标签:alt else mysq ice something rup 基本概念 查询 隔离
背景上回我们说到Nacos的注册中心,我们讲了注册中心的一致性协议,订阅和注册的原理,有兴趣的可以看一下上一篇文章:你应该了解的Nacos注册中心。在Nacos中还有一个功能特别重要那就是配置中心,在这里先不具体介绍配置中心是什么,先来忆苦思甜一波。
在我们最开始做一些简单的学习项目的时候,我们会遇到一些需要配置的东西,比如数据库连接池大小,用户的黑名单等等,我们都把这些东西写死在代码里面,比如if(userId == 123){do something},这种代码在项目里随处可见。后来参加工作了,发现这种写法并没有将配置很好的统一管理起来,配置地方随处可见,并且无法根据代码环境去进行调整,比如线上和线下都只能使用同一个配置,虽然可以通过if,else的方式,但是这个非常麻烦,所以在工作就开始使用xml,yaml等方式在文件里面进行配置,在不同的运行环境读取不同的配置。这种方式基本满足了大部分的需求,但是后面遇到了一个需要动态去修改这些配置的情况,如果通过文件的方式我们就只能修改文件然后重新上线服务,这样是非常麻烦的,所以就诞生了配置中心。
我们在这里可以想想,如果你要实现配置中心,应该具备哪些功能呢?我这里列举一些:
其实在开源的项目中有挺多配置中心的开源的比如spring cloud config, Apollo等等,其中Apollo是携程开源的配置中心,在业界也是非常出名,我们这边文章主要还是介绍Nacos的配置中心,当然有兴趣的同学可以下来自行查看其他注册中心相关介绍。
同样的我们首先也先介绍一下和注册中心相关的一些基本名词概念:
配置快照:Nacos 的客户端 SDK 会在本地生成配置的快照。当客户端无法连接到 Nacos Server 时,可以使用配置快照显示系统的整体容灾能力。配置快照类似于 Git 中的本地 commit,也类似于缓存,会在适当的时机更新,但是并没有缓存过期(expiration)的概念。
配置中心的架构图如下: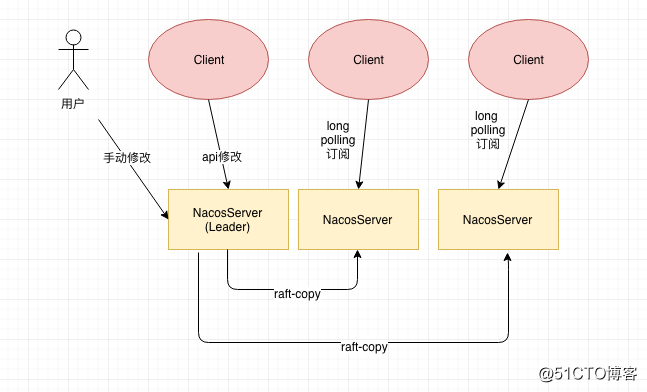
配置中心最为关键的就是如何去做好存储,一般我们存储就两种方式, 要么全内存存储,能保证性能非常高,但是维护不同机器内存一致性复杂度比较高,还有一种就是使用数据库,内存里面不维护任何状态,每一台机器都可以进行写入操作,这个复杂度比较低,不需要考虑一致性的问题,但是由于所有的读写都会走数据库所以性能就不能保证。在Nacos中对这两种存储方式做了一些改进,实现了既保证了性能又保证了复杂度一致性。
在Nacos1.3之后提供了mysql 和 raft + derby两种存储方式,接下来介绍一一介绍一下这两种存储方式。
nacos最开始提供的就是mysql的方式,所有机器都可以进行读写,没有主备之分,如下图所示: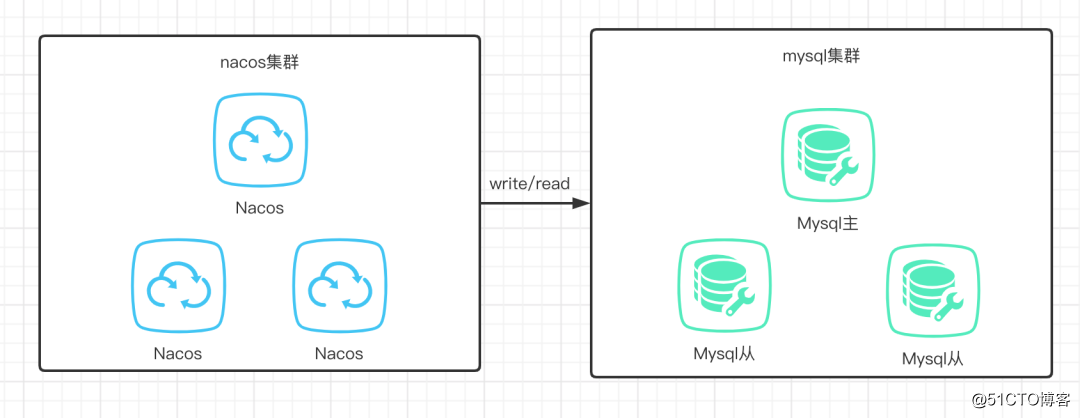
