标签:select 处理 问题 参数 查询 update 获得 bsp 根据
数据库中有订单表tb_order,其中有order_id和user_id和user_name等字段。
数据库中有用户资料表tb_user,其中有user_id和user_name等字段。
现在需要使用tb_user.user_name来更新tb_order.user_name,两个表的关联条件是tb_order.user_id = tb_user.user_id。
通常,在两个表都静止的时候,可以使用一个update来解决,如下。
update tb_order
set user_name = (select user_name from tb_user u where u.user_id = tb_order.user_id);
但是,如果这两个表的数据量较大,且两个表都在生产频繁使用的时候,一个update语句会锁表,且需要较长的时间,从而可能会导致正常的业务无法快速进行。
此时,就应该单独遍历tb_order表中的每一条记录,然后根据tb_order.user_id去tb_user中查询每一条记录中的user_name,最后根据tb_order.order_id来更新tb_order.user_name;这个单独遍历的方式,虽然不能完全解决锁表引起的问题,但是也可以较大概率避免。
一下是一个用遍历记录的思路处理问题的kettle配置,这个配置模式,效率非常低。
思路如下:
1:将tb_order表中数据读入内存
2:从内存中获得一个记录中的字段值,并将这些值设置成kettle的变量
3:使用这些kettle变量来作为参数去tb_user中查询出来user_name,并将结果写入kettle变量
4:使用kettle中的变量,来对tb_order进行update操作
顶层配置是一个job,里面包含一个转换和一个job,转换实现了第1步的功能,job包含3个转换,分别实现了第2、3、4步的功能。具体配置如下:
顶层配置,比较关键的部分就是,job的属性设置是,一定要选中"执行每一个输入行":
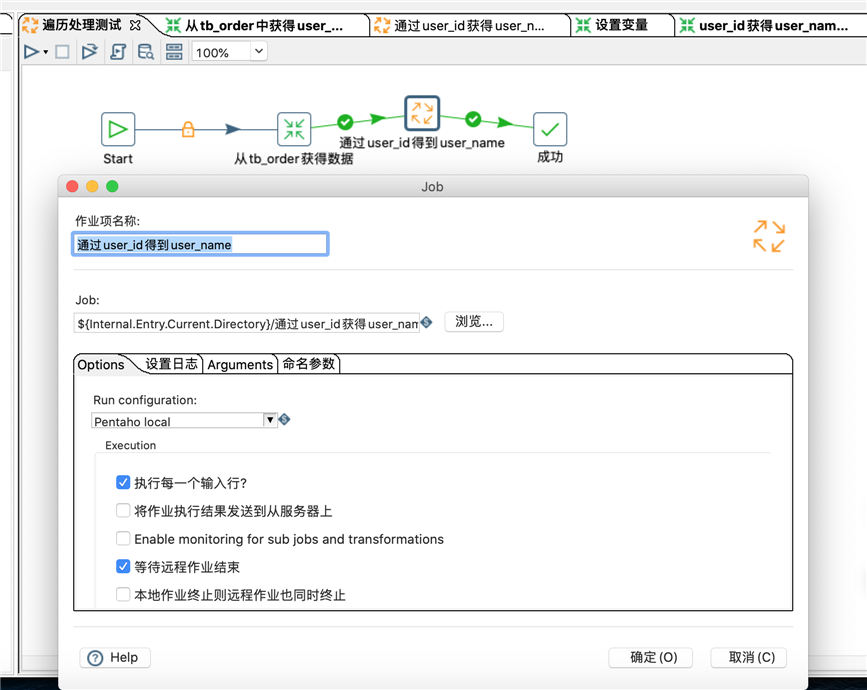
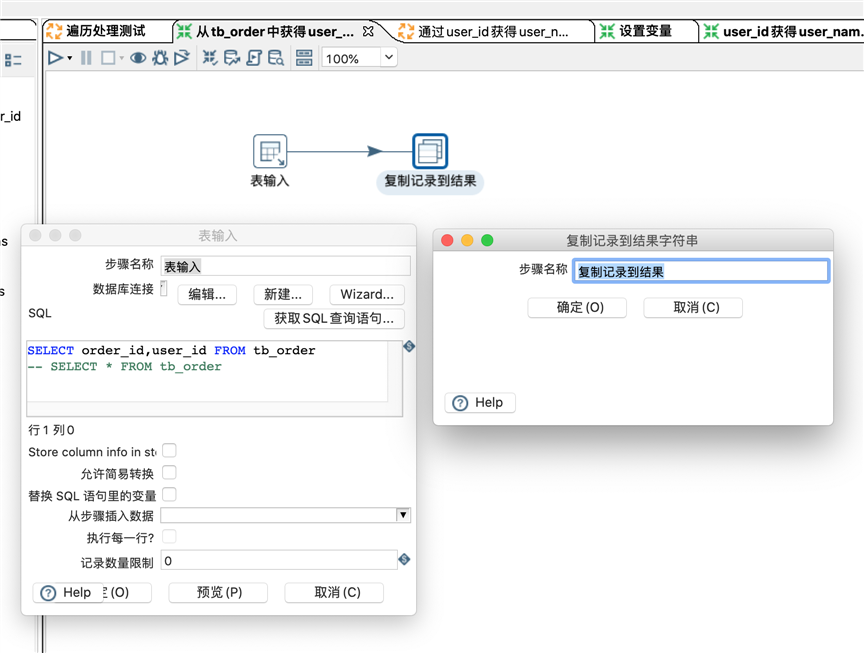
转换从tb_order获得数据的配置。表输入中使用的sql为:SELECT order_id,user_id FROM tb_order
