标签:日志 和我 nts 表结构 kafka 情况 src 导致 也会
背景不知道是否你还在为下面的问题而困扰:
?当你使用了redis或者其他中间件做缓存的时候,经常发现缓存和数据库的数据不一致,只能通过定时任务或者缓存过期的方式去做一些限制。
?当你使用了ES做搜索工具,使用双写的那一套方法,还在为ES和数据库不是一个事务而担忧。
?当你需要迁移数据的时候,也还在使用双写的方法,如果是同一个数据库的还好,如果是不同数据库就不能保证事务,那么数据一致性也是个问题,就会写很多的修复Job和检查Job。
这些问题相信在很多同学的业务当中应该都遇到过,也可能因为这些问题常常增加了很多的工作量或者导致一些数据不一致的故障。那么我们怎么才能比较简单的解决这些问题呢?
我们想一想这个问题的本质是什么呢?就是需要保证我们的数据不论在redis还是在es都要和我们的mysql一致,本质上是数据的复制。一想到数据的复制,熟悉Mysql的朋友就会说到:Mysql的主备不也是数据复制吗?如果我们模仿Mysql的主备复制,那我们数据同步那么就会很容易了。
既然我们可以模仿Mysql的主从复制来完成我们的需求,那么我们需要先了解一下mysql主从的原理,如下图所示: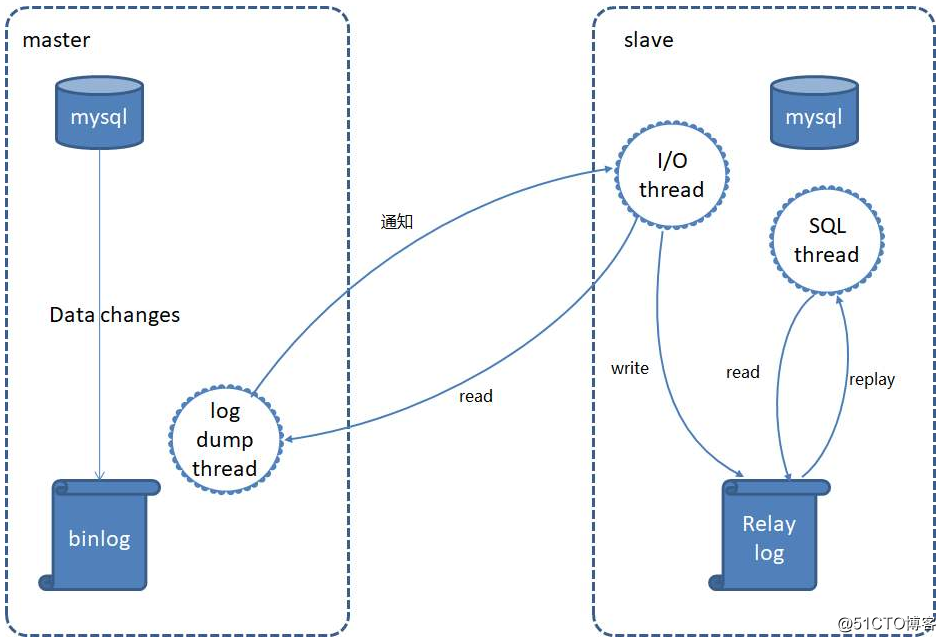
?Stpe 1: 作为master的mysql需要在每个事务更新数据完成之前,将该操作记录串行地写入到binlog文件中,存储在本地磁盘中。
?Step 2: 在我们的salve服务器中开启一个I/O Thread,它会不断的从binlog中读取如果读取。如果进度已经跟上了master,就进入睡眠状态并等待master产生新的事件。所有读取的数据都会写到Relay log(中继日志)中。
?Step 3:SQL Thread会读取中继日志,并顺序执行该日志中的SQL事件,从而与主数据库中的数据保持一致。
