标签:cap原理 分区 数据 分布式锁 参考 文章 女朋友 团队合作 block
一篇文章带你深入理解Zookeeper本文来自作者投稿,作者:林湾村龙猫,Hollis做了一些修改和补充。
随着互联网技术的发展,大型网站需要的计算能力和存储能力越来越高。网站架构逐渐从集中式转变成分布式。
虽然分布式和集中式系统相比有很多优势,比如能提供更强的计算、存储能力,避免单点故障等问题。但是由于采用分布式部署的方式,就经常会出现网络故障等问题,并且如何在分布式系统中保证数据的一致性和可用性也是一个比较关键的问题。
分布式的工作方式有点类似于团队合作。当有一项任务分配到某个团队之后,团队内部的成员开始各司其职,然后把工作结果统一汇总给团队主管,由团队主管再整理团队的工作成果汇报给公司。
但是,日常工作中,如果两个员工或用户对某件事产生了分歧,通常我们的做法是找上级,去做数据和信息的同步。
那么对于我们的服务呢,多个节点之间数据不同步如何处理?
对于分布式集群来说,这个时候,我们通常一个能够在各个服务或节点之间进行协调的服务或中间人
架构设计中,没有一个问题不能通过增加一个抽象层来解决的,如果有,那就增加两层。
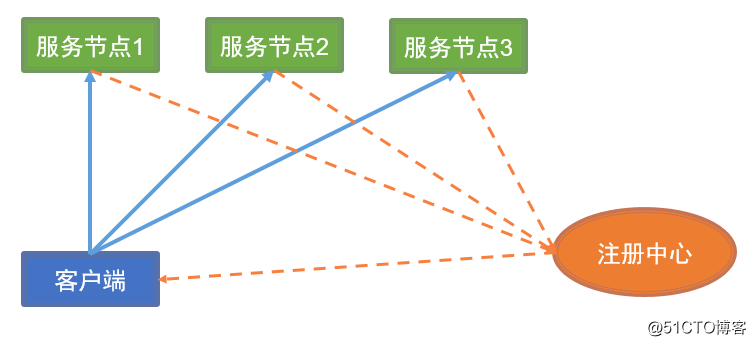
集群管理
集群管理
我们可以一起看看,协调服务中的佼佼者--ZooKeeper
zookeeper起源
zoo
最初,在Hadoop生态中,会存在很多的服务或组件(比如hive、pig等),每个服务或组件之间进行协调处理是很麻烦的一件事情,急需一种高可用高性能数据强一致性的协调框架。
因此雅虎的工程师们创造了这个中间程序,但中间程序的命名却愁死了开发人员,突然想到hadoop中的大多是动物名字,似乎缺乏一个管理员,这个程序的功能有是如此的相似。因此zookeeper诞生。
Zookeeper是一个开放源码的分布式服务协调组件,是Google Chubby的开源实现。是一个高性能的分布式数据一致性解决方案。他将那些复杂的、容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并提供一系列简单易用的接口给用户使用。
zookeeper提供了哪些特性,以便于能够很好的完成协调能力的处理呢?
功能与特性
数据存储
zookeeper提供了类似Linux文件系统一样的数据结构。每一个节点对应一个Znode节点,每一个Znode节点都可以存储1MB(默认)的数据。
客户端对zk的操作就是对Znode节点的操作。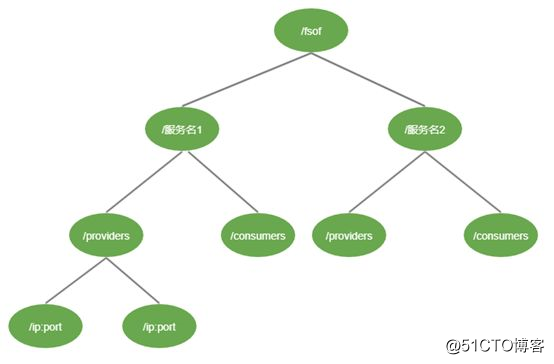
