标签:nodename 转换 特点 自己 访问 场景 uid 产品 sel
你所不知道的 ChaosBlade 那些事作者简介:肖长军,阿里巴巴技术专家,花名穹谷,多年应用性能监控研发和分布式系统高可用架构经验,现专注于混沌工程领域,具备多年混沌工程研发和实践经验。开源项目 ChaosBlade 的负责人,阿里云应用高可用服务(AHAS)产品研发,混沌工程布道师。

项目背景
阿里巴巴内部从最早引入混沌工程解决微服务的依赖问题,到业务服务、云服务稳态验证,进一步升级到公共云、专有云的业务连续性保障,以及在验证云原生系统的稳定性等方面积累了比较丰富的场景和实践经验。并且当时混沌工程相关的开源工具存在场景能力分散、上手难度大、缺少实验模型标准,场景难以扩展和沉淀等问题。这些问题就会导致很难实现平台化,你很难通过一个平台去囊括这些工具。所以我们开源了 ChaosBlade 这个混沌工程实验执行工具,目的是服务于混沌工程社区,共同推进混沌工程领域的发展。
项目介绍
ChaosBlade 项目托管在 Github 平台,放在 chaosblade-io 组织下,方便项目管理和社区发展。设计 ChaosBlade 初期就考虑了易用性和场景扩展的便捷性,方便大家上手使用以及根据各自需要扩展更多的实验场景,遵循混沌实验模型提供了统一的操作简洁的执行工具,并且根据领域划分将场景实现封装成一个一个单独的项目,方便实现领域内场景扩展。目前包含的场景领域如下:
以上场景领域都单独封装成一个项目来实现,目前包含的项目如下:
以上项目都遵循混沌实验模型定义实验场景,这样不仅实现实验场景水平领域扩展,而且每个场景领域单独一个项目,使用该领域下标准方式去设计实现场景,所以很方便的实现领域内场景垂直扩展。
除了实验场景相关项目,还有相关的文档项目:
实验模型
前面提到 ChaosBlade 项目是遵循混沌实验模型设计,不仅简化了实验场景定义,而且可以很方便的扩展场景,并且通过 chaosblade cli 工具可以统一调用,便于构建上层的混沌实验平台。下面通过实验模型的推导、介绍、意义和具体的应用来详细介绍此模型。
实验模型的推导
目前的混沌实验主要包含故障模拟,我们一般对故障的描述如下:
通过上述,我们可以使用以下句式来描述故障:因为某某机器(或集群中的资源,如 Node,Pod)上的哪个组件发生了什么故障,从而造成了相关影响。我们也可以通过下图来看故障描述拆分: 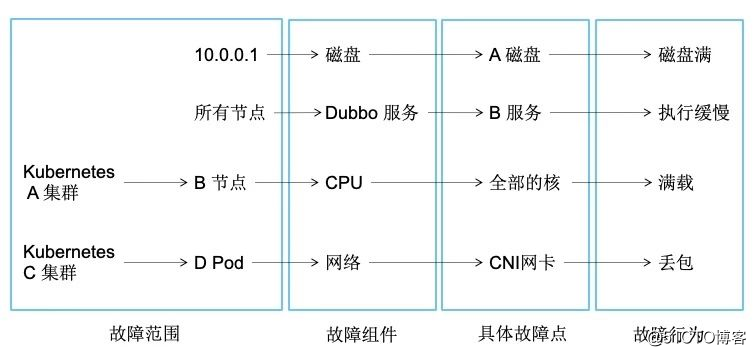
可以通过这四部分来描述现有的故障场景,所有我们抽象出了一个故障场景模型,也称为混沌实验模型 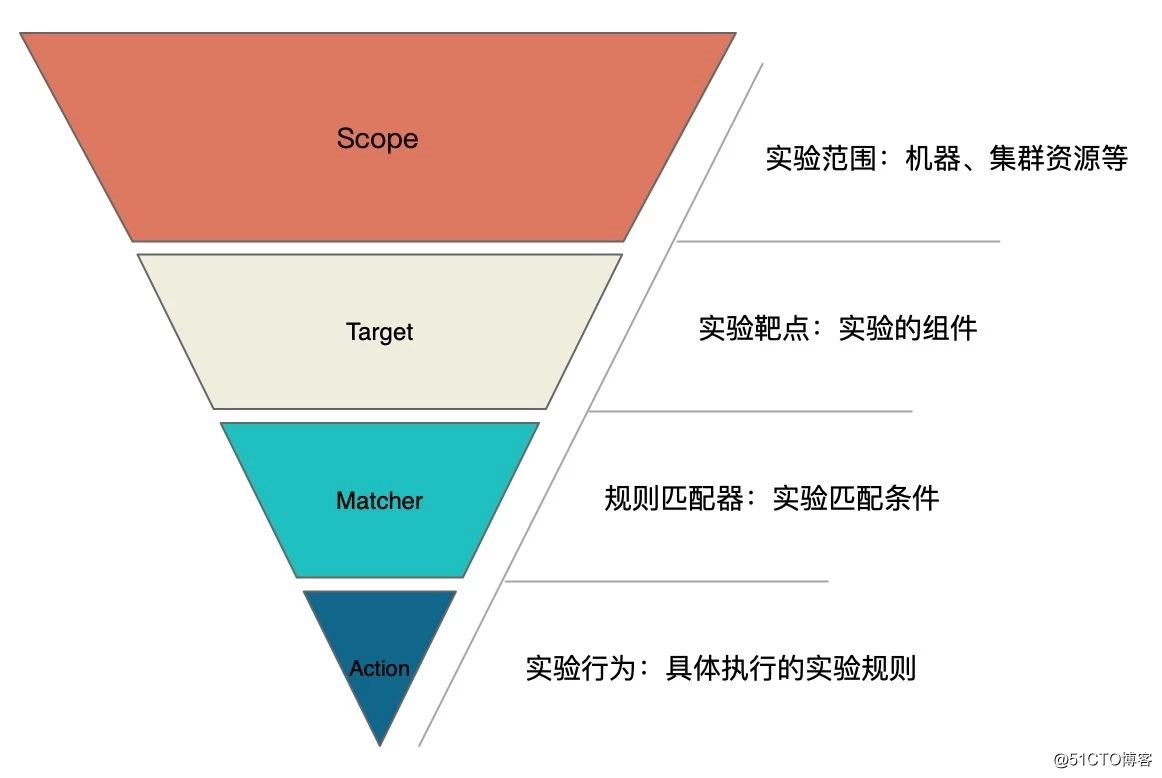
实验模型的介绍
此实验模型详细描述如下:
使用此模型可以很清晰表达出以下实施混沌实验需要明确的问题:
实验模型的意义
此模型具有以下特点:
此模型具有以下的意义:
实验模型的应用
ChaosBlade 下的项目遵循此混沌实验模型设计,需要注意的是此模型定义了混沌实验场景如何设计,但是实验场景的具体实现每个领域各不相同,所以将 ChaosBlade 依据领域实现封装成各自独立的项目,每个项目根据各领域的最佳实践来实现,不仅能满足各领域使用习惯,而且还可以通过混沌实验模型来建立与 chaosblade cli 项目的关系,方便使用 chaosblade 来统一调用,各领域下的实验场景依据混沌实验模型生成 yaml 文件描述,暴露给上层混沌实验平台,混沌实验平台根据实验场景描述文件的变更,自动感知实验场景的变化,无需新增场景时再做平台开发,使混沌平台更加专注于混沌工程其他部分。以下分为基于混沌实验模型的 chaosblade cli 设计、基于混沌实验模型的 chaosblade operator 设计和基于混沌实验模型构建混沌实验平台三部分详细介绍混沌实验模型的应用。
