标签:实现 负载平衡 引入 排查 数据库迁移 pos 关闭 开发 google
详解中型系统如何一步步扩展:从1开始到支撑10万用户许多初创公司都曾经历过 — 每天都有大量新用户在注册帐户,技术团队正在争分夺秒地保持系统运转。
有问题是好事,但是关于如何将 Web 应用程序如何从 1 开始扩展到成千上万的用户的资料却很少。常见的技术方案局限于如何解决已有系统突然爆发流量,或者如何来系统定位瓶颈(通常两者兼有)。
尽管如此,我也发现将一个 side project 扩展到一个支撑大量用户的项目其实是有律可循。
本文以我们的照片分享网站 Graminsta 为例总结这些规律,介绍如何将一个系统从 1 扩展到 10 万用户。
几乎每个应用程序(无论是网站还是移动应用)都具有三个关键组件:API、数据库和客户端(通常是 app 或网站)。数据库存储持久数据,API 服务于数据及其相关请求,客户端将该数据呈现给用户。
在现代应用程序开发中发现,将客户端视为与 API 完全独立的实体,可以让扩展应用程序变得容易得多。
当第一次构建应用程序时,所有这三样东西都可以在一台服务器上运行。在某种程度上,类似于我们的开发环境:工程师在同一台计算机上运行数据库,API 和客户端。
从理论上讲,可以将应用部署在单个 DigitalOcean Droplet 或 AWS EC2 实例上的云中,如下所示:
话虽如此,如果希望 Graminsta 可以被 1 个以上的用户使用,那么将数据库层拆分出来总有意义。
将数据库迁移到托管服务(例如 Amazon RDS 或 Digital Ocean 的托管数据库)可以支撑更长久,它比在单台服务器或 EC2 实例上直接运行要贵一些,但是通过这些服务,可以获得许多便捷的附加功能:多区域冗余,多个读数据库副本,自动化备份等。
这是 Graminsta 系统现在的样子: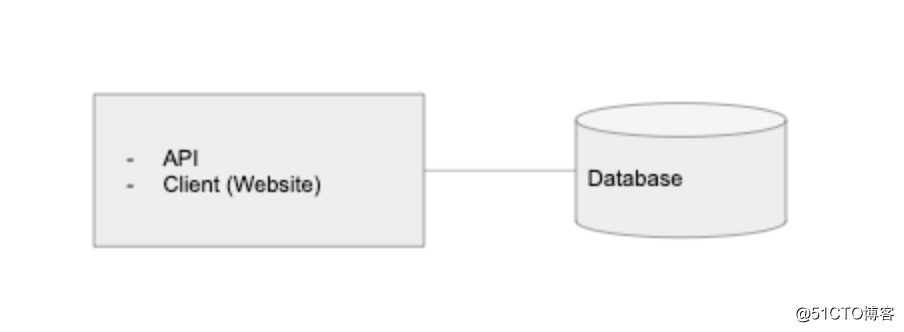