在主从复制中过程中,其中最为重要的就是binlog,从库会根据binlog的信息从而来复制出一份主库的数据。
如果我们能在业务代码中拿到binlog,通过binlog的数据,复制到redis或者es中,那我们就完全不用担心数据的一致性的问题了。
binlog(Binary Log)顾名思义就是Mysql中二进制的日志,记录了Mysql对数据库执行更改的所有操作。binlog也是server层产生的日志和我们的存储引擎没有关系,不论你使用哪种存储引擎,都可以使用我们的binlog。
在binlog中有三种格式,分别是:Statement,Row, Mixed三种,可以通过show variables like ‘binlog_format‘进行查看当前数据库的binlog格式,如下图所示就是一个Row格式的binlog:null
Statement也就是语句类型,他会记录每一条修改数据的Sql到binlog中。
?优点:空间占比是最小的,不会记录没有修改的字段。相比其他模式减少了很多的日志亮,提高I/O性能。
?缺点:异构系统不方便使用,比如redis缓存复制的时候,很难模拟mysql的从操作,需要数据重查一次。并且slave也会有问题,比如使用一些UUID函数,slave重放的时候并不能保证两边是一致的。我们可以查看下Statement的日志内容到底是什么?我们这里可以输入命令:show master status;查看我们当前master正在使用的binlog,如下图:
然后再使用命令show binlog events in ‘mysql-bin.000003‘, 查看这个日志中的内容是什么:null我们可以发现我们所有的操作都会在一个完整的事务中进行,如果事务没有提交是不会出现在我们的binlog当中的,这个大家可以下来进行实验一下,我们在数据库中的更新原始sql都会被完全的记录下来。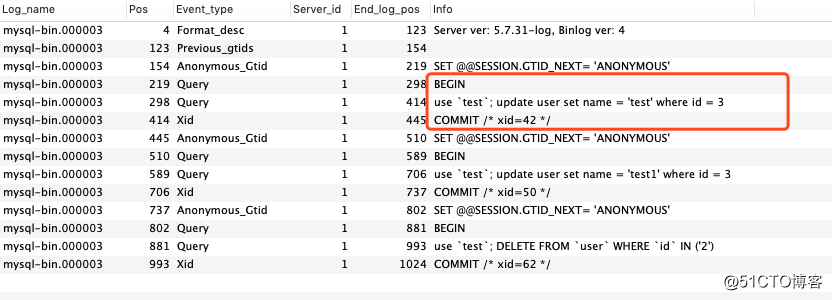