基于混沌实验模型的 chaosblade cli 设计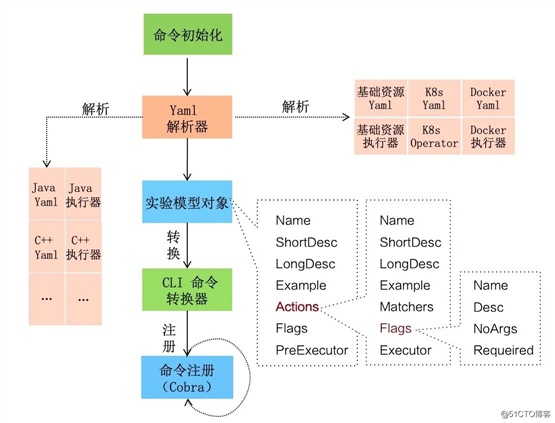
chaosblade 项目本身使用 Golang 构建,解压即用,工具采用 CLI 方式执行,使用简单,具备完善的命令提示。根据 chaosblade-spec-go项目对混沌实验模型的定义,解析遵循混沌实验模型实现的实验场景 yaml 描述,将实验场景转换为 cobra 框架所支持的命令参数,实现变量参数化、参数规范化,而且将整个实验对象化,每个实验对象都会有个 UID,方便管理。 
通过一个具体的实验场景来说明 chaosblade cli 的使用。 
我们执行的实验是对其中一个 provider 服务实例注入调用 mk-demo 数据库延迟的故障,可以看到上图左下角,这个就是对 demo 数据库注入延迟的命令,可以看出命令非常简洁清晰,比如很明确的表达出我们的实验目标是 mysql,我们的实验场景是做延迟,后面这些都是这些数据库的匹配器,比如表,查询类型,还有控制实验的影响条数等等,使用 ChaosBlade 可以很有效的控制实验的爆炸半径。执行这条命令就可以对这台机器的 provider 服务注入故障,大家可以看到我注入故障之后,这里这个图就是我立刻收到了钉钉的报警,那么这个 case 是符合预期的 case,但是即使符合预期的case,也是有价值的,需要相关的开发和运维人员是要去排查延迟的问题根因并恢复,有助于提高故障应急效率。 chaosblade 的中文使用文档:https://chaosblade-io.gitbook.io/chaosblade-help-zh-cn
基于混沌实验模型的 chaosblade operator 设计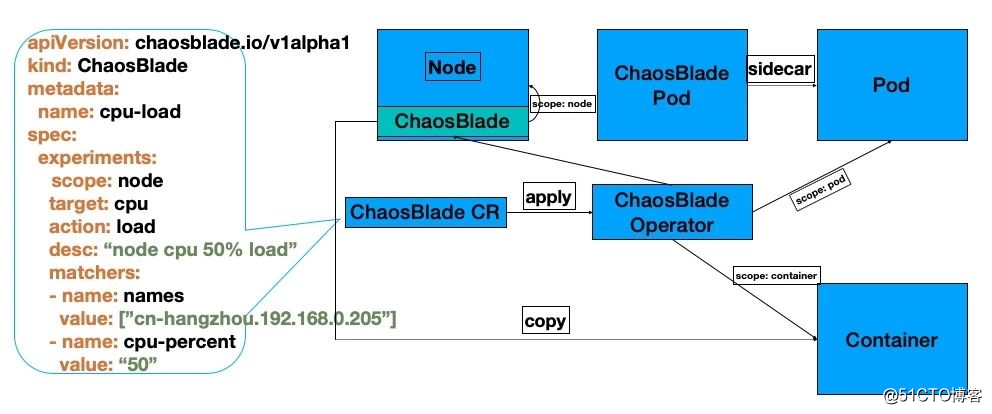
chaosblade-operator 项目是针对 Kubernetes 平台所实现的混沌实验注入工具,遵循上述混沌实验模型规范化实验场景,把实验定义为 Kubernetes CRD 资源,将实验模型中的四部分映射为 Kubernetes 资源属性,很友好的将混沌实验模型与 Kubernetes 声明式设计结合在一起,依靠混沌实验模型便捷开发场景的同时,又可以很好的结合 Kubernetes 设计理念,通过 kubectl 或者编写代码直接调用 Kubernetes API 来创建、更新、删除混沌实验,而且资源状态可以非常清晰的表示实验的执行状态,标准化实现 Kubernetes 故障注入。除了使用上述方式执行实验外,还可以使用 chaosblade cli 方式非常方便的执行 kubernetes 实验场景,查询实验状态等。 遵循混沌实验模型实现的 chaosblade operator 除上述优势之外,还可以实现基础资源、应用服务、Docker 容器等场景复用,大大方便了 Kubernetes 场景的扩展,所以在符合 Kubernetes 标准化实现场景方式之上,结合混沌实验模型可以更有效、更清晰、更方便的实现、使用混沌实验场景。 下面通过一个具体的案例来说明 chaosblade-operator 的使用:对 cn-hangzhou.192.168.0.205 节点本地端口 40690 访问模拟 60% 的网络丢包。
使用 yaml 配置方式,使用 kubectl 来执行实验
apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: loss-node-network-by-names
spec:
experiments:
- scope: node
target: network
action: loss
desc: "node network loss"
