标签:最小 $@ 系统 问题 启动失败 rpo probe devops 实现
docker容器启动后,怎么确认容器运行正常,怎么确认可以对外提供服务了,这就需要health check功能了。
之前对health check的功能不在意,因为只要镜像跑起来了就是健康的,如果有问题就会运行失败。在连续两次收到两个启动失败的issue之后,我决定修正一下。
遇到的问题是,一个web服务依赖mongo容器启动,通过docker-compose启动,虽然设置了depends on, 但有时候还是会遇到mongo容器中db实例还没有完全初始化,web服务已经启动连接了,然后返回连接失败。
version: ‘3.1‘
services:
mongo:
image: mongo:4
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: example
MONGO_INITDB_DATABASE: yapi
volumes:
- ./mongo-conf:/docker-entrypoint-initdb.d
- ./mongo/etc:/etc/mongo
- ./mongo/data/db:/data/db
yapi:
build:
context: ./
dockerfile: Dockerfile
image: yapi
# 第一次启动使用
# command: "yapi server"
# 之后使用下面的命令
command: "node /my-yapi/vendors/server/app.js"
depends_on:
- mongo
理论上,只有mongo服务启动后,status变成up,yapi这个服务才会启动。但确实有人遇到这个问题了。那就看看解决方案。
官方文档说depends_on并不会等待db ready, emmm 也没说depends on的标准是什么,是依赖service的status up?
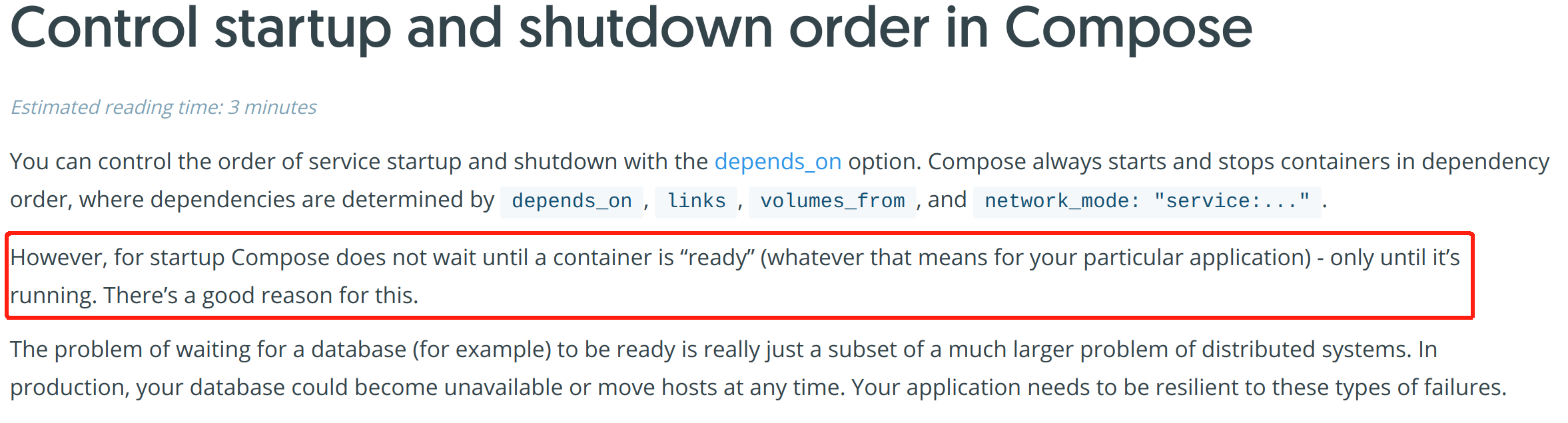
官方说depends on依赖service是running状态,如果启动中的状态也算running的话,确实有可能db没有ready。官方的说法是,服务依赖和db依赖是一个分布式系统的话题,服务应该自己解决各种网络问题,毕竟db随时都有可能断开,服务应该自己配置重联策略。
官方推荐是服务启动前检查db是否已经启动了,通过ping的形式等待。搞一个wait-for-it.sh脚本 前置检查依赖。
docker-compose.yml
version: "2"
services:
web:
build: .