数据的读写都是直接走Mysql,具体的代码在ExternalStoragePersistServiceImpl中,其中直接使用的JdbcTemplate,这里就不详细把代码展现出来介绍了,有兴趣的可以直接去这里看。
如果只是使用mysql,有同学会提出问题,只使用mysql如何才能保证数据库性能不会成为瓶颈呢?最简单的方法就是使用高配置的Mysql,用钱给我干上去,很明显这个不是很靠谱,只适用于土豪玩家。那么怎么去做这种优化呢?一般做业务的同学通常会在Mysql前面放一层缓存层,比如redis,memcached等等。
在Nacos中同样的也使用了缓存这个概念帮助我们缓解数据库压力。但是和普通的缓存稍微有点不同:
在ConfigService中有一个HashMap缓存了所有Config的元数据(MD5,类型这些数据)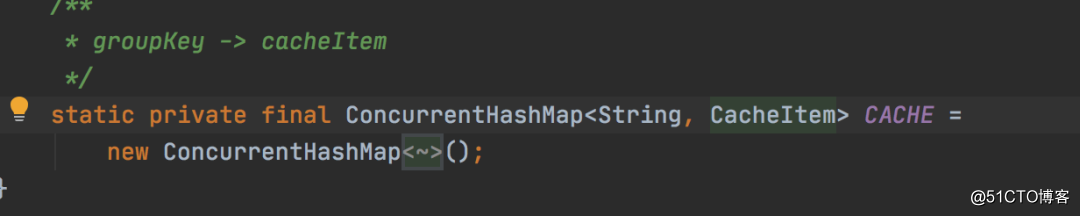
但是对于具体存储的值我们不会直接放在内存,而是存储到了本地磁盘,这么做的好处是因为我们的config所配置的值我们不能保证他的大小,如果每个config的值都很大,那么我们的内存必然会不足,这个时候Nacos和Apollo 两个开源中间件给出两种解法:
Nacos使用的是全量缓存元数据到内存,具体的值存储到磁盘空间,但是会存在一个问题,那就是当一台机器的数据发生变更,其他机器的内存怎么变更呢?这就需要我们的全量异步通知,在每一次修改数据的时候都会发送一个ConfigDataChage事件,然后本机接受并进行处理,然后发送这个变更消息到其他的所有机器上。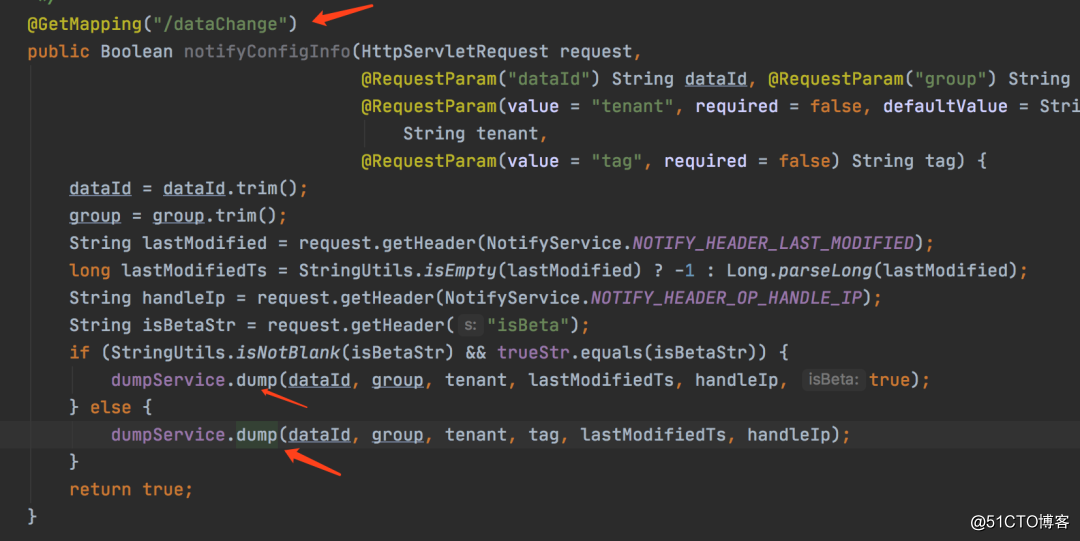
其他机器收到这个变更通知之后,会进行一次dump操作: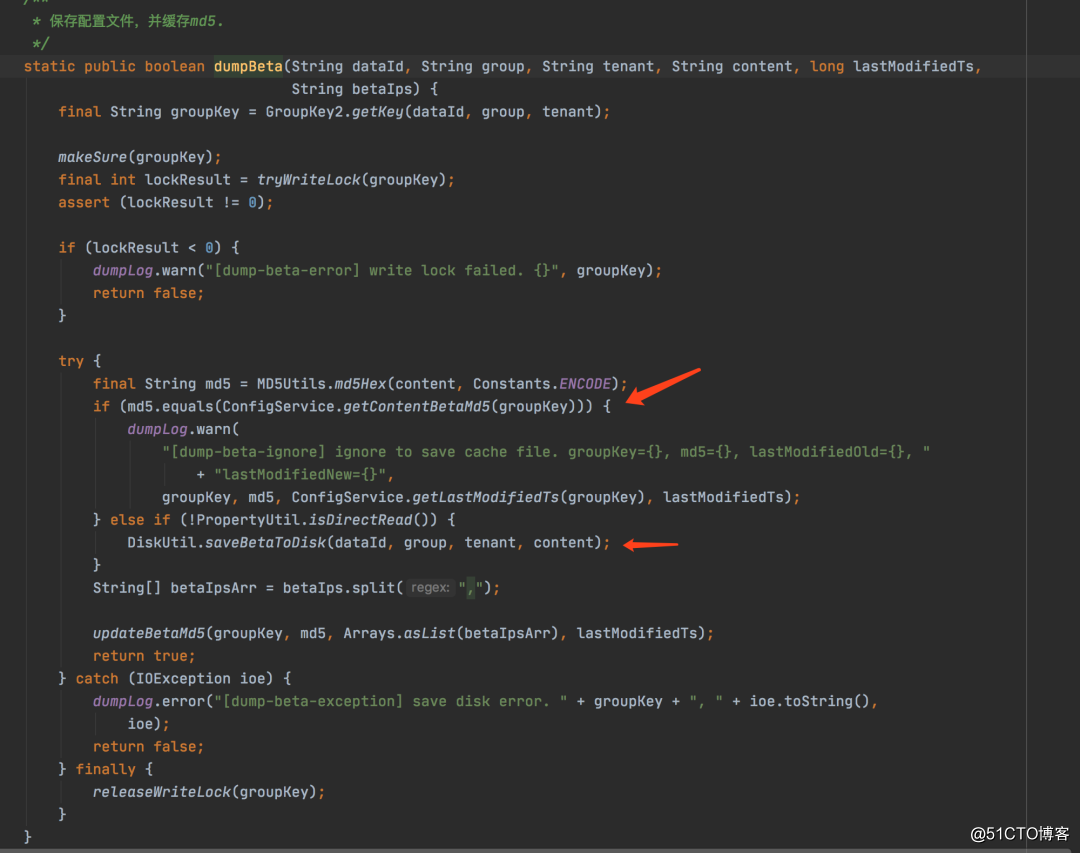
会先查询元数据中的MD5,MD5其实也是根据我们配置中的值算出来的,所以能进行快速判断这一次时候发生了值的变更,如果发生变更,我们就将这个值存储到磁盘上。
如果我们这个机器是新启动的,这个时候其实就不会存在任何缓存以及dump文件,那么DumpService会遍历数据库的所有数据,全量的都缓存到机器上,以便我们使用。
Nacos在1.3.0之后提供了一个新的存储模式,那就是使用raft协议保证数据一致性,使用apache derby进行内嵌的数据存储。提供这种方式的目的是减少用户维护mysql数据库集群的成本,并且简化了集群部署的成本,部署Nacos的时候直接打包Nacos镜像就好,不需要再单独部署一套数据库。
在Nacos中使用的是sofa-jraft,这个是蚂蚁开源的一个java版本高性能的raft实现,不熟悉raft的同学可以阅读以下raft的论文,了解过raft的同学应该都知道raft非常强化Leader的概念:
Leader 还需向所有 followers 主动发送心跳维持领导地位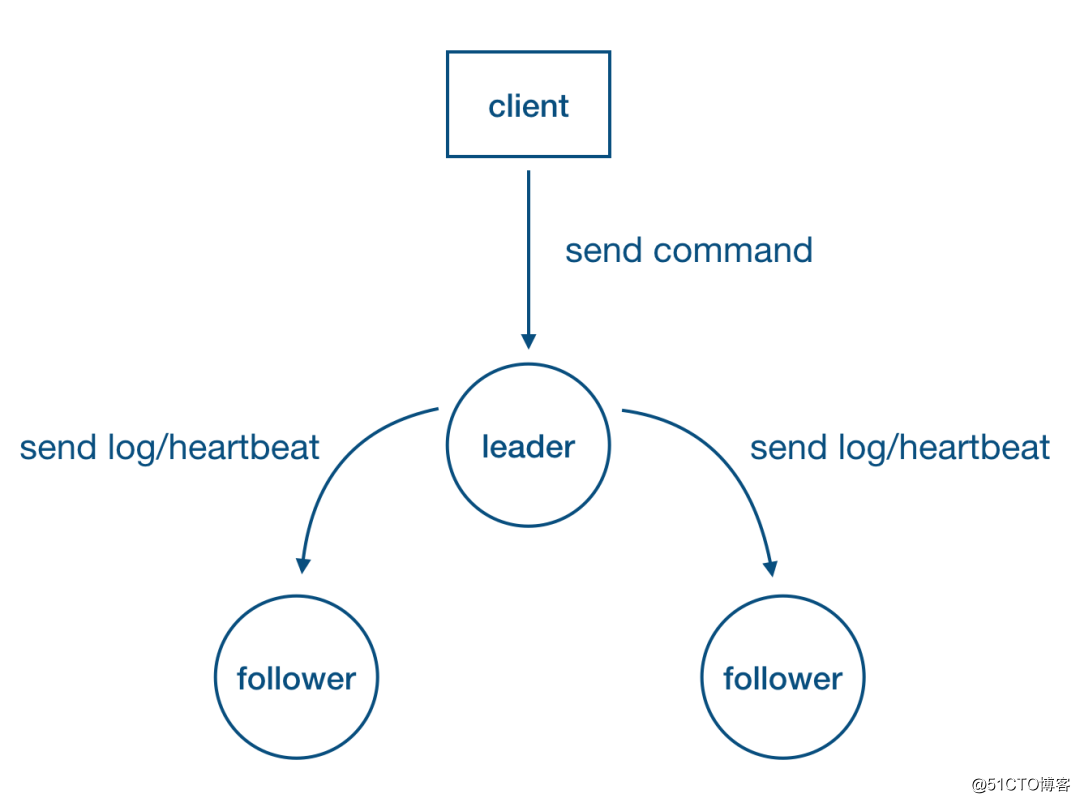
我们发现所有的事情都和leader相关,那么我们的性能必定被限制在leader上面,所以在Nacos中选择了对raft本身有大量优化的sofa-jraft,在sofa-jraft中做了如下的优化:
批量化:批量化操作是很多系统的一个优化策略,在jraft中同样的也采用了批量化操作,通过disruptor 的 MPSC 模型批量消费,实现了下面的一些批量操作,提升了很多的性能:
批量应用到状态机
pipeline复制: pipeline是一种管道技术,帮助我们不再和以前请求-响应模型一样,他可以持续往管道中放入请求,过程中而不需要等待请求的回复,在最后再一并读取结果即可。在jraft中开启pipeline性能会提升30%。
并行化:leader持久化log和发送Log到follower是并行的,发送到不同的follower也是并行的。
Apache Derby也是一个Java编写的轻量级数据库,Nacos通过这样的设计其实是构建了一个轻量级的分布式数据库,在每一台的机器上都会有一个保存数据的数据库,然后通过raft协议保证所有机器数据的一致性。
内嵌数据库的方式并不比Mysql的方式更好,在性能上Mysql那种方式因为存了很多缓存,并且content也保存到磁盘上,读取的时候基本不会走库,所以Mysql的方式其实更好,但是内嵌数据库的方式在运维部署的方式上是非常占优的。这里如何取舍需要用户自己进行一个选择