matchers:
- name: names
value: ["cn-hangzhou.192.168.0.205"]
- name: percent
value: ["60"]
- name: interface
value: ["eth0"]
- name: local-port
value: ["40690"]执行实验:
kubectl apply -f loss-node-network-by-names.yaml查询实验状态,返回信息如下(省略了 spec 等内容):
~ ? kubectl get blade loss-node-network-by-names -o json
{
"apiVersion": "chaosblade.io/v1alpha1",
"kind": "ChaosBlade",
"metadata": {
"creationTimestamp": "2019-11-04T09:56:36Z",
"finalizers": [
"finalizer.chaosblade.io"
],
"generation": 1,
"name": "loss-node-network-by-names",
"resourceVersion": "9262302",
"selfLink": "/apis/chaosblade.io/v1alpha1/chaosblades/loss-node-network-by-names",
"uid": "63a926dd-fee9-11e9-b3be-00163e136d88"
},
"status": {
"expStatuses": [
{
"action": "loss",
"resStatuses": [
{
"id": "057acaa47ae69363",
"kind": "node",
"name": "cn-hangzhou.192.168.0.205",
"nodeName": "cn-hangzhou.192.168.0.205",
"state": "Success",
"success": true,
"uid": "e179b30d-df77-11e9-b3be-00163e136d88"
}
],
"scope": "node",
"state": "Success",
"success": true,
"target": "network"
}
],
"phase": "Running"
}
}通过以上内容可以很清晰的看出混沌实验的运行状态,执行以下命令停止实验:
kubectl delete -f loss-node-network-by-names.yaml或者直接删除此 blade 资源
kubectl delete blade loss-node-network-by-names 还可以编辑 yaml 文件,更新实验内容执行,chaosblade operator 会完成实验的更新操作。
使用 chaosblade cli 的 blade 命令执行
blade create k8s node-network loss --percent 60 --interface eth0 --local-port 40690 --kubeconfig config --names cn-hangzhou.192.168.0.205如果执行失败,会返回详细的错误信息;如果执行成功,会返回实验的 UID:
{"code":200,"success":true,"result":"e647064f5f20953c"}可通过以下命令查询实验状态:
blade query k8s create e647064f5f20953c --kubeconfig config
{
"code": 200,