Row模式和Statement不同,他会记录每一行被修改后的所有的数据:
?优点:异构系统也能比较方便的同步数据,并且不会出现UUID函数的那种问题,无论什么情况都能被复制。
?缺点:数据量比较多,比如update语句,他还会记录更新前的每一个字段和更新后的每一个字段。造成日志量比较大,对I/O有一定的影响。
同样的我们也查看一下其中的内容: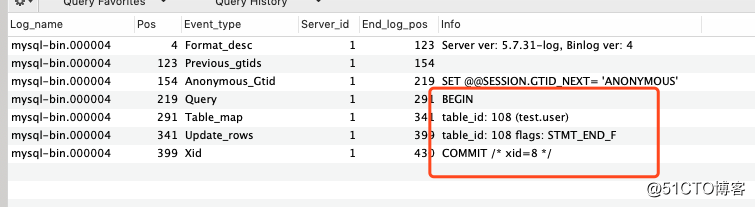
在show binlog events in ‘mysql-bin.000004‘命令中,我们发现在事务中是查看不了我们具体的数据的,这个时候就需要我们工具帮忙了mysqlbinlog,他也在mysql的bin目录下我们直接调用就好了,输入命令/usr/local/mysql/bin/mysqlbinlog --base64-output=decode-rows -v mysql-bin.000004,我们可以看见: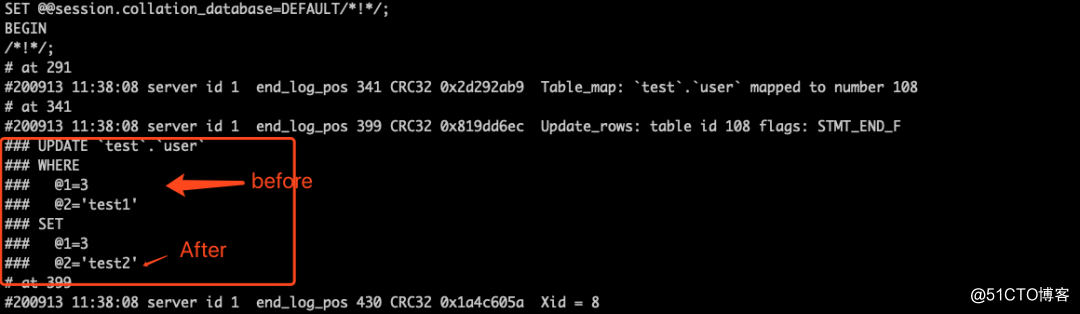
这里展示的是一个update语句,他不仅显示了原始值,也展示了修改后的值。
这里要注意的是binlog_row_image用于决定row是否会记录原始值,默认是FULL代表会记录,也就是我们上面的这种情况,还有个参数是minimal,代表只记录更新后的值。
在mixed模式下,MySQL默认仍然采用statement格式进行记录,但是一旦它判断可能会有数据不一致的情况(UUID函数)发生,则会采用row格式来记录。
我们目前默认使用的是Row模式,在Row模式下可以比较方便的将数据异构,其实Row模式对I/O影响在业务当中来说感知并不是特别明显。
当我们知道binlog是什么之后,我们就需要怎么去使用这个binlog。binlog的同步工具常见的有:databus,canal,maxwell,阿里云dts等等,在这里我们就不比较他们各自的优劣点了,重点去介绍canal。