幸运的是,早期几个用户喜欢 Graminsta,流量开始变得越来越稳定,是时候拆分客户端了。要注意的是,拆分实体是构建可伸缩应用程序的关键措施,当系统的一部分出现更多流量时,可以将其拆分,并根据服务本身的流量模式来扩展服务。
这就是为什么需要将客户端与API 分开,这样可以轻松地为多个平台进行构建:Web 端、移动网站、iOS、Android、桌面应用以及第三方服务等。它们都是使用相同 API 的客户端。
同样,我们从用户那里得到的最大反馈是,他们希望 Graminsta 可以运行在手机上。因此,我们将开发一个移动应用程序。
这是系统现在的样子: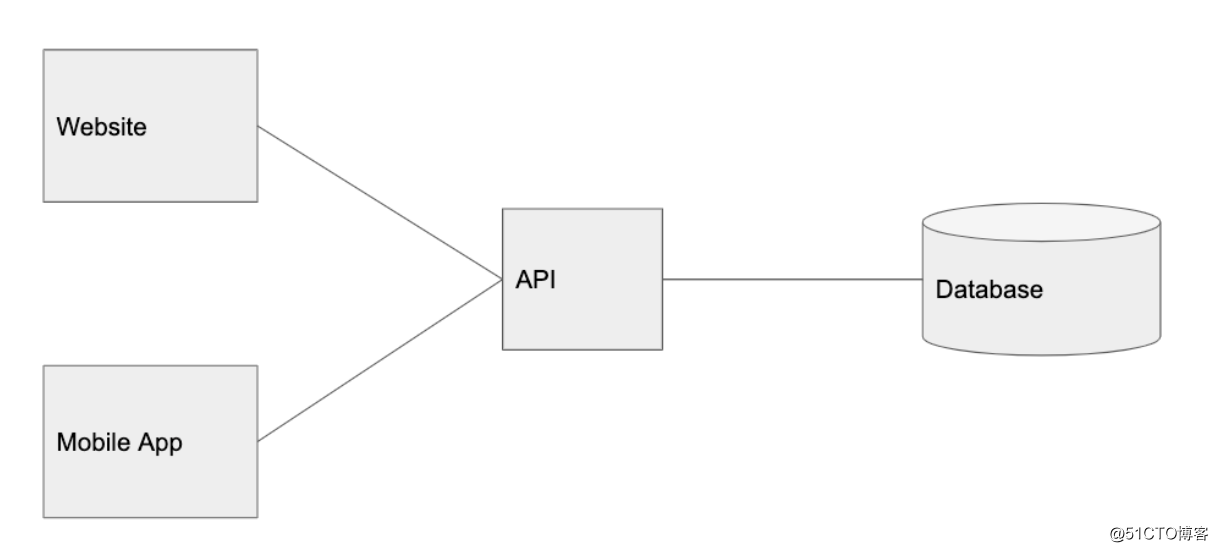
Graminsta 的访问正在上升,用户正在上传周围的照片,我们开始获得更多注册用户。这时候单个 API 实例无法服务所有流量,我们需要更多的计算资源!
负载均衡器非常强大,关键点是如果 API 之前有负载均衡器,它会将流量路由到该服务的某一个实例,实现了水平扩展(通过添加更多运行相同代码的服务器来提升处理的请求数量)。
我们在 Web 端和 API 之前也放置一个单独的负载平衡器,这样就可以有多个实例运行 API 和 Web 端代码,负载均衡器会将请求路由到流量最小的实例。
这样部署还可以进一步获得冗余能力。当某个实例出现故障(可能过载或崩溃),还有其他实例可以响应传入的请求 — 而不是整个系统出现故障。
负载均衡器还可以提供自动伸缩的能力。我们可以设置负载平衡器,以在超级碗这种每个用户都在线的场景增加实例数,并在所有用户都处于睡眠状态时减少实例数。
有了负载平衡器,我们的 API 层几乎可以无限扩展,只需要在有更多请求时继续添加实例。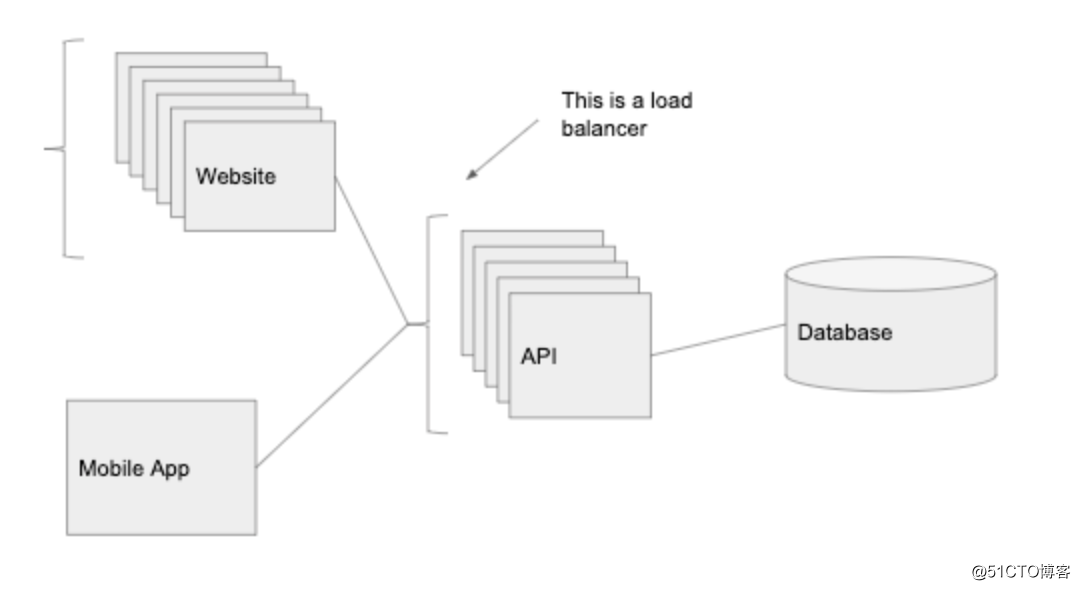
