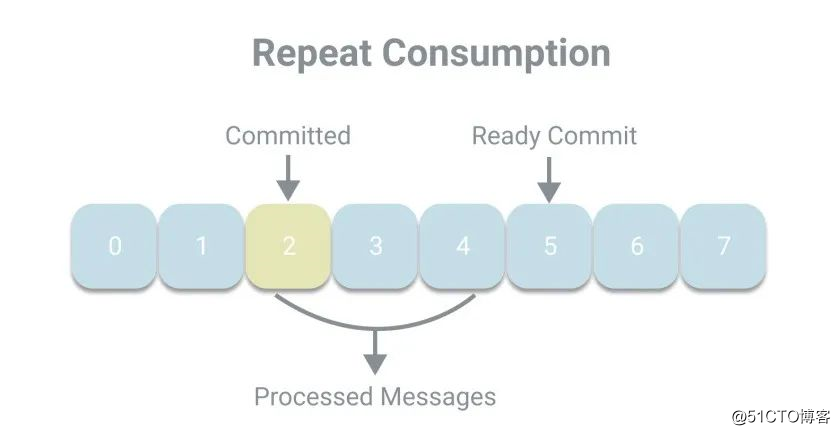
我们可以通过减小自动提交的时间间隔来减小重复消费的窗口大小,但这样仍然无法避免重复消费的发生。
按照线性程序的思维,由于自动提交是延迟提交,即在处理完消息之后进行提交,所以应该不会出现消息丢失的现象,也就是已提交的偏移量会大于正在处理的偏移量。但放在多线程环境中,消息丢失的现象是可能发生的。例如线程A负责调用poll方法拉取消息并放入一个队列中,由线程B负责处理消息。如果线程A已经提交了偏移量5,而线程B还未处理完2、3、4号消息,这时候发生宕机,则将丢失消息。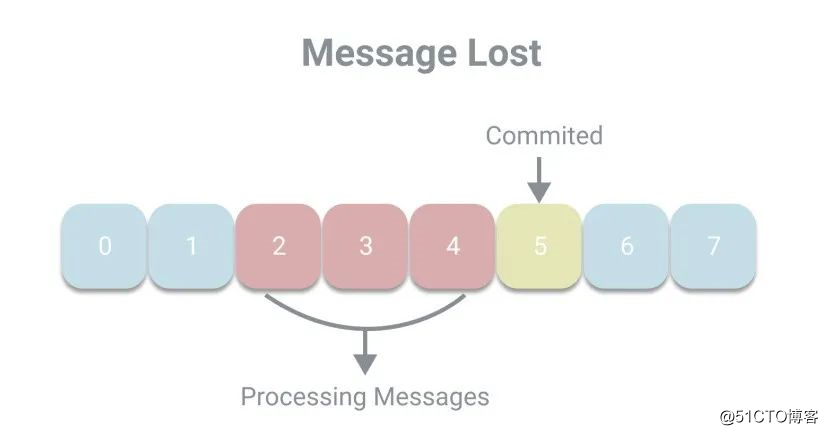
从上述场景的描述,我们可以知道自动提交是存在风险的。所以Kafka除了自动提交,还提供了手动提交的方式,可以细分为同步提交和异步提交,分别对应了KafkaConsumer中的commitSync和commitAsync方法。我们先尝试使用同步提交修改程序:
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
consumer.commitSync();;
}在处理完一批消息后,都会提交偏移量,这样能减小重复消费的窗口大小,但是由于是同步提交,所以程序会阻塞等待提交成功后再继续处理下一条消息,这样会限制程序的吞吐量。那我们改为使用异步提交:
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
consumer.commitAsync();;
}异步提交时,程序将不会阻塞,但异步提交在提交失败时也不会进行重试,所以提交是否成功是无法保证的。因此我们可以组合使用两种提交方式。在轮循中使用异步提交,而当关闭消费者时,再通过同步提交来保证提交成功。
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
consumer.commitAsync();
}
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}上述介绍的两种无参的提交方式都是提交的poll返回的一个批次的数据。若未来得及提交,也会造成重复消费,如果还想更进一步减少重复消费,可以在for循环中为commitAsync和commitSync传入分区和偏移量,进行更细粒度的提交,例如每1000条消息我们提交一次:
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
int count = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
// 偏移量加1
currentOffsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
if (count % 1000 == 0) {
consumer.commitAsync(currentOffsets, null);
}
count++;
}
}关于提交就介绍到这里。在使用消费者的代理中,我们可以看到poll方法是其中最为核心的方法,能够拉取到我们需要消费的消息。所以接下来,我们一起深入到消费者API的幕后,看看在poll方法中,都发生了什么,其实现如下:
public ConsumerRecords<K, V> poll(final Duration timeout) {
return poll(time.timer(timeout), true);
}在我们使用设置超时时间的poll方法中,会调用重载方法,第二个参数includeMetadataInTimeout用于标识是否把元数据的获取算在超时时间内,这里传值为true,也就是算入超时时间内。下面再看重载的poll方法的实现:
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
// 1. 获取锁并确保消费者没有关闭
acquireAndEnsureOpen();
try {
// 2.记录poll开始
this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
// 3.检查是否有订阅主题
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
do {
// 4.安全的唤醒消费者
client.maybeTriggerWakeup();
// 5.更新偏移量(如果需要的话)
if (includeMetadataInTimeout) {
updateAssignmentMetadataIfNeeded(timer, false);
} else {
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE), true)) {
log.warn("Still waiting for metadata");
}
}
// 6.拉取消息
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
// 7.如果拉取到了消息或者有未处理的请求,由于用户还需要处理未处理的消息
// 所以会再次发起拉取消息的请求(异步),提高效率