canal(github地址:https://github.com/alibaba/canal),译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。后面在阿里云中逐渐演化称DTS项目。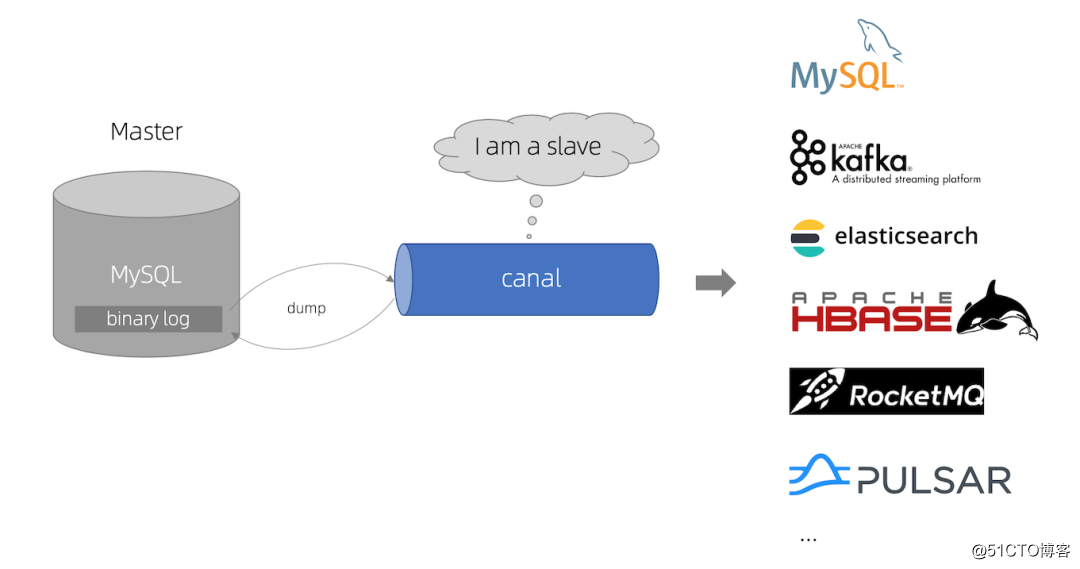
canal大体原理也是模仿mysql的slave,从master上不断的去拉取binlog,然后将binlog可以投放到不同的地方,比如我们常见的消息队列:kafka,rocketmq等等。当然在阿里云的付费dts上面也是可以直接同步到redis,es或者其他的一些存储介质当中。
canal的简单使用可以查看quickStart:https://github.com/alibaba/canal/wiki/QuickStart ,这里不做过多的介绍。接下来主要是更多的介绍canal的整体架构,以及实现的原理等等。
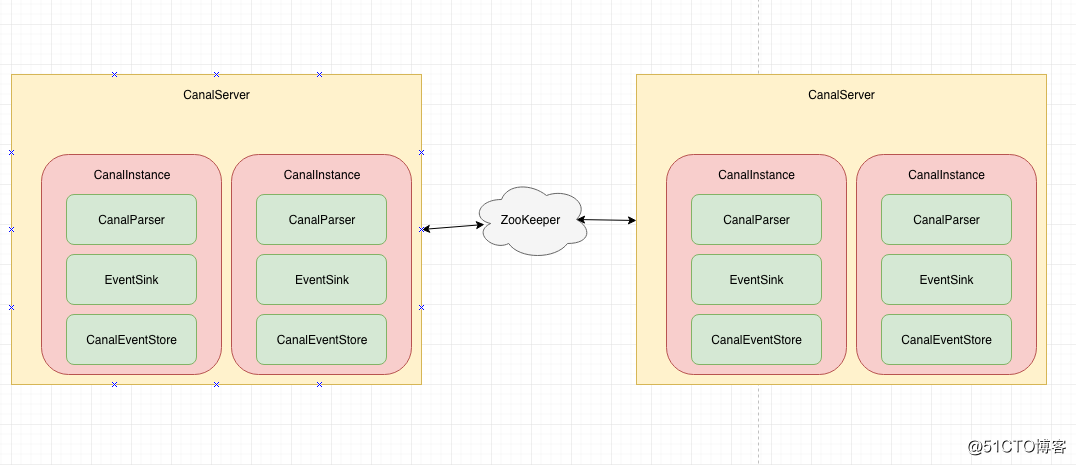
CanalServer:一个Jvm就可以理解成一个CanalServer,如果是集群模式的Canal的话 那么就会有多个CanalServer。
CanalInstance: 可以理解为一个作业为一个Instance,比如有一个把A库的binlog同步到A消息队列,B库的binlog同步到B的消息队列,那么这就是两个不同的Instance,至于哪个Instance在哪个CanalServer上跑,需要看谁先在ZK抢占到临时节点,如果分配得足够均匀得话,可以在集群模式下缓解很多压力。
CanalParser: 用于拉取mysql-binlog,并进行解析。
EventSink: 将解析的数据进行处理加工(过滤,合并等)。