ports:
- "80:8000"
depends_on:
- "db"
command: ["./wait-for-it.sh", "db:5432", "--", "python", "app.py"]
db:
image: postgres
wait-for-it.sh
#!/bin/sh
# wait-for-postgres.sh
set -e
host="$1"
shift
cmd="$@"
until PGPASSWORD=$POSTGRES_PASSWORD psql -h "$host" -U "postgres" -c ‘\q‘; do
>&2 echo "Postgres is unavailable - sleeping"
sleep 1
done
>&2 echo "Postgres is up - executing command"
exec $cmd
回归标题,上面这个问题让我想起了健康检查这个东西。于是有了本文总结。那还是记录下使用容器镜像的时候怎么作健康检查吧。
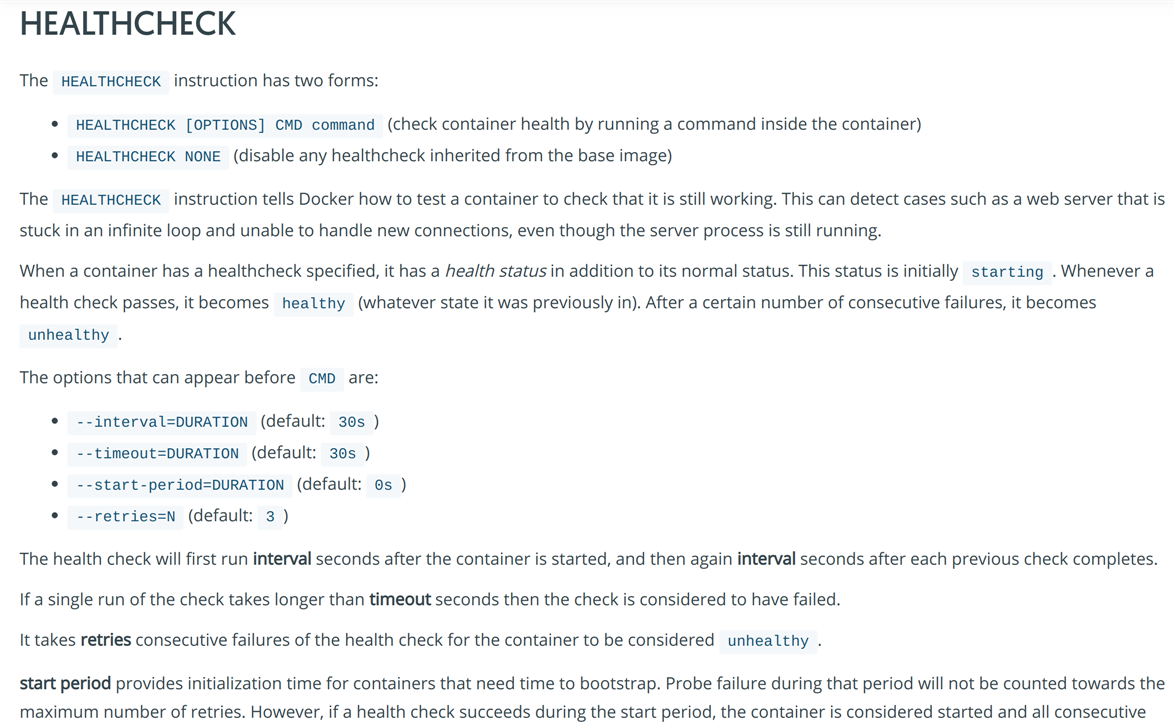
在dockerfile中可以添加HEALTHCHECK指令,检查后面的cmd是否执行成功,成功则表示容器运行健康。
HEALTHCHECK [OPTIONS] CMD command 在容器中执行cmd,返回0表示成功,返回1表示失败
HEALTHCHECK NONE 取消base镜像到当前镜像之间所有的health check
options
--interval=DURATION (default: 30s) healthcheck检查时间间隔--timeout=DURATION (default: 30s) 执行cmd超时时间--start-period=DURATION (default: 0s) 容器启动后多久开始执行health check--retries=N (default: 3) 连续n次失败则认为失败一个检查80端口的示例
HEALTHCHECK --interval=5m --timeout=3s CMD curl -f http://localhost/ || exit 1
在docker-compose.yml中添加healthcheck节点,内容和dockerfile类似。
version: ‘3.1‘
services:
mongo:
image: mongo:4
healthcheck:
test: ["CMD", "netstat -anp | grep 27017"]
interval: 2m
timeout: 10s
retries: 3
在github上发现了docker library下的healthcheck项目, 比如mongo的健康检查可以这么做:
Dockerfile
FROM mongo
COPY docker-healthcheck /usr/local/bin/
HEALTHCHECK CMD ["docker-healthcheck"]
docker-healthcheck
#!/bin/bash
set -eo pipefail
host="$(hostname --ip-address || echo ‘127.0.0.1‘)"
if mongo --quiet "$host/test" --eval ‘quit(db.runCommand({ ping: 1 }).ok ? 0 : 2)‘; then
exit 0
fi
exit 1
类色的, mysql
#!/bin/bash
set -eo pipefail
if [ "$MYSQL_RANDOM_ROOT_PASSWORD" ] && [ -z "$MYSQL_USER" ] && [ -z "$MYSQL_PASSWORD" ]; then
# there‘s no way we can guess what the random MySQL password was
echo >&2 ‘healthcheck error: cannot determine random root password (and MYSQL_USER and MYSQL_PASSWORD were not set)‘
exit 0
fi
host="$(hostname --ip-address || echo ‘127.0.0.1‘)"
user="${MYSQL_USER:-root}"
export MYSQL_PWD="${MYSQL_PASSWORD:-$MYSQL_ROOT_PASSWORD}"
args=(
# force mysql to not use the local "mysqld.sock" (test "external" connectibility)
-h"$host"
-u"$user"
--silent
)
if command -v mysqladmin &> /dev/null; then
if mysqladmin "${args[@]}" ping > /dev/null; then
exit 0
fi
else
if select="$(echo ‘SELECT 1‘ | mysql "${args[@]}")" && [ "$select" = ‘1‘ ]; then
exit 0
fi
fi
exit 1
redis
#!/bin/bash
set -eo pipefail
host="$(hostname -i || echo ‘127.0.0.1‘)"
if ping="$(redis-cli -h "$host" ping)" && [ "$ping" = ‘PONG‘ ]; then
exit 0
fi
exit 1
实际上,我们用的更多的是使用k8s的健康检查来标注容器是否健康。
k8s利用 Liveness 和 Readiness 探测机制设置更精细的健康检查,进而实现如下需求:
每个容器启动时都会执行一个进程,此进程由 Dockerfile 的 CMD 或 ENTRYPOINT 指定。如果进程退出时返回码非零,则认为容器发生故障,Kubernetes 就会根据 restartPolicy 重启容器。