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.transmitSends();
}
// 8.调用消费者拦截器处理
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
// 9.释放锁
release();
// 10.记录poll结束
this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
}
}我们对上面的代码逐步分析,首先是第1步
acquireAndEnsureOpen方法,获取锁并确保消费者没有关闭,其实现如下:
private void acquireAndEnsureOpen() {
acquire();
if (this.closed) {
release();
throw new IllegalStateException("This consumer has already been closed.");
}
}其中acquire方法用于获取锁,为什么这里会要上锁。这是因为KafkaConsumer是线程不安全的,所以需要上锁,确保只有一个线程使用KafkaConsumer拉取消息,其实现如下:
private static final long NO_CURRENT_THREAD = -1L;
private final AtomicLong currentThread = new AtomicLong(NO_CURRENT_THREAD);
private final AtomicInteger refcount = new AtomicInteger(0);
private void acquire() {
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}用一个原子变量currentThread作为锁,通过cas操作获取锁,如果cas失败,即获取锁失败,表示发生了竞争,有多个线程在使用KafkaConsumer,则会抛出ConcurrentModificationException异常,如果cas成功,还会将refcount加一,用于重入。
再看第2、3步,记录poll的开始以及检查是否有订阅主题。然后进入do-while循环,如果没有拉取到消息,将在不超时的情况下一直轮循。
第4步,安全的唤醒消费者,并不是唤醒,而是检查是否有唤醒的风险,如果程序在执行不可中断的方法或是收到中断请求,会抛出异常,这里我还不是很明白,先放一下。
第5步,更新偏移量,就是我们在前文说的在进行拉取操作前会先检查是否可以进行偏移量提交。
第6步,pollForFetches方法拉取消息,其实现如下:
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
long pollTimeout = coordinator == null ? timer.remainingMs() :
Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
// 1.如果消息已经有了,则立即返回
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty()) {
return records;
}
// 2.准备拉取请求
fetcher.sendFetches();
if (!cachedSubscriptionHashAllFetchPositions && pollTimeout > retryBackoffMs) {
pollTimeout = retryBackoffMs;
}
Timer pollTimer = time.timer(pollTimeout);
// 3.发送拉取请求
client.poll(pollTimer, () -> {
return !fetcher.hasAvailableFetches();
});
timer.update(pollTimer.currentTimeMs());
// 3.返回消息
return fetcher.fetchedRecords();
}如果fetcher已经有消息了则立即返回,这里和下面将要讲的第7步对应。如果没有消息则使用Fetcher准备拉取请求然后再通过ConsumerNetworkClient发送请求,最后返回消息。
为啥消息会已经有了呢,我们回到poll的第7步,如果拉取到了消息或者有未处理的请求,由于用户还需要处理未处理的消息,这时候可以使用异步的方式发起下一次的拉取消息的请求,将数据提前拉取,减少网络IO的等待时间,提高程序的效率。
第8步,调用消费者拦截器处理,就像KafkaProducer中有ProducerInterceptor,在KafkaConsumer中也有ConsumerInterceptor,用于处理返回的消息,处理完后,再返回给用户。
第9、10步,释放锁和记录poll结束,对应了第1、2步。
对KafkaConsumer的poll方法就分析到这里。最后用一个思维导图回顾下文中较为重要的知识点: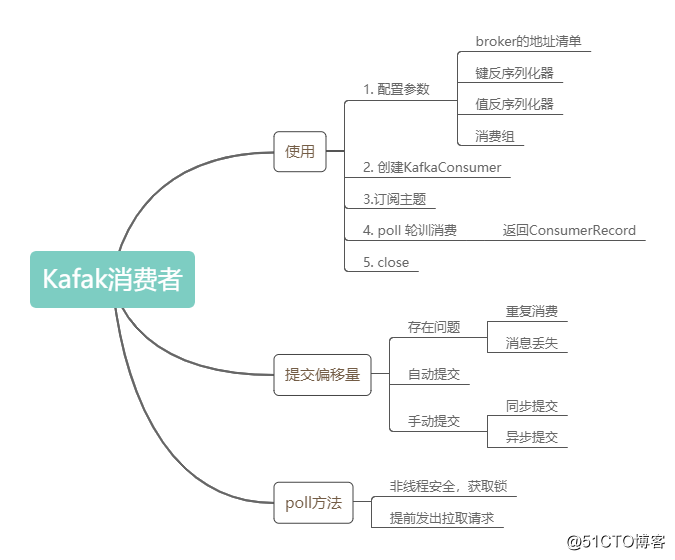
标签:重点 size long 一个队列 限制 duration 效率 技术 str
原文地址:https://blog.51cto.com/9167833/2544251