CanalEventStore: 这个有点类似slave中的relay log,用于将日志进行中继存储,但是在canal中目前只支持了在内存中存储,目前不支持落盘存储。
CanalParser,EventSink,CanalEventStore这三个都是属于Canal中非常重要的组件,他们之间的关系如下: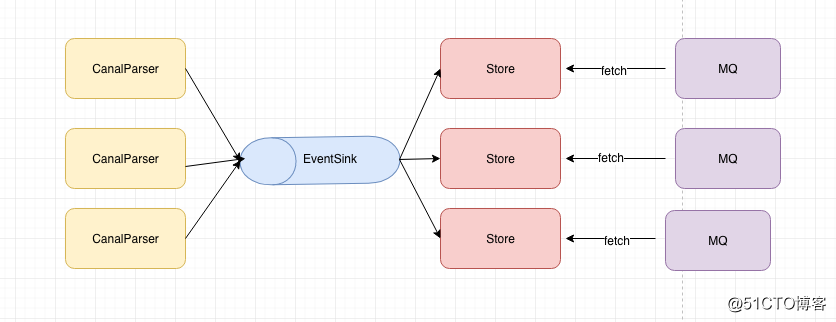
CanalParser产生数据让EventSink进行加工,加工后的数据会存储在CanalEventStore中,然后MQ从CanalEventStore中不断的拉取最新数据,然后投递到MQ。
我们来讲讲在CanalParser中Canal是如何伪装成slave去拉数据的,在AbstractEventParser.java这个类中有如下步骤:
?Step1: 构建一个数据库链接,并且生成一个slaveId,用于标示自己slave的身份。
?Step2: 获取数据库的元信息,比如binlogFormat,binRowImage等等。
?Step3: 通过show variables like ‘server_id‘ 命令,获取我们需要监听binlog服务的serverId。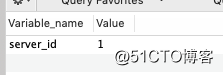
?Step4: 获取这一次需要消费的位置,如果有存储上一次的就从上一次中获取,如果没有的话需要通过show master status命令中获取到的最新的Position进行消费。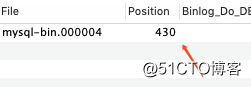
?Step5: 进行dump操作,模拟slave发送注册slave请求,以及dump binlog请求,然后用一个死循环不断的从binlog中拉取数据: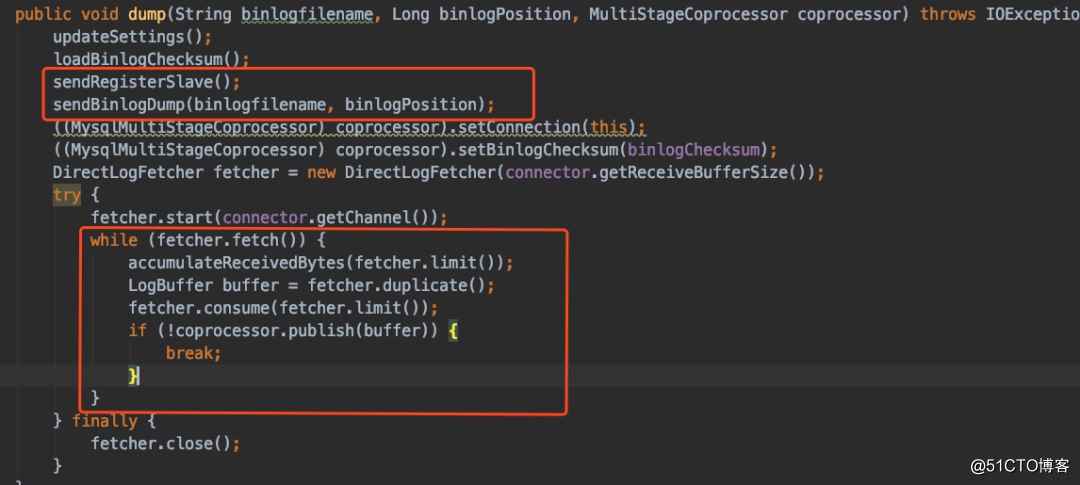
?Step6: 将获取到的二进制数据,根据mysql binlog协议转换成logEntry,方便后续处理。