"success": true,
"result": {
"uid": "e647064f5f20953c",
"success": true,
"error": "",
"statuses": [
{
"id": "fa471a6285ec45f5",
"uid": "e179b30d-df77-11e9-b3be-00163e136d88",
"name": "cn-hangzhou.192.168.0.205",
"state": "Success",
"kind": "node",
"success": true,
"nodeName": "cn-hangzhou.192.168.0.205"
}
]
}
}销毁实验:
blade destroy e647064f5f20953c除了上述两种方式调用外,还可以使用 kubernetes client-go 方式执行,具体可参考:https://github.com/chaosblade-io/chaosblade/blob/master/exec/kubernetes/executor.go 代码实现。
通过上述介绍,可以看出在设计 ChaosBlade 项目初期就考虑了云原生实验场景,将混沌实验模型与 Kubernetes 设计理念友好的结合在一起,不仅可以遵循 Kubernetes 标准化实现,还可以复用其他领域场景和 chaosblade cli 调用方式,所谓的历史包袱根本不存在 :-)。
基于混沌实验模型构建混沌实验平台
前面也提到了遵循混沌实验模型实现的实验场景,可通过 yaml 文件来描述,上层实验平台可以自动感知实验场景的变更,无需平台再做开发,达到实验平台与实验场景解耦的目的,使大家可以更加专注于混沌实验平台本身的开发上。下面拿 AHAS Chaos 平台举例来说明如何基于混沌实验模型和 ChaosBlade 构建混沌实验平台。 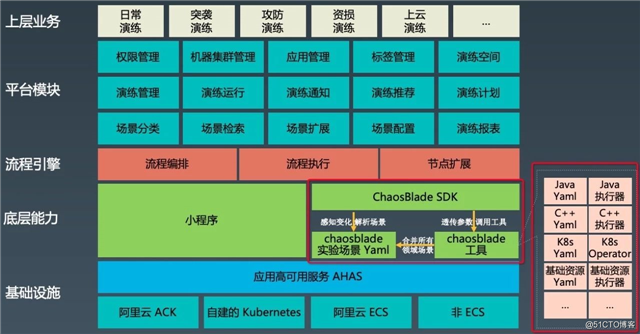
可以看到:
总结
项目意义
混沌工程领域已提出多年,混沌工程社区的每一个人都贡献着自己的力量来完善整个混沌工程领域体系,尤其是混沌工程理论的提出推动了整个混沌工程领域快速发展。我们在阿里巴巴内部实践混沌工程很多年,深知落地混沌工程之路充满各种挑战,也知道注入混沌实验只是混沌工程中的一环,混沌工程背后的思考、落地方案和实践经验也是很重要的一部分。我们只是想把我们认为好用的内部工具奉献给社区,随后将刚才提到的实践经验也通过各种渠道分享给大家,大家可以将此工具与实践经验相结合,作为企业落地混沌工程的一个入手点,共同推进混沌工程领域的进步,仅此而已。 上述详细介绍了 ChaosBlade 工具的设计和背后的思考,以及将混沌实验模型与各领域标准实现相结合的优势,欢迎对高可用架构感兴趣的各位加入到 ChaosBlade 社区中来,加入到混沌工程社区中来。总而言之,ChaosBlade 相信:开源世界中,任何帮助都是贡献。
未来规划
ChaosBlade 社区在增强原有领域的同时,比如增强云原生领域场景,还会增加更多领域的场景,例如:
除实验场景外,还会以下规划:
欢迎大家加入,一起共建,不限于:
ChaosBlade 项目才刚刚开始,欢迎开源爱好者在使用 ChaosBlade 过程中产生的任何想法和问题,都可以通过 issue 或者 pull request 的方式反馈到 Github 上。
参考阅读:
本文由高可用架构约稿。技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。

长按二维码 关注「高可用架构」公众号
标签:nodename 转换 特点 自己 访问 场景 uid 产品 sel
原文地址:https://blog.51cto.com/14977574/2546357