标签:图片 end 节点 evel amd priority building split inter
Spark源码编译官方文档:
用于编译源码的机器最好满足如下配置:
首先安装好JDK、Scala和Maven,由于安装都比较简单,本文就不演示了,我这里使用的JDK、Scala和Maven版本如下:
[root@spark01 ~]# java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)
[root@spark01 ~]# scala -version
Scala code runner version 2.12.12 -- Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc.
[root@spark01 ~]# mvn -v
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /usr/local/maven
Java version: 1.8.0_261, vendor: Oracle Corporation, runtime: /usr/local/jdk/1.8/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-1062.el7.x86_64", arch: "amd64", family: "unix"
[root@spark01 ~]# 打开如下链接,进入到Spark官网的下载页下载源码包:
选择相应版本的源码包进行下载,我这里下载的是3.0.1版本:
点击上图的链接,会进入一个镜像下载页,复制国内的镜像下载链接到Linux上使用wget命令进行下载:
[root@spark01 ~]# cd /usr/local/src
[root@spark01 /usr/local/src]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.0.1/spark-3.0.1.tgz解压下载好的源码包,并进入解压后的目录下:
[root@spark01 /usr/local/src]# tar -zxvf spark-3.0.1.tgz
[root@spark01 /usr/local/src]# cd spark-3.0.1
[root@spark01 /usr/local/src/spark-3.0.1]# ls
appveyor.yml bin common CONTRIBUTING.md data docs external hadoop-cloud LICENSE mllib NOTICE project R repl sbin sql tools
assembly build conf core dev examples graphx launcher licenses mllib-local pom.xml python README.md resource-managers scalastyle-config.xml streaming
[root@spark01 /usr/local/src/spark-3.0.1]#配置一个环境变量,让Maven在编译时可以使用更多的内存:
[root@spark01 /usr/local/src/spark-3.0.1]# vim /etc/profile
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=1g"
[root@spark01 /usr/local/src/spark-3.0.1]# source /etc/profile如果你使用的Hadoop是CDH发行版,那么需要在Maven的settings.xml添加CDH仓库配置:
<mirrors>
<!-- 配置阿里云的中央镜像仓库 -->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
...
<profiles>
<!-- 通过profile配置cloudera仓库 -->
<profile>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</profile>
</profiles>
<!-- 激活profile -->
<activeProfiles>
<activeProfile>cloudera-profile</activeProfile>
</activeProfiles>然后执行如下命令编译Spark源码:
[root@spark01 /usr/local/src/spark-3.0.1]# mvn -Pyarn -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.16.2 -DskipTests clean package -X-Pyarn参数,如果需要与Hive集成则必须执指定-Phive和-Phive-thriftserver,在Spark 3.0.1版本中默认支持的Hive版本是2.3.7,另外一个支持的版本是1.2.1,需使用-Phive-1.2参数来指定如果你需要修改Scala的版本,则需要在编译前执行如下命令指定Scala的版本,例如指定Scala的版本为2.13:
[root@spark01 /usr/local/src/spark-3.0.1]# dev/change-scala-version.sh 2.13如果你需要编译打包成官方那种可以分发的二进制压缩包,则需要使用如下命令,我这里使用的就是这种方式:
[root@spark01 /usr/local/src/spark-3.0.1]# dev/make-distribution.sh --name 2.6.0-cdh5.16.2 --pip --r --tgz --mvn mvn -Psparkr -Phive -Phive-thriftserver -Pmesos -Pyarn -Pkubernetes -Dhadoop.version=2.6.0-cdh5.16.2 -X--pip和--r参数将会使用pip和R一起构建Spark,所以需要事先准备好R和Python环境,这两个参数是可选项不需要可以不指定。--mvn用于指定本地的mvn命令,否则会使用自带的mvn编译打包完成后,当前目录下会多出一个.tgz文件,后续其他机器也要安装Spark只需要把这个包分发过去即可,就不需要重复编译了:
[root@spark01 /usr/local/src/spark-3.0.1]# ll -h |grep spark
-rw-r--r--. 1 root root 266M 10月 26 09:45 spark-3.0.1-bin-2.6.0-cdh5.16.2.tgz
[root@spark01 /usr/local/src/spark-3.0.1]# 如果遇到依赖下载很慢,或卡在依赖下载上,并且控制台输出如下:
Downloading from gcs-maven-central-mirror解决方法是修改Spark源码目录下的pom.xml文件,在文件中查找所有的“gcs-maven-central-mirror”,然后将其url改为阿里云的仓库地址。如下:
<url>https://maven.aliyun.com/repository/public/</url>编译过程中可能会出现找不到git命令,只需要安装该命令即可:
$ yum install -y git如果你的hadoop版本低于2.6.4此时编译到yarn模块时会报错,官方有提供解决方法:
主要就是修改源码,该源码文件路径如下:
[root@spark01 /usr/local/src/spark-3.0.1]# vim resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala在文件中搜索到如下代码:
sparkConf.get(ROLLED_LOG_INCLUDE_PATTERN).foreach { includePattern =>
try {
val logAggregationContext = Records.newRecord(classOf[LogAggregationContext])
logAggregationContext.setRolledLogsIncludePattern(includePattern)
sparkConf.get(ROLLED_LOG_EXCLUDE_PATTERN).foreach { excludePattern =>
logAggregationContext.setRolledLogsExcludePattern(excludePattern)
}
appContext.setLogAggregationContext(logAggregationContext)
} catch {
case NonFatal(e) =>
logWarning(s"Ignoring ${ROLLED_LOG_INCLUDE_PATTERN.key} because the version of YARN " +
"does not support it", e)
}
}
appContext.setUnmanagedAM(isClientUnmanagedAMEnabled)
sparkConf.get(APPLICATION_PRIORITY).foreach { appPriority =>
appContext.setPriority(Priority.newInstance(appPriority))
}
appContext
}将其修改为:
sparkConf.get(ROLLED_LOG_INCLUDE_PATTERN).foreach { includePattern =>
try {
val logAggregationContext = Records.newRecord(classOf[LogAggregationContext])
// These two methods were added in Hadoop 2.6.4, so we still need to use reflection to
// avoid compile error when building against Hadoop 2.6.0 ~ 2.6.3.
val setRolledLogsIncludePatternMethod =
logAggregationContext.getClass.getMethod("setRolledLogsIncludePattern", classOf[String])
setRolledLogsIncludePatternMethod.invoke(logAggregationContext, includePattern)
sparkConf.get(ROLLED_LOG_EXCLUDE_PATTERN).foreach { excludePattern =>
val setRolledLogsExcludePatternMethod =
logAggregationContext.getClass.getMethod("setRolledLogsExcludePattern", classOf[String])
setRolledLogsExcludePatternMethod.invoke(logAggregationContext, excludePattern)
}
appContext.setLogAggregationContext(logAggregationContext)
} catch {
case NonFatal(e) =>
logWarning(s"Ignoring ${ROLLED_LOG_INCLUDE_PATTERN.key} because the version of YARN " +
"does not support it", e)
}
}
appContext
}如果编译过程中报错如下,原因是本地仓库中有些依赖下载不完整:
was cached in the local repository, resolution will not be reattempted until the update interval of nexus has elapsed or updates are forced.lastUpdated文件全部删除,重新执行maven编译命令,另一种则是在maven编译命令中增加一个-U参数将编译出来的二进制压缩包,解压到合适的目录下:
[root@spark01 /usr/local/src/spark-3.0.1]# tar -zxvf spark-3.0.1-bin-2.6.0-cdh5.16.2.tgz -C /usr/local进入解压后的目录下,目录结构如下:
[root@spark01 /usr/local/src/spark-3.0.1]# cd /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2/
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# ls
bin conf data examples jars kubernetes python R README.md RELEASE sbin yarn
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# 配置环境变量:
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# vim /etc/profile
export SPARK_HOME=/usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2
export PATH=$PATH:$SPARK_HOME/bin
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# source /etc/profile使用local模式进入spark-shell,如下能正常进入代表Spark Local模式环境是正常的:
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# spark-shell --master local[2]
20/10/26 17:28:39 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark‘s default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://spark01:4040
Spark context available as ‘sc‘ (master = local[2], app id = local-1603704523817).
