标签:集中式 解决 扩展性 可用性 为什么 技术 状态 观点 时间
[高级]Zookeeper介绍(二)——Zookeeper概述在Zookeeper介绍(一)——背景知识中介绍过,随着网站的不断发展,逐渐从集中式演变到分布式。但是,在分布式系统中存在着很多数据一致性的问题。那么,有没有什么系统或者组件能够帮助我们解决这些一致性问题呢?本文将简单介绍一个分布式服务协调组件——Zookeeper。
什么是Zookeeper
Zookeeper是一个开放源码的分布式服务协调组件,是Google Chubby的开源实现。是一个高性能的分布式数据一致性解决方案。他将那些复杂的、容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并提供一系列简单易用的接口给用户使用。
Zookeeper提供了哪些特性
他解决的分布式数据一致性问题,提供了顺序一致性、原子性、单一视图、可靠性、实时性等。
顺序一致性:客户端的更新顺序与他们被发送的顺序相一致;
原子性:更新操作要么全部成功,要么全部失败;
单一试图:无论客户端连接到哪一个服务器,都可以看到相同的ZooKeeper视图;
可靠性:一旦一个更新操作被应用,那么在客户端再次更新它之前,其值将不会被改变;
实时性:在特定的一段时间内,系统的任何变更都将被客户端检测到;
Zookeeper工作过程
-----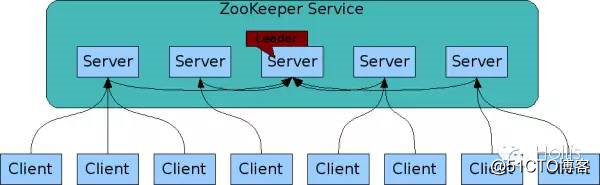
上图中,一个Zookeeper集群中有五台机器,在整个集群刚刚启动的时候,会进行Leader选举,当Leader确定之后,其他机器自动成为Follower,并和Leader建立长连接,用于数据同步和请求转发等。当有客户端机器的写请求落到follower机器上的时候,follower机器会把请求转发给Leader,由Leader处理该请求,比如数据的写操作,在请求处理完之后再把数据同步给所有的follower。
CAP理论
在分布式领域,有一个著名的理论——CAP理论。CAP理论的核心观点是任何软件系统都无法同时满足一致性、可用性以及分区容错性。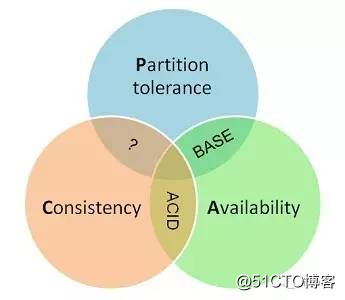
值得一提的是,作为一个分布式系统,分区容错性是一个必须要考虑的关键点。一个分布式系统一旦丧失了分区容错性,也就表示放弃了扩展性。因为在分布式系统中,网络故障是经常出现的,一旦出现在这种问题就会导致整个系统不可用是绝对不能容忍的。所以,大部分分布式系统都会在保证分区容错性的前提下在一致性和可用性之间做权衡。
在CAP这三个关键的性质中,同时满足CA两点的是著名的数据库中ACID、同时满足AP两点的是注明的BASE理论。
Zookeeper和CAP的关系
上面介绍过,没有任何一个分布式系统可以同时满足CAP,Zookeeper一般以集群的形式对外提供服务,那么Zookeeper在CAP中是如何取舍的呢?
ZooKeeper是个CP(一致性+分区容错性)的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。但是别忘了,ZooKeeper是分布式协调服务,它的 职责是保证数据(注:配置数据,状态数据)在其管辖下的所有服务之间保持同步、一致;所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了,如果是AP的,那么将会带来恐怖的后果(注:ZooKeeper就像交叉路口的信号灯一样,你能想象在交通要道突然信号灯失灵的情况吗?)。而且, 作为ZooKeeper的核心实现算法 Zab,就是解决了分布式系统下数据如何在多个服务之间保持同步问题的。
如果 ZooKeeper下所有节点都断开了,或者集群中出现了网络分割的故障(注:由于交换机故障导致交换机底下的子网间不能互访);那么ZooKeeper 会将它们都从自己管理范围中剔除出去,外界就不能访问到这些节点了,即便这些节点本身是“健康”的,可以正常提供服务的;所以导致到达这些节点的服务请求 被丢失了。
[高级]Zookeeper介绍(二)——Zookeeper概述
标签:集中式 解决 扩展性 可用性 为什么 技术 状态 观点 时间
原文地址:https://blog.51cto.com/13626762/2545859