旁注:到目前为止,我们所实现的与市面上的 PaaS 平台(如 Heroku 或 AWS 的 Elastic Beanstalk)提供的功能非常相似(这就是为何它们如此受欢迎)。Heroku 将数据库放置在单独的主机上,通过自动缩放管理负载均衡器,并允许您将 Web 端 与 API 分开托管。这就是在项目早期启动中为何推荐使用 Heroku 之类的服务的重要原因 — 所有必要的基础功能都是现成的。
其实应该从一开始就应该重视这个问题,但是由于 Graminsta 快速迭代而耽搁了:图片的访问及上传已经开始对我们的服务器造成太大的负担。
我们可以使用云存储服务来托管静态内容:比如图片,视频等等(AWS S3 或Digital Ocean 的 Spaces)。通常,我们的 API 应该避免处理诸如下载图片和上传图片之类的工作。
我们从云存储服务中获得的另一个功能是 CDN(在 AWS 中,这是一个称为Cloudfront 的附加组件,但是许多云存储服务都是开箱即用的)。CDN 会自动将我们的图片缓存在世界各地的不同数据中心。
尽管我们的主数据中心位于俄亥俄州,但如果有人要从日本访问图片,我们的云提供商会将进行复制,并将其存储在日本的数据中心。接下来在日本访问该图片的人将更快地打开它。当我们需要提供较大尺寸的多媒体内容时(例如图片或视频),在全球访问可能需要较长的时间来加载及上传。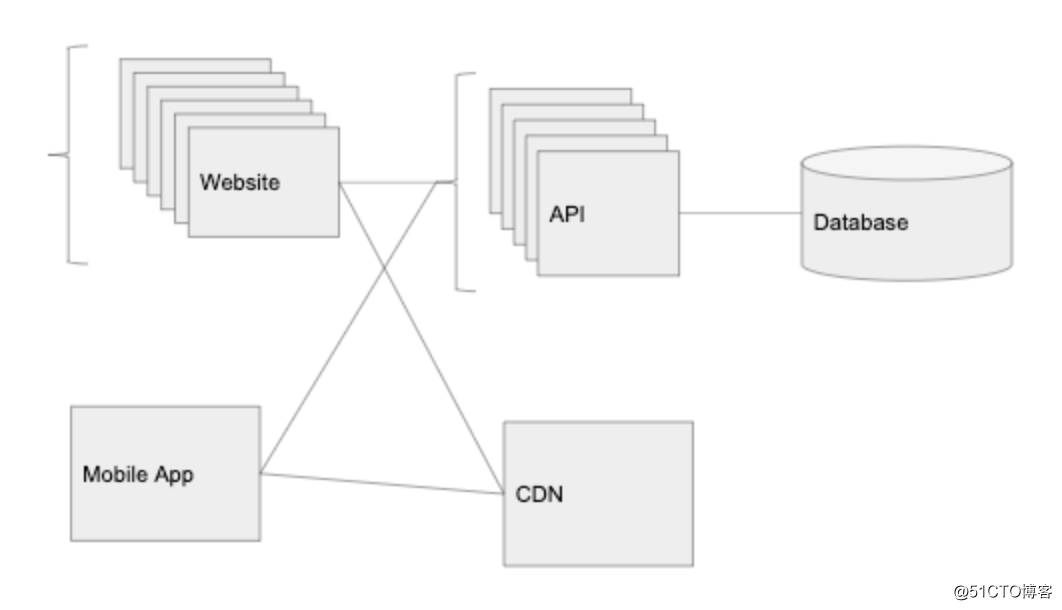
CDN帮了我们很多忙 — Graminsta的流量越来越大。YouTube 上的网红 Mavid Mobrick 刚刚注册了账号,并在他的故事中宣传了我们。API CPU 和内存的使用率都很低 — 这要归功于我们的负载均衡器添加了 10 个 API 实例 —但是我们的访问请求上出现了很多访问超时...为什么有些请求要花那么长时间?
经过一番排查后我们看到:数据库 CPU 徘徊在 80-90%,资源快要耗尽了。