Spark session available as ‘spark‘.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ ‘_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.1
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_261)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 然后使用浏览器访问该机器的4040端口,可以进入Spark的控制台页面:
官方文档:
Spark Standalone模式架构与Hadoop HDFS或YARN的架构很类似,都是一个master + n个worker这种架构。如下图所示: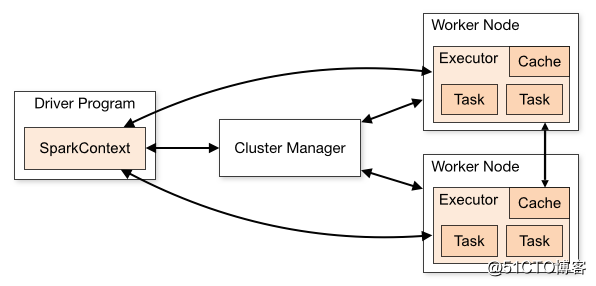
要以Standalone模式运行Spark,需要编辑配置文件,配置几个配置项。如下所示:
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# cp conf/spark-env.sh.template conf/spark-env.sh
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# vim conf/spark-env.sh
# Options for the daemons used in the standalone deploy mode
# 指定master的host
SPARK_MASTER_HOST=spark01
# 指定worker可使用的CPU核心数
SPARK_WORKER_CORES=2
# 指定worker可使用的内存
SPARK_WORKER_MEMORY=2g
# 指定在一个节点上启动多少个worker实例
SPARK_WORKER_INSTANCES=1然后就可以执行如下脚本启动master和worker了:
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2/logs/spark-root-org.apache.spark.deploy.master.Master-1-spark01.out
localhost: Warning: Permanently added ‘localhost‘ (ECDSA) to the list of known hosts.
root@localhost‘s password:
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-spark01.out
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# 启动成功后使用浏览器访问该机器的8080端口,可以进入到Master节点的控制台页面: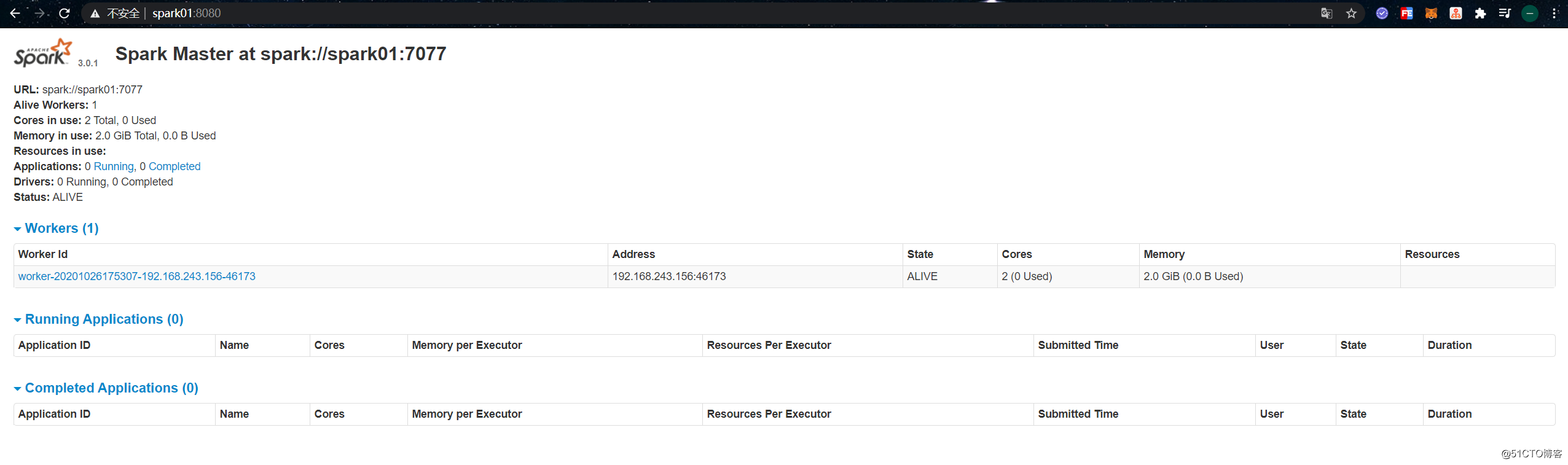