我们在上一节说到Nacos注册中心中的订阅是通过udp广播+定时轮训来获取到,而在配置中心中采用的是长轮训的方式进行订阅变更,为什么这两个实现订阅会采用不同的方式来实现呢?我们注册中心中所保存的数据都是小数据比如节点的Ip,端口等信息,但是我们在配置中心中你不能控制配置的大小,比如一个服务订阅了100个配置,每个配置的数据大小是1M,如果按照定时轮训的做法每次会拉100M的数据,显然是不靠谱的,所以这里采用了长轮训的方式,具体长轮训的方式如下:
通过这样的方式,我们每次请求量都会很少,只有在数据真正更新的时候才会将真正的数据返回给我们。
我们可能有这样的一个需求,我们需要验证某个配置是否对业务上有影响,通常的配置中心都是直接修改,所有机器全量都会被更新,如果这个配置出现问题,那么就会全量的出现故障。在Nacos中提供了一个灰度的功能,我们可以将某个配置只给某一些机器使用,这样就可以完成一些小流量验证。
在Nacos中灰度发布也叫做beta发布,如下图所示:
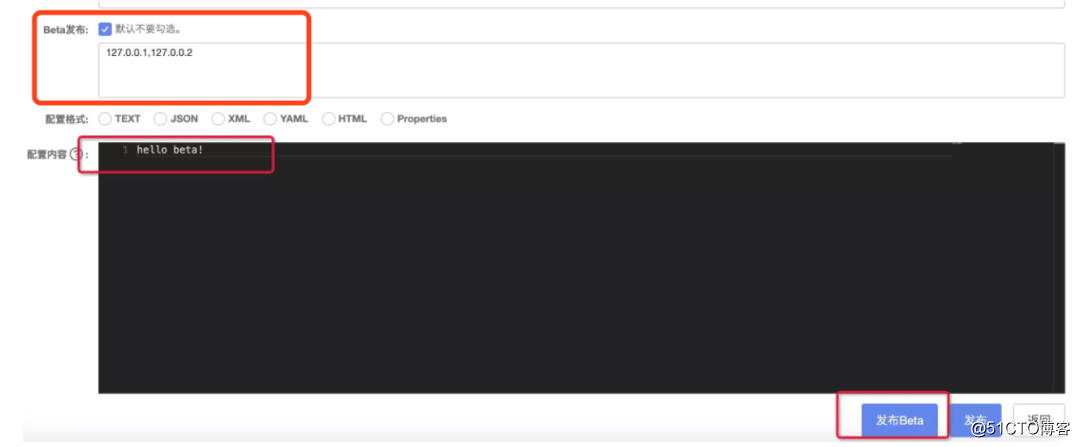
只要我们修改了配置之后,勾选beta发布,选中需要灰度的版本即可。
在nacos中的具体实现的是用一个单独的表去保存beta相关的信息: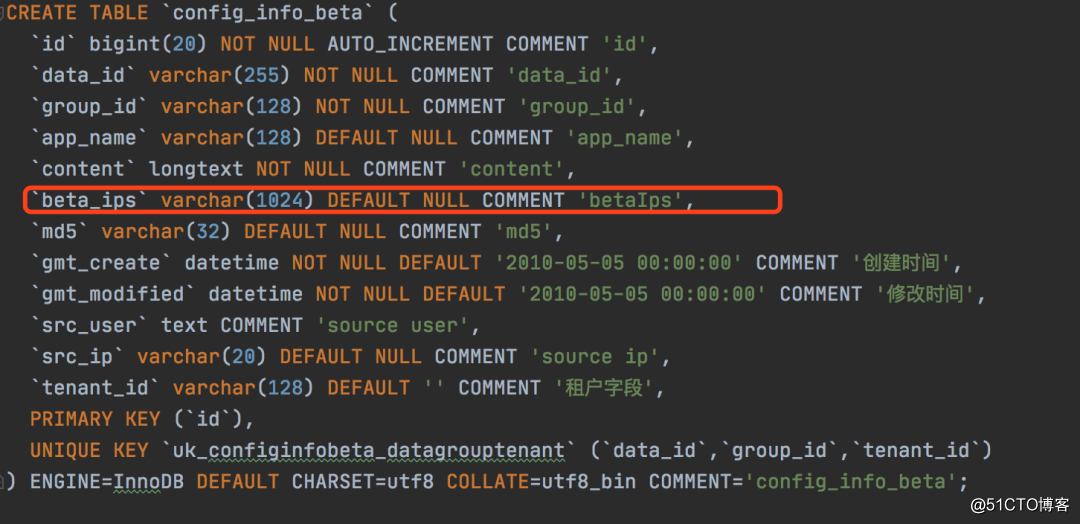