zookeeper数据结构
zookeeper数据结构
每一个Znode节点又根据节点的生命周期与类型分为4种节点。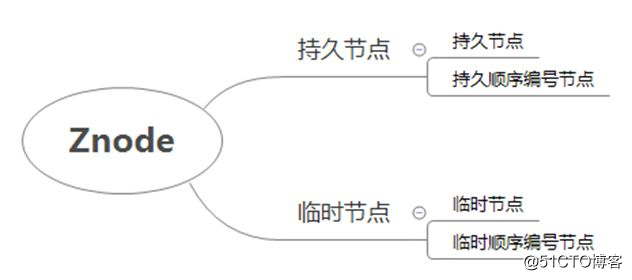
zookeeper节点
zookeeper除了提供对Znode节点的处理能力,还提供了对节点的变更进行监听通知的能力。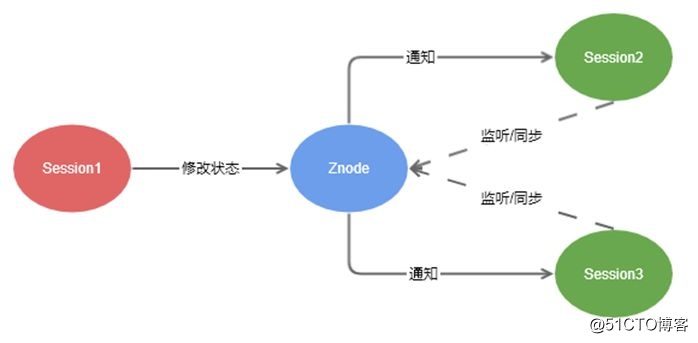
zookeeper监听机制
监听机制的步骤如下:
1.任何session(session1,session2)都可以对自己感兴趣的znode监听。
2.当znode通过session1对节点进行了修改。
3.session1,session2都会收到znode的变更事件通知。
节点常见的事件通知有:
一次监听事件,只会被触发一次,如果想要监听到znode的第二次变更,需要重新注册监听。
到这里,我们了解到zookeeper提供的能力,那我们在哪些场景可以使用它?如何使用它呢?
应用场景
zookeeper用得比较多的地方可能是,微服务的集群管理与服务注册与发现。
注册中心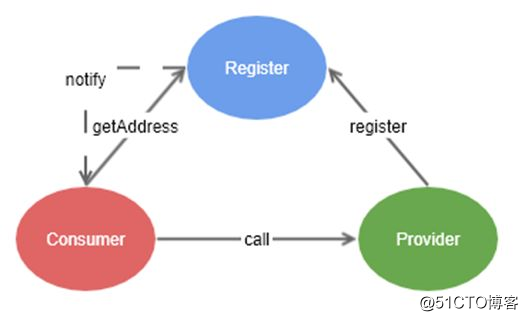
注册中心模型
注册中心的对比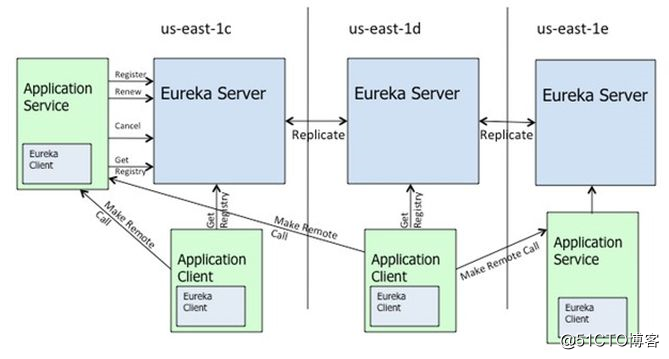
Eureka架构图
通过上面的架构图,可以发现Eureka不同于zk中的节点,Eureka中的节点每一个节点对等。是个AP系统,而不是zk的CP系统。在注册中心的应用场景下,相对于与强数据一致性,更加关心可用性。
分布式锁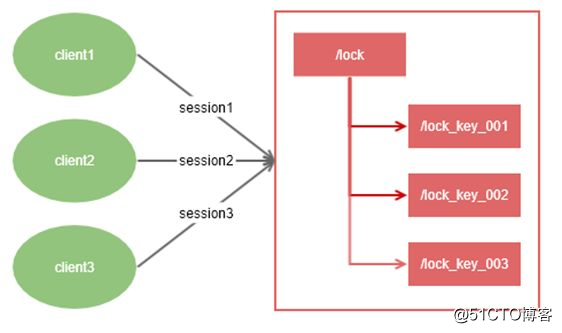
分布式锁
分布式锁的对比
分布式锁可以参考文章: 分布式锁(redis/mysql)、分布式锁的几种实现方式
具体差异比较:
从理解的难易程度角度(从低到高)
数据库 > 缓存(Redis) > Zookeeper
从实现的复杂性角度(从低到高)
Zookeeper >= 缓存(Redis) > 数据库
从性能角度(从高到低)
缓存(Redis) > Zookeeper >= 数据库
从可靠性角度(从高到低)
Zookeeper > 缓存(Redis) > 数据库
集群管理与master选举
集群管理与master选举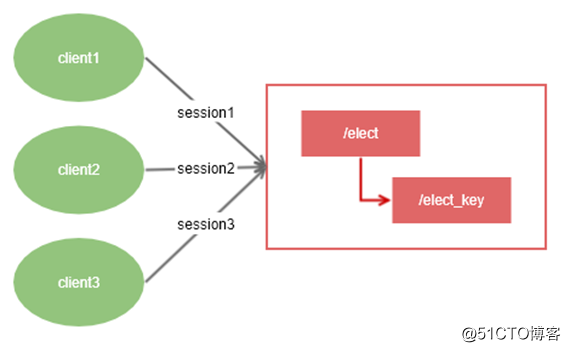
有人说,zookeeper可以做分布式配置中心、分布式消息队列,看到这里的小伙伴们,你们觉得合适么?
