标签:选择 apr 集成 就是 阶段 == lan www 切块
认知和学习Hadoop,我们必须得了解Hadoop的构成,我根据自己的经验通过Hadoop构件、大数据处理流程,Hadoop核心三个方面进行一下介绍:
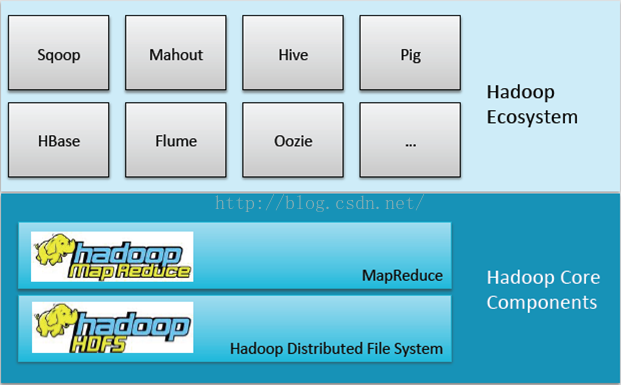
一、 Hadoop组件
由图我们可以看到Hadoop组件由底层的Hadoop核心构件以及上层的Hadoop生态系统共同集成,而上层的生态系统都是基于下层的存储和计算来完成的。
首先我们来了解一下核心构件:Mapreduce和HDFS。核心组件的产生都是基于Google的思想来的,Google的GFS带来了我们现在所认识的HDFS,Mapreduce带来了现在Mapreduce。因为Google有bigtable的概念,就是通过一个表格去存储所有的网页数据,从而也带来了Hbase,但Hbase只是这种架构思想,架构并不完全一样。
而位于上层的生态就是围绕Hadoop核心构件进行数据集成,数据挖掘,数据安全,数据管理以及用户体验等。
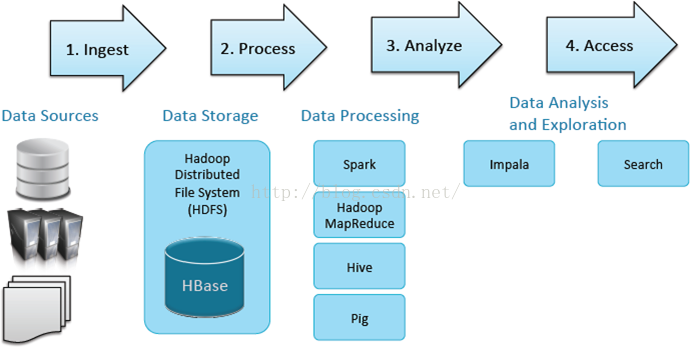
二、 大数据处理:
以上的流程符合大数据所有的应用场景。那么大数据处理,首先必须有各种的数据源,这个数据源包含了所有传统的结构化的数据,服务器的认证以及非结构化的文本(如PDF及CSV)。之前做过一个检察院的项目,大量的案例及文书都是以PDF和CSV的形式存在的,加入到Hadoop统一进行结构化和建模,进行全民索引,大大提高了效率。
接着就是数据存储层,数据存储层可以选择HDFS,也可以选择HBase。它们两个如何来更好的选择呢?HDFS一般是大量数据集的时候用比较好,因为HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。而HBase更多的是利用它的随机写,随机访问的海量数据的一个性能。
然后就是数据处理工具,基本的就是spark和mapreduce,更高级的就是hive和pig,有机会我会做详细的分析。在这些数据处理工具的之后,我们要跟BI和现有的、传统的数据进行集成,这时我们可以使用Impala,进行及时查询。首先我们要提前建好Q,算出维度、指标,通过Impala钻去,切片、切块,速度很快。search就是权威索引,之前工作都做完后,可以通过搜索去查找到需要的信息。
大数据处理都是需要这些组件来发挥作用,只是组件所处的阶段不一样而已,下面来介绍一下核心的组件。
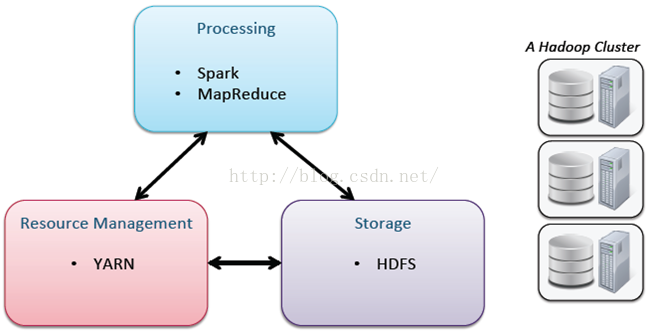
三、 Hadoop核心
这里主要强调YARN:我们都知道大家使用资源都是一个共用集群资源,在使用资源的过程中就需要进行资源控制,而YARN就可以起到控制和使用资源多少的一个作用。
标签:选择 apr 集成 就是 阶段 == lan www 切块
原文地址:https://www.cnblogs.com/shan13936/p/13892297.html