在创建Pod时,可以通过liveness和readiness两种方式来探测Pod内容器的运行情况。liveness可以用来检查容器内应用的存活的情况来,如果检查失败会杀掉容器进程,是否重启容器则取决于Pod的重启策略。readiness检查容器内的应用是否能够正常对外提供服务,如果探测失败,则Endpoint Controller会将这个Pod的IP从服务中删除。
探针的检测方法有三种:
每种检查动作都可能有三种返回状态。
nginx_pod_exec.yaml:
apiVersion: v1
kind: Pod
metadata:
name: test-exec
labels:
app: web
spec:
containers:
- name: nginx
image: 192.168.56.201:5000/nginx:1.13
ports:
- containerPort: 80
args:
- /bin/sh
- -c
- touch /tmp/healthy;sleep 30;rm -rf /tmp/healthy;sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
本例创建了一个容器,通过检查一个文件是否存在来判断容器运行是否正常。容器运行30秒后,将文件删除,这样容器的liveness检查失败从而会将容器重启。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
app: httpd
name: liveness-http
spec:
containers:
- name: liveness
image: docker.io/httpd
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /index.html
port: 80
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 5
periodSeconds: 5
本例通过创建一个服务器,通过访问 index 来判断服务是否存活。通过手工删除这个文件的方式,可以导致检查失败,从而重启容器。
[root@devops-101 ~]# kubectl exec -it liveness-http /bin/sh
#
# ls
bin build cgi-bin conf error htdocs icons include logs modules
# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:39 ? 00:00:00 httpd -DFOREGROUND
daemon 6 1 0 11:39 ? 00:00:00 httpd -DFOREGROUND
daemon 7 1 0 11:39 ? 00:00:00 httpd -DFOREGROUND
daemon 8 1 0 11:39 ? 00:00:00 httpd -DFOREGROUND
root 90 0 0 11:39 ? 00:00:00 /bin/sh
root 94 90 0 11:39 ? 00:00:00 ps -ef
#
# cd /usr/local/apache2
# ls
bin build cgi-bin conf error htdocs icons include logs modules
# cd htdocs
# ls
index.html
# rm index.html
# command terminated with exit code 137
[root@devops-101 ~]# kubectl describe pod liveness-http
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 1m default-scheduler Successfully assigned default/liveness-http to devops-102
Warning Unhealthy 8s (x3 over 18s) kubelet, devops-102 Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Pulling 7s (x2 over 1m) kubelet, devops-102 pulling image "docker.io/httpd"
Normal Killing 7s kubelet, devops-102 Killing container with id docker://liveness:Container failed liveness probe.. Container will be killed and recreated.
Normal Pulled 1s (x2 over 1m) kubelet, devops-102 Successfully pulled image "docker.io/httpd"
Normal Created 1s (x2 over 1m) kubelet, devops-102 Created container
Normal Started 1s (x2 over 1m) kubelet, devops-102 Started container
这种方式通过TCP连接来判断是否存活,Pod编排示例。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
app: node
name: liveness-tcp
spec:
containers:
- name: goproxy
image: docker.io/googlecontainer/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
另一种 readiness配置方式和liveness类似,只要修改livenessProbe改为readinessProbe即可。
一些参数解释
标签:最小 $@ 系统 问题 启动失败 rpo probe devops 实现
原文地址:https://www.cnblogs.com/woshimrf/p/docker-k8s-healthcheck.html