到这里,可以基本上满足基于zk应用开发的理论知识储备。
高性能高可用强一致性保障
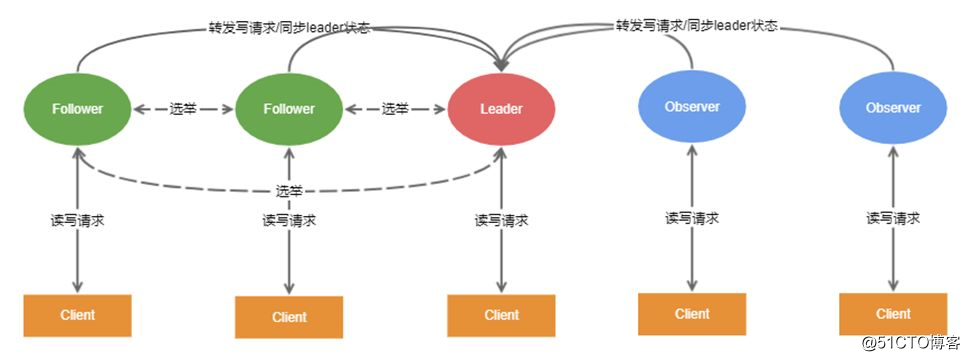
高性能-分布式集群
zookeeper集群部署
高性能,我们通常想到的是通过集群部署来突破单机的性能瓶颈。对于zk来说,就是通过部署多个节点共同对外提供服务,来提供读的高性能。
通过集群的部署,根据CAP原理,这样,可能导致同一个数据在不同节点上的数据不一致。zookeeper通过zab原子广播协议来保证数据在每一个节点上的一致性。原子广播协议(类似2PC提交协议)大概分为3个步骤。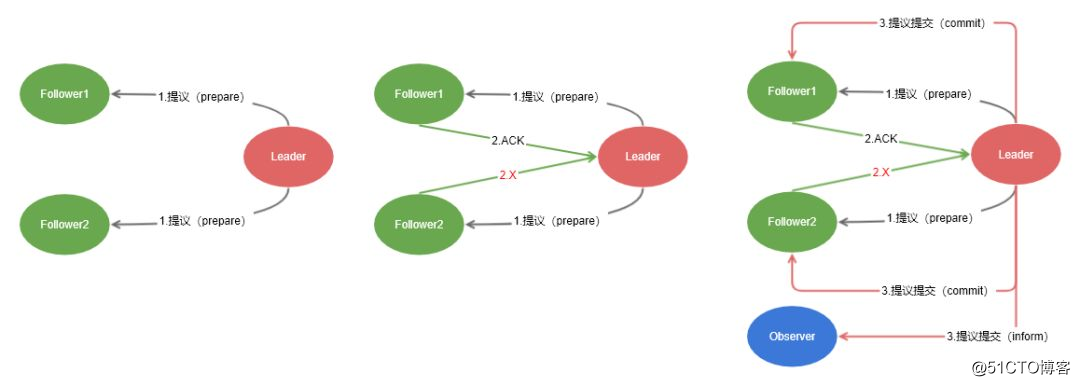
zab原子广播协议
Leader收到过半的Follower同意,自己先添加事务。然后对所有的Learner节点发送提交事务请求。
需要说明的是,zookeeper对数据一致性的要求是:
在整个集群中,写请求都集中在一个Leader节点上,如果Leader节点挂了咋办呢?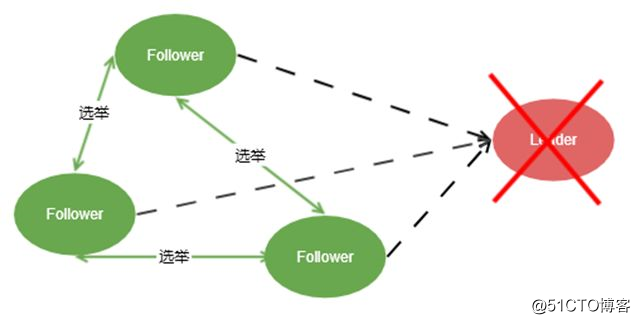
zab崩溃恢复协议
当集群初始化或Follower无法联系上Leader节点的时候,每个Follower开始进入选举模式。选举步骤如下:
选举原则:谁的数据最新,谁就有优先被选为Leader的资格。
举个例子,假如现在zk集群有5个节点,然后挂掉了2个节点。剩余节点S3,S4,S6开始进行选举,他们的最大事务ID分别是6,2,6。定义投票结构为(投票的节点ID,被投节点ID,被投节点最大事务ID)。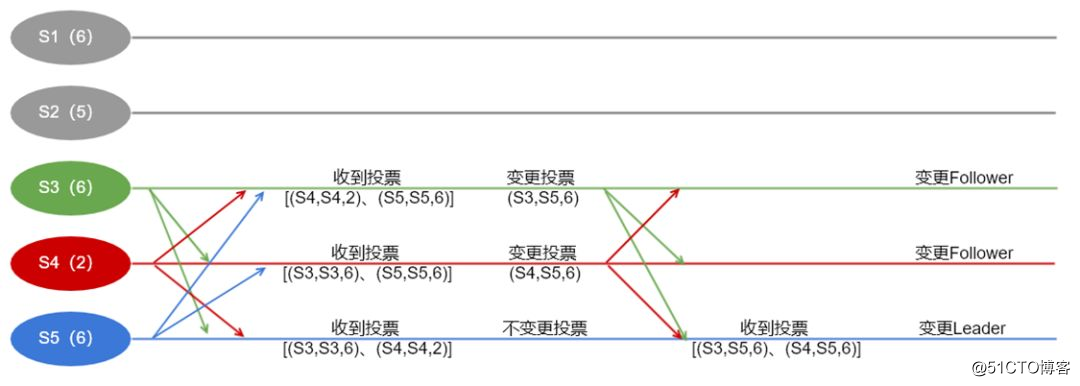
zookeeper选举举例
数据的持久化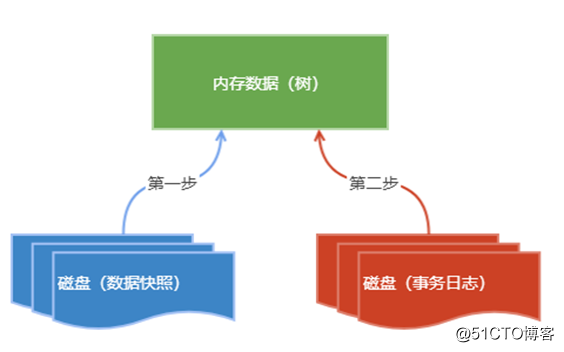
数据的恢复与持久化
Zookeeper和CAP的关系
前面提到了zk在可用性、数据一致性、性能等方面都表现的很优秀,也介绍了其中的原理。
但是分布式系统的CAP理论告诉我们:任何软件系统都无法同时满足一致性、可用性以及分区容错性。