扩展数据层可能是搭建可扩展体系中最棘手的部分。对于无状态请求的 API 服务器,我们可以随时添加更多实例,但对于大多数数据库系统却并非如此,包括流行的关系数据库系统(PostgreSQL,MySQL等)。
优化数据库最简单方法之一是向系统引入一个新组件:缓存层。实现缓存的最常见方法是使用 Redis 或 Memcached 实现内存中的键值存储。大多数云具有以下服务的托管版本:AWS上的Elasticache和Google Cloud上的Memorystore。
当针对相同信息多次重复进行数据库查询时,缓存将派上用场。本质上,我们只需要访问一次数据库,然后将信息保存在缓存中,之后则无需再次接触数据库。
例如,在 Graminsta 中,每次有用户访问 Mavid Mobrick 的个人资料页面时,API 层都需要从数据库中请求 Mavid Mobrick 的个人资料信息,这是一遍又一遍地发生。由于 Mavid Mobrick 的个人资料信息不会在每次请求时都发生改变,因此该信息非常适合缓存。
我们把数据库中的查询结果缓存在 Redis 的 user:id key 下面,过期时间为 30秒。当有人访问 Mavid Mobrick 的个人资料时,系统首先检查 Redis,如果里面存在则直接返回。尽管 Mavid Mobrick 在网站上最受欢迎,但请求他的资料几乎不会对数据库造成访问负担。
与数据库相比,缓存服务的另一个优点是可以轻松地进行扩展。Redis 具有内置的 Redis Cluster 模式,与负载平衡器 ① 相似,它可以将数据分散到多个节点上(如果需要,可以切分成千上万个)。
几乎所有可扩展的大型系统都充分利用了缓存的优势,这是提供高性能 API 必不可少的一部分。更快的查询是和更高效的代码等价,但是如果缺少缓存,系统不足以能扩展到数百万的用户访问。
随着数据库访问量也在增加,另外可以做的一件事情是在数据库管理系统添加只读副本。使用上面的云托管服务,可以一键式完成。只读副本将与您的主数据库保持最新,并且可以服务于 SELECT 查询。