EventSink会将上面获取到的logEntry来进行加工:
?过滤:
?过滤空的事务
?过滤心跳
?自定义过滤
?记录,这里使用了Prometheus,来进行数据的统计上报。
?合并,现在有很多分库分表的业务需要,他们的数据来源都是从不同的Parser中来的,但是最后都需要汇总到同一个EventStore中。在这个场景需要注意的我们可以需要注意的是会做时间归并控制,也就是尽量让每个分库的数据汇总后都是递增的方式提交,避免出现某个分库的数据比其他的领先或者落后很多。
我们先看看EventStore中提供的接口: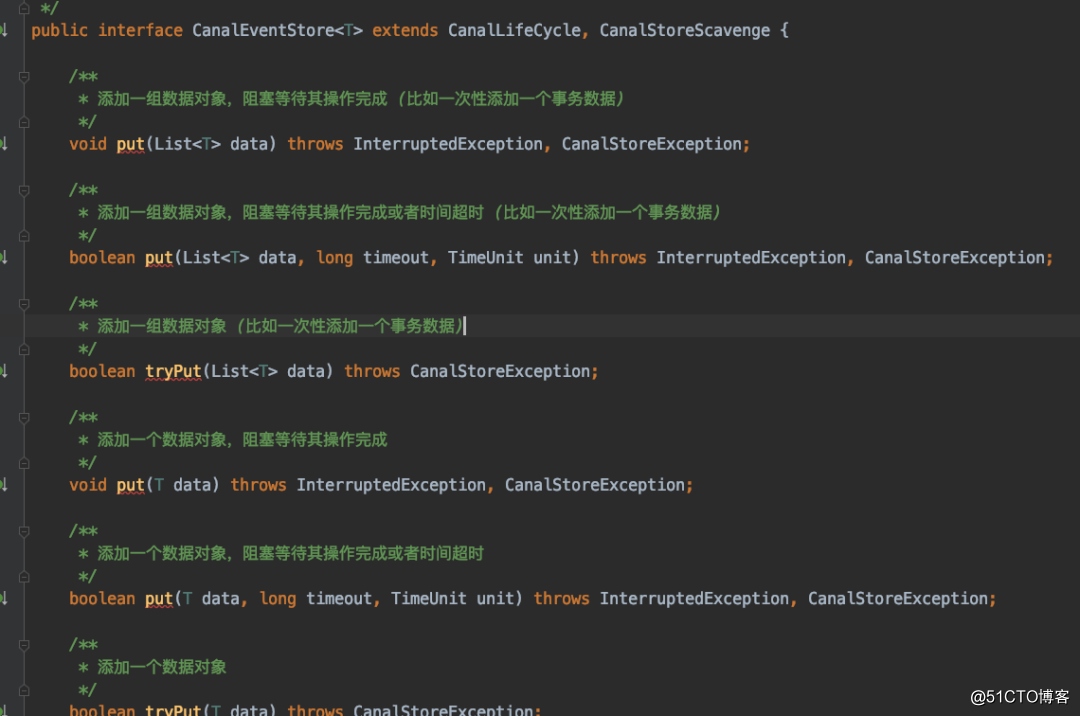
可以看见EventStore其实就是一个简单的存储,在canal中提供了MemoryEventStoreWithBuffer,在内存中进行中转的数据,其中的原理是通过RingBuffer(无锁,高性能队列)实现的,有关于RingBuffer的信息可以参考我之前的文章你应该知道的Disruptor,在3.1中有对RingBuffer进行详细讲解。
然后CanalMq通过EventStore不断的获取数据,来进行数据发送。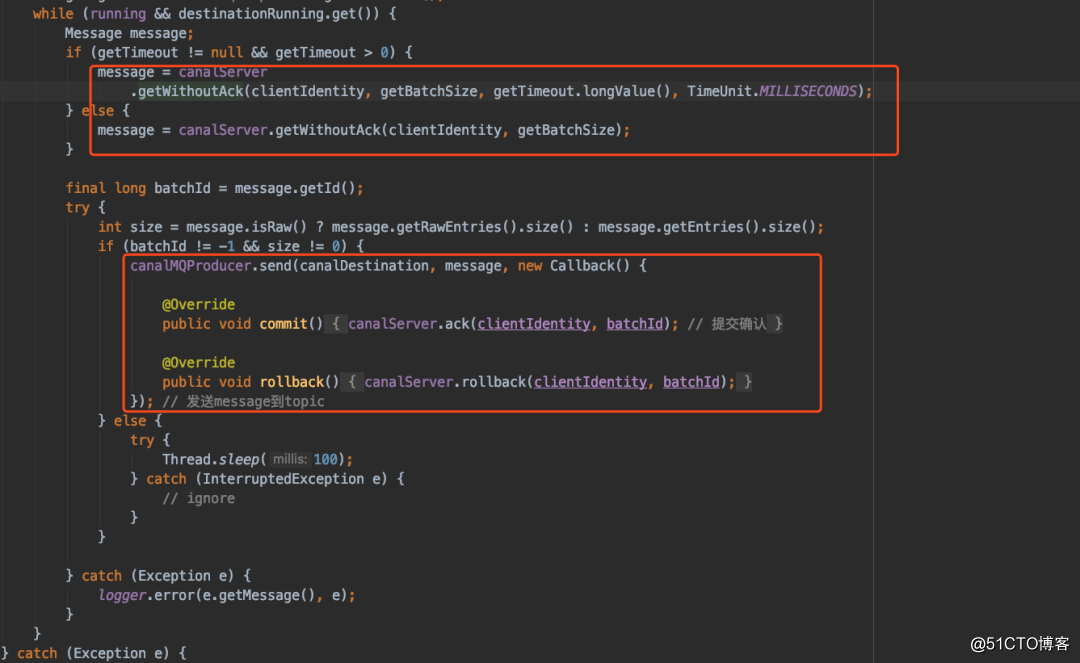
在Canal里面其实还有一些其他的优化,比如对于修改表结构之后的优化,gtid的一些优化等等,大家有兴趣的可以下来自行阅读,这里就不扩展讲开了。
总结
这篇文章主要给大家讲了binlog的一些知识以及Canal的一些科普,希望大家以后在做一些异构系统数据的同步的时候,可以多多使用binlog,用更简单的技术,做更可靠的事。
如果大家觉得这篇文章对你有帮助,你的关注和转发是对我最大的支持
标签:日志 和我 nts 表结构 kafka 情况 src 导致 也会
原文地址:https://blog.51cto.com/14980978/2544576