如果有多个slave节点,可以在conf/slaves文件中进行配置:
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# cp conf/slaves.template conf/slaves
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# vim conf/slaves
spark01
spark02
spark03当启动了Standalone集群后,可以通过如下方式让spark-shell连接到该集群:
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# bin/spark-shell --master spark://spark01:7077此时在Master控制台页面上可以看到有一个Application处于Running状态: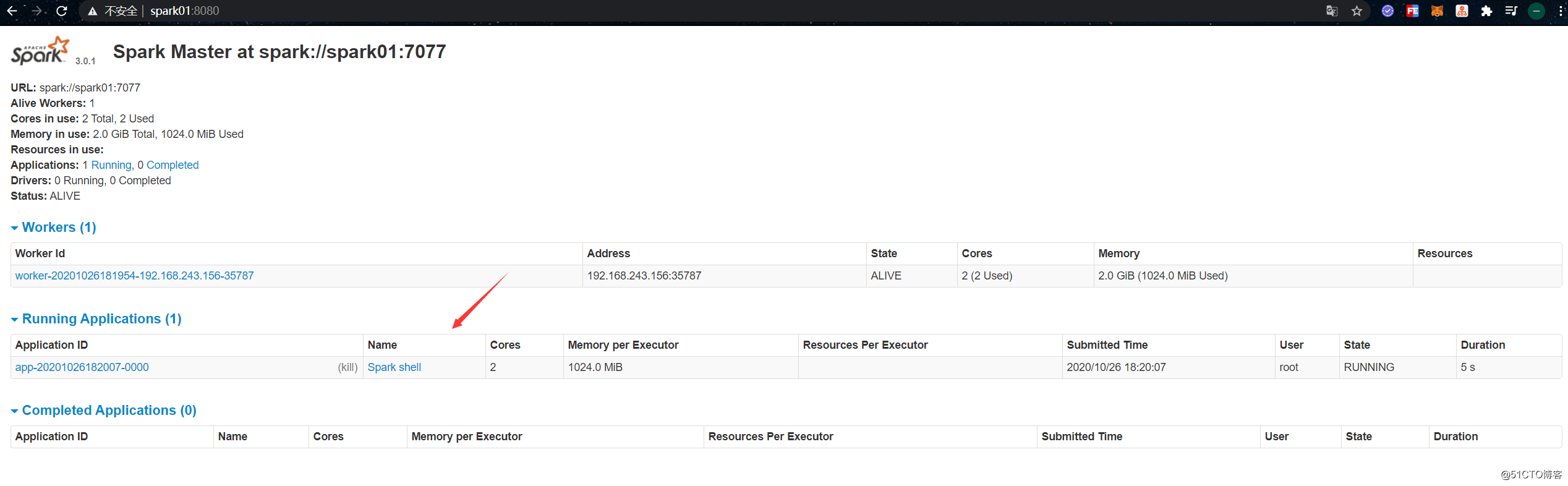
简单演示下使用Spark对一个文本文件的内容做词频统计(WordCount),该文件的内容如下:
[root@spark01 ~]# cat word-count.txt
hello,world,hello
hello,world
welcome
[root@spark01 ~]# 进入spark-shell,使用scala语法实现词频统计:
[root@spark01 /usr/local/spark-3.0.1-bin-2.6.0-cdh5.16.2]# bin/spark-shell --master spark://spark01:7077
scala> val file = spark.sparkContext.textFile("file:///root/word-count.txt") // 加载文件系统中的文件
file: org.apache.spark.rdd.RDD[String] = file:///root/word-count.txt MapPartitionsRDD[1] at textFile at <console>:23
scala> val wordCounts = file.flatMap(line => line.split(",")).map((word => (word, 1))).reduceByKey(_ + _) // 执行WordCount统计
wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:25
scala> wordCounts.collect // 输出统计结果
res0: Array[(String, Int)] = Array((hello,3), (welcome,1), (world,2))
scala> 标签:图片 end 节点 evel amd priority building split inter
原文地址:https://blog.51cto.com/zero01/2544237