我们现在的系统如下: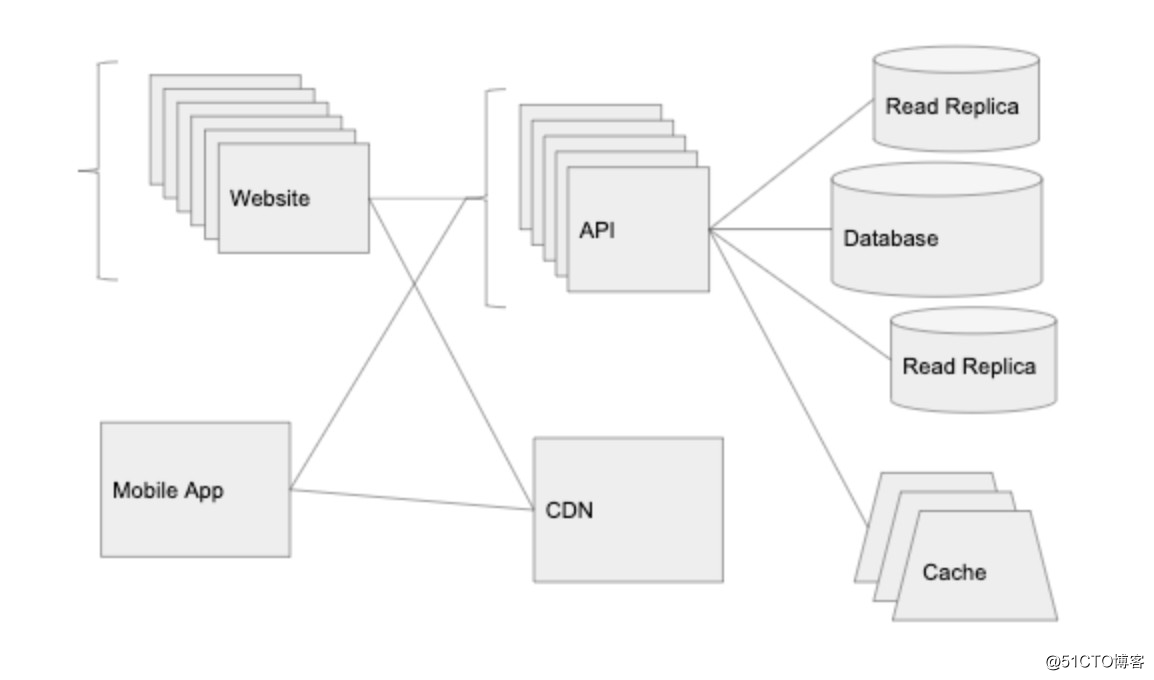
随着系统不断扩展,我们开始考虑将服务进行拆分,以便可以独立扩展。例如,如果开始使用 websockets,则有必要将 websocket 处理代码单独分开。我们可以将其放在单独的负载均衡器后面,该负载均衡器可以根据打开或关闭了多少 websocket 连接来进行伸缩,而与传入的 HTTP 请求数量无关。
我们还将继续解决数据层的限制,是开始研究数据库分区和分片的时候了。这些方法都需要更多的开销,但是可以允许数据层无限扩展。
我们将要确保安装了监控程序,使用诸如 New Relic 或 Datadog 之类的服务。这样可以了解哪些请求很慢,以及需要改进的地方。当我们进行系统扩展时,我们希望能定位发现瓶颈并加以解决-通常是利用前几节中的一些想法。
希望在这这个时候,团队中其他人也能一起参与提供帮助!
本文的灵感来自于我最喜欢的 High Scalability 网站一篇文章。我想将如何做早期阶段扩展的内容充实一些,并尽量使其与云无关。如果你对相关内容感兴趣建议阅读一下那篇文章:
① 尽管在跨多个实例负载均衡方面作用相似,但是 Redis Cluster 的基础实现与本文负载均衡器有很大不同。
原文链接:
https://alexpareto.com/scalability/systems/2020/02/03/scaling-100k.html
本文作者 Alex Pareto(感谢他的贡献),由高可用架构翻译。技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。

标签:实现 负载平衡 引入 排查 数据库迁移 pos 关闭 开发 google
原文地址:https://blog.51cto.com/14977574/2546355