用beta_ips字段保存了我们需要灰度的机器,在客户端订阅进行长轮训的时候,也会过滤是否是灰度的机器,如果是才会进行更新,下面是LongPollingService的代码: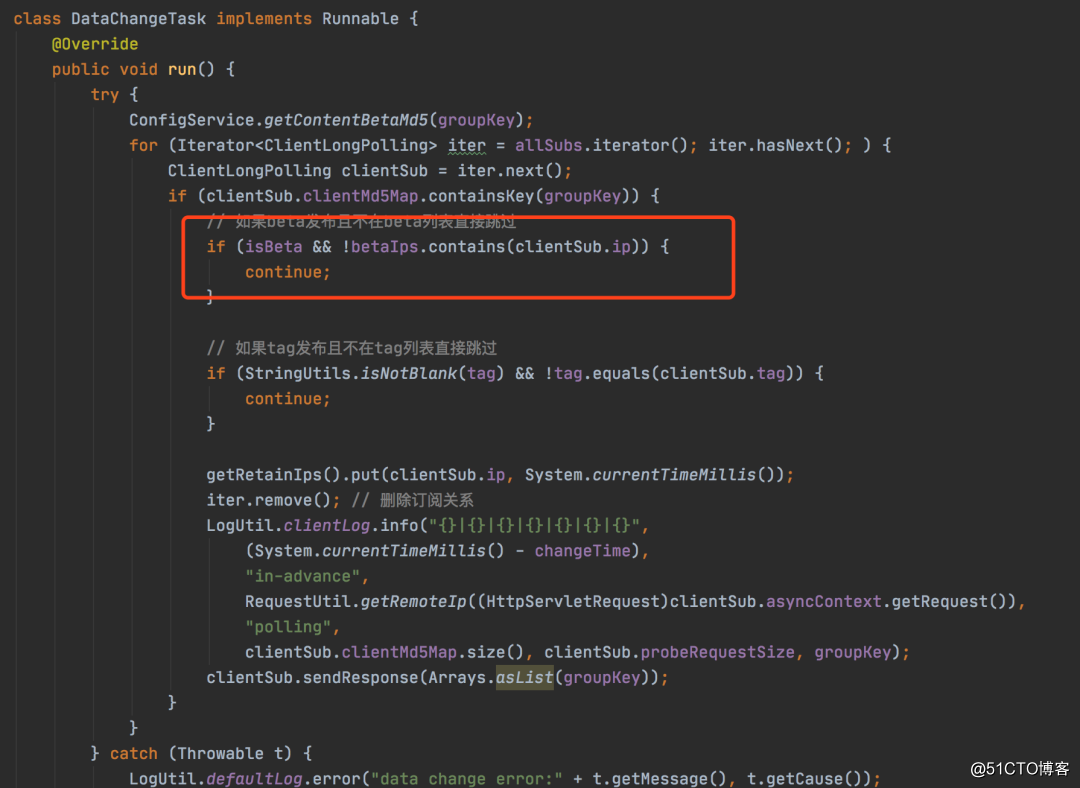
在Nacos中也提供了历史版本,类似git的commit一样,只要你有commitid你就能回滚到对应的版本,在Nacos用了一个history_config表来进行保存,我们可以通过这个表获取我们某个配置的所有历史,以此来进行回滚。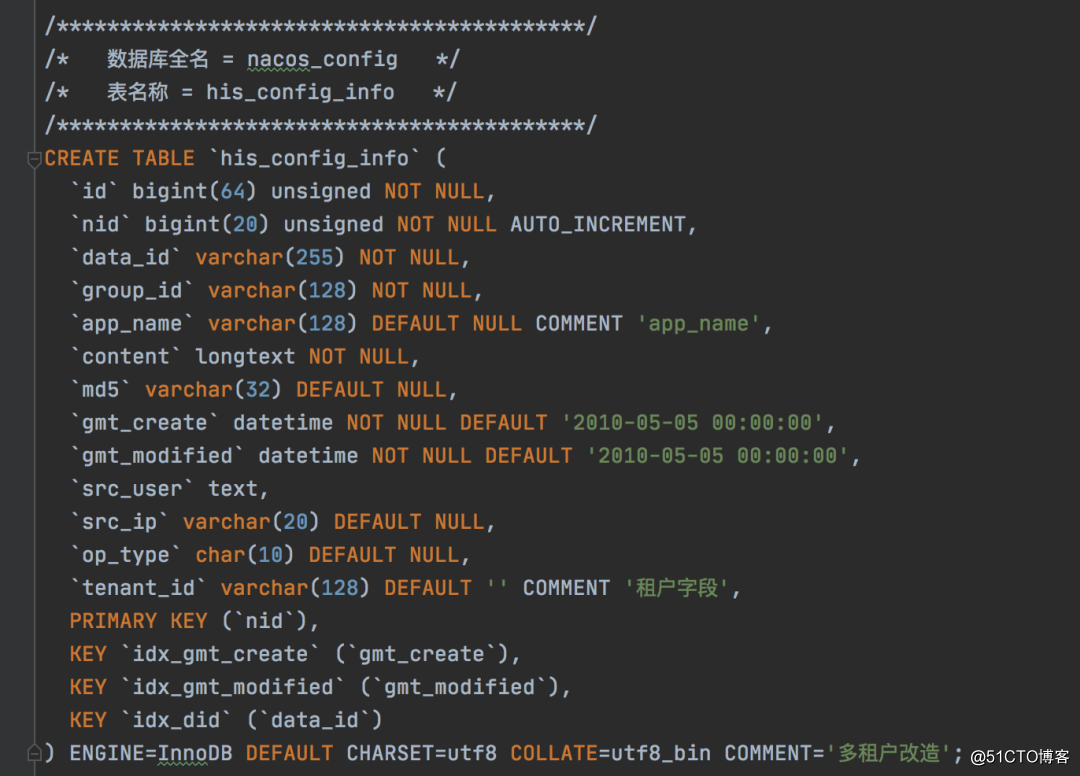
在Nacos中还有很多其他的功能,比如权限管理等等,在这里我就不一一介绍了。在Nacos的配置中心中设计得最为巧妙的也就是存储和订阅了,存储Nacos提供了两种模式,一个是Mysql+缓存+本次磁盘的方式,还有一种是通过raft+derby的方式,都有自己的优劣点。订阅的话Nacos采用的和注册中心完全不一样的方式,通过长轮训很好的解决了更新的实时通知,并且不需要大量请求资源。如果大家对Nacos感兴趣,建议还是可以阅读下Nacos的代码。
如果大家觉得这篇文章对你有帮助,你的关注和转发是对我最大的支持

标签:alt else mysq ice something rup 基本概念 查询 隔离
原文地址:https://blog.51cto.com/14980978/2544580