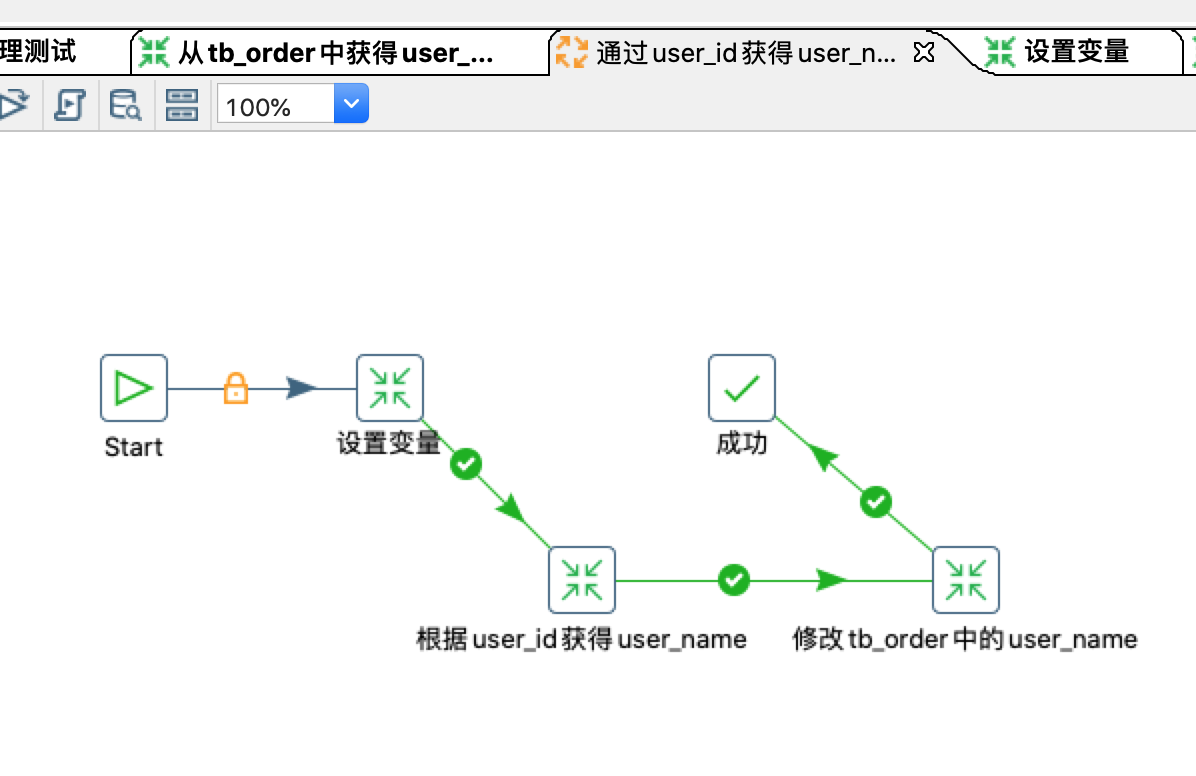
job通过user_id得到user_name的配置如下
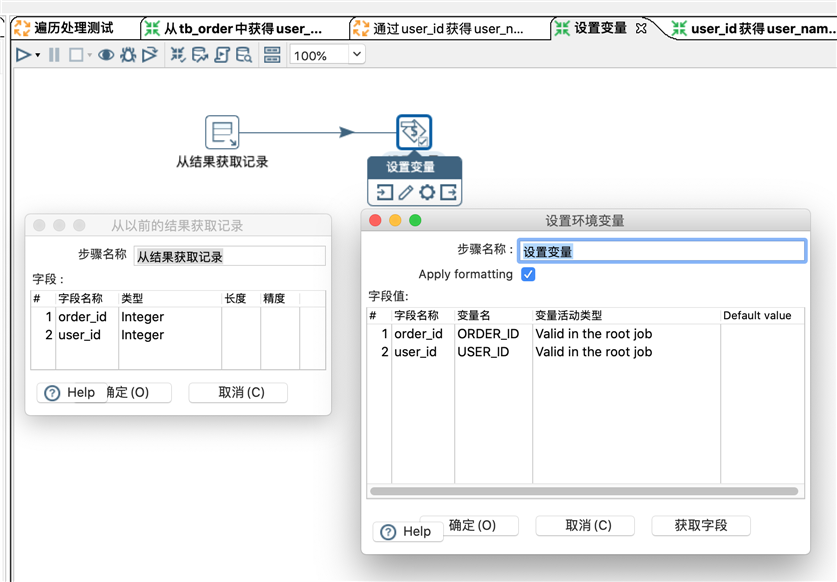
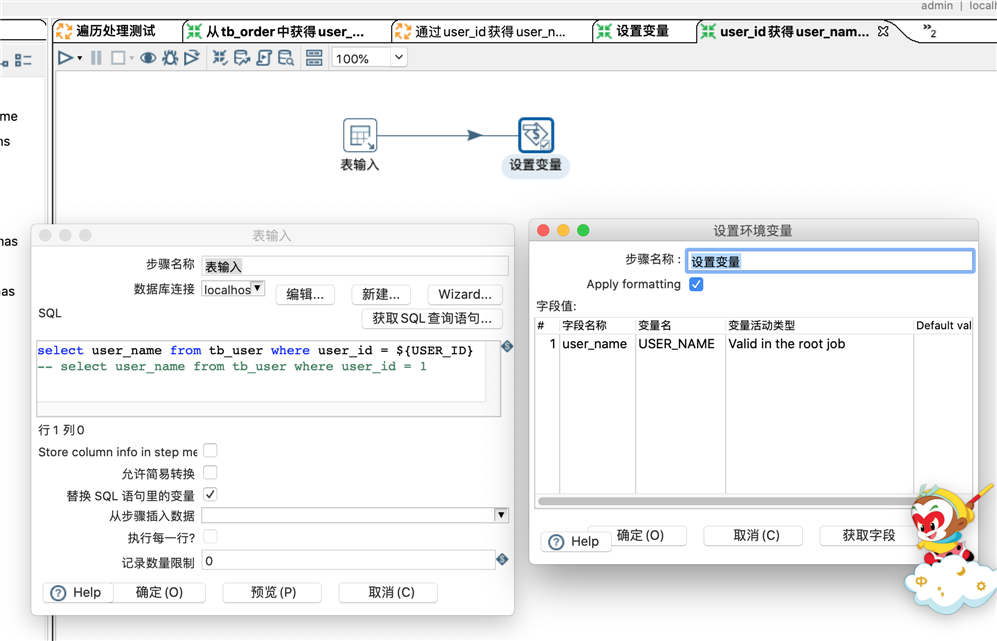
设置变量就是思路中的第2步,将内存中的一条记录写入kettle中的变量,注意,字段名需要和顶层的转换中对应的查询的名字一致,字段类型需要和实际的数据库表的字段类型一致。设置变量的配置如下,我是通过获取字段的方式来让其自动设置变量的。
转换根据user_id获得user_name的配置就是思路中的第3步,如下,${USER_ID}就是上一步的转换设置的一个变量,本步骤的设置变量,就是把查询得到的结果,保存起来:
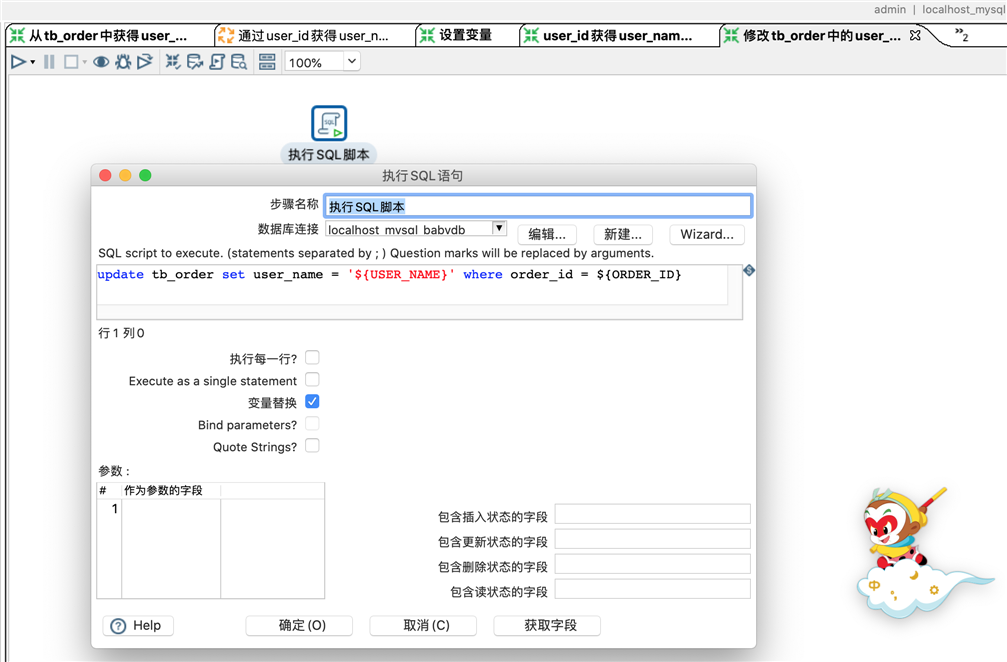
转换修改tb_order中的user_name的配置就是思路中的第4步,是一个sql脚本。配置信息如下:
标签:select 处理 问题 参数 查询 update 获得 bsp 根据
原文地址:https://www.cnblogs.com/babyha/p/13890400.html