那么,Zookeeper其实也是一个分布式系统,那么也就要满足CAP理论,也就是说,虽然在各个方面,ZK可以说是做了很多努力,但是在极端情况下,Zookeeper也需要在这三者之间有一些权衡,那么Zookeeper在CAP中是如何取舍的呢?
ZooKeeper是个CP(一致性+分区容错性)的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,但是它不能保证每次服务请求的可用性(注:也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。
但是别忘了,ZooKeeper是分布式协调服务,它的职责是保证数据(注:配置数据,状态数据)在其管辖下的所有服务之间保持同步、一致,所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了。
如果是AP的,那么将会带来恐怖的后果(注:ZooKeeper就像交叉路口的信号灯一样,你能想象在交通要道突然信号灯失灵的情况吗?)。
而且, 作为ZooKeeper的核心实现算法 Zab,就是解决了分布式系统下数据如何在多个服务之间保持同步问题的。
如果 ZooKeeper下所有节点都断开了,或者集群中出现了网络分割的故障(注:由于交换机故障导致交换机底下的子网间不能互访)。
那么ZooKeeper 会将它们都从自己管理范围中剔除出去,外界就不能访问到这些节点了,即便这些节点本身是“健康”的,可以正常提供服务的;所以导致到达这些节点的服务请求被丢失了。(Zookeeper介绍(二)——Zookeeper概述)
那么,再来深入原理看一下Zookeeper是如何在CAP之间做权衡的呢?
感悟
最后,说说在整个学习和使用zk过程中的一个感悟吧。

如果你喜欢本文。
请长按二维码,关注Hollis
标签:cap原理 分区 数据 分布式锁 参考 文章 女朋友 团队合作 block
原文地址:https://blog.51cto.com/13626762/2544483