标签:线程池 展望 方式 硬盘 情况下 内核 open 全球 字节
Cloudflare Nginx优化成果:每天为互联网节约54年导读:Nginx是世界范围内使用最广泛的负载均衡器和web服务器之一。Cloudflare大规模使用Nginx来支持自身的边缘节点。在其使用过程中碰见了一些问题,通过优化这些问题,Nginx的性能得到了极大提升。本文是Cloudflare对其所做的一些优化的具体分析和结论,对于工程师和架构师来说,十分值得一读。
总共有1000万个网站或者应用程序使用Cloudflare为其服务加速。 在最高峰时,我们(共151个数据中心)每秒处理超过1000万个请求。 多年来,我们对NGINX进行了许多改进,以应对我们的增长。 这篇博文是关于我们众多改进中的一部分。
NGINX的工作原理
NGINX使用事件循环来解决C10K问题 。 每次网络事件发生时(新连接,连接可读/可写等)NGINX被唤醒,之后处理事件,然后继续处理其他需要做的事情(可能处理其他事件)。 当事件到达时,与事件相关的数据已准备就绪,这使NGINX可以同时有效地处理许多请求而无需等待。
例如,以下是从文件描述符中读取数据的一段代码:
当fd是socket时,可以读取已经到达的数据。 最后一次调用将返回EWOULDBLOCK,这意味着我们已经读取了内核缓冲区中所有数据,所以在有更多数据可用之前我们不应该再次从socket中读取数据。
磁盘I/O与网络I/O不同
当fd是Linux上的文件时, EWOULDBLOCK和EAGAIN永远不会出现,并且read函数总是等待读取整个缓冲区。 即使用O_NONBLOCK打开文件也是如此。 引用open(2):
请注意,此标志对常规文件和块设备无效
换句话说,上面的代码可以精简为:
这意味着如果需要从磁盘读取数据,那么整个循环都会阻塞,直到完成读取文件,后续事件处理会被delay。
这对于大多数工作负载来说都可以接受,因为从磁盘读取数据通常足够快,并且与等待数据包从网络到达相比更加可预测。 现在大家都使用SSD,而我们的缓存磁盘都是SSD。 现代SSD具有非常低的延迟,通常为10 μs。 最重要的是,我们可以使用多个工作进程运行NGINX,以便慢速事件处理不会阻止其他进程中的请求。 大多数情况下,我们可以依靠NGINX的事件处理来快速有效地处理请求。
SSD性能并不总能达标
估计你已经猜到,我们的假设过于乐观。 如果每次磁盘读取需要50μs,那么在读取0.19MB(4KB块大小)数据需要2ms(我们读取更大的块)。 但是测试表明,对于读取速度的99和999百分位数来说,通常会比较糟糕。 换句话说,每100(或每1000)次磁盘数据读取的最慢值通常并不小。
固态硬盘非常快,并且非常复杂。 从本质上看SSD是有排队和重新排序I/O功能的计算机,还执行垃圾收集和碎片整理等各种后台任务。 偶尔会有请求变慢到需要引起重视的程度。 我的同事Ivan Babrou运行了I/O基准测试,其中最慢的磁盘读取已经达到1s。 此外,一些SSD比其他SSD的性能异常值更多。 展望未来,我们将考虑未来购买的SSD的性能保持一致,但与此同时我们需要为现有硬件提供解决方案。
使用SO_REUSEPORT均匀分布负载
虽然一个单独的慢读取是很难避免的,但我们不希望1秒钟的磁盘I/O阻塞同一秒内的其他请求。 从概念上讲,NGINX可以并行处理多个请求,但它一次却只能处理1个事件。 所以我添加了以下指标:
event_loop_blocked的时间超过了我们TTFB(首字节响应时间)的50%。 也就是说,服务请求所花费的时间的一半是由于事件循环被其他请求阻塞。由于 event_loop_blocked仅测量大约一半的阻塞(因为未测量对epoll_wait()延迟调用)因此阻塞时间的实际比率要高得多。
我们的每台机器运有15个NGINX进程,这意味着一个慢速I/O应该只阻塞最多6%的请求。但是,IO事件并不是均匀分布的,最严重的情况有11%的请求被阻塞(或者是预期的两倍)。
SO_REUSEPORT可以解决分布不均的问题。 Marek Majkowski之前撰写过相关文章,但是跟我们的实际情况不符,由于我们使用长连接,因此打开连接导致的延迟可忽略不计。 仅此配置更改就使SO_REUSEPORT峰值p99提高了33%。
将read()移动到线程池
解决这个问题的方法是使read()不阻塞。 事实上,这是一个在NGINX中已经实现的功能! 使用以下配置时, read()和write()在线程池中完成,不会阻止事件循环:
然而,当我们对此进行测试时,实际上看到p99略有改善,而不是看到大幅度的响应时间改善。 数据差异在误差范围内,我们对结果感到气馁,并暂时停止深究。
有几个原因导致没达到预期的优化程度。 在相关测试中,他们使用200个并发连接来请求大小为4MB的文件,这些文件位于机械硬盘上。 机械磁盘会增加I/O延迟,因此优化read延迟会产生更大的影响。
而且我们主要关注p99(和p999)的性能。 有助于平均性能的解决方案不一定有助于异常值。
最后,在我们的环境中,典型文件要小得多。 90%的缓存命中小于60KB的文件。 较小的文件意味着更少的阻塞时间(我们通常在2次I/O中读取整个文件)。
如果我们查看缓存命中必须执行的磁盘I/O:
32KB不是静态数字,如果文件头很小,我们只需要读取4KB(我们不使用direct IO,因此内核将最多四舍五入)。 open()看起来似乎没啥毛病,但它实际上并非没有问题。 内核至少需要检查文件是否存在以及调用进程是否有权打开它。 为此,它必须找到/cache/prefix/dir/EF/BE/CAFEBEEF的inode,也必须在/cache/prefix/dir/EF/BE/中查找CAFEBEEF。 长话短说,在最坏的情况下,内核必须执行以下查找:
这是完成open()所需的6次读取,而read()只读了1次! 幸运的是,上面描述的大多数磁盘查找由dentry缓存提供服务,并不需要访问SSD。 显然在线程池中完成的read()只是整个工作的一部分。
线程池中的非阻塞open()
所以我修改了NGINX代码,使用线程池完成大部分open(),这样它就不会阻塞事件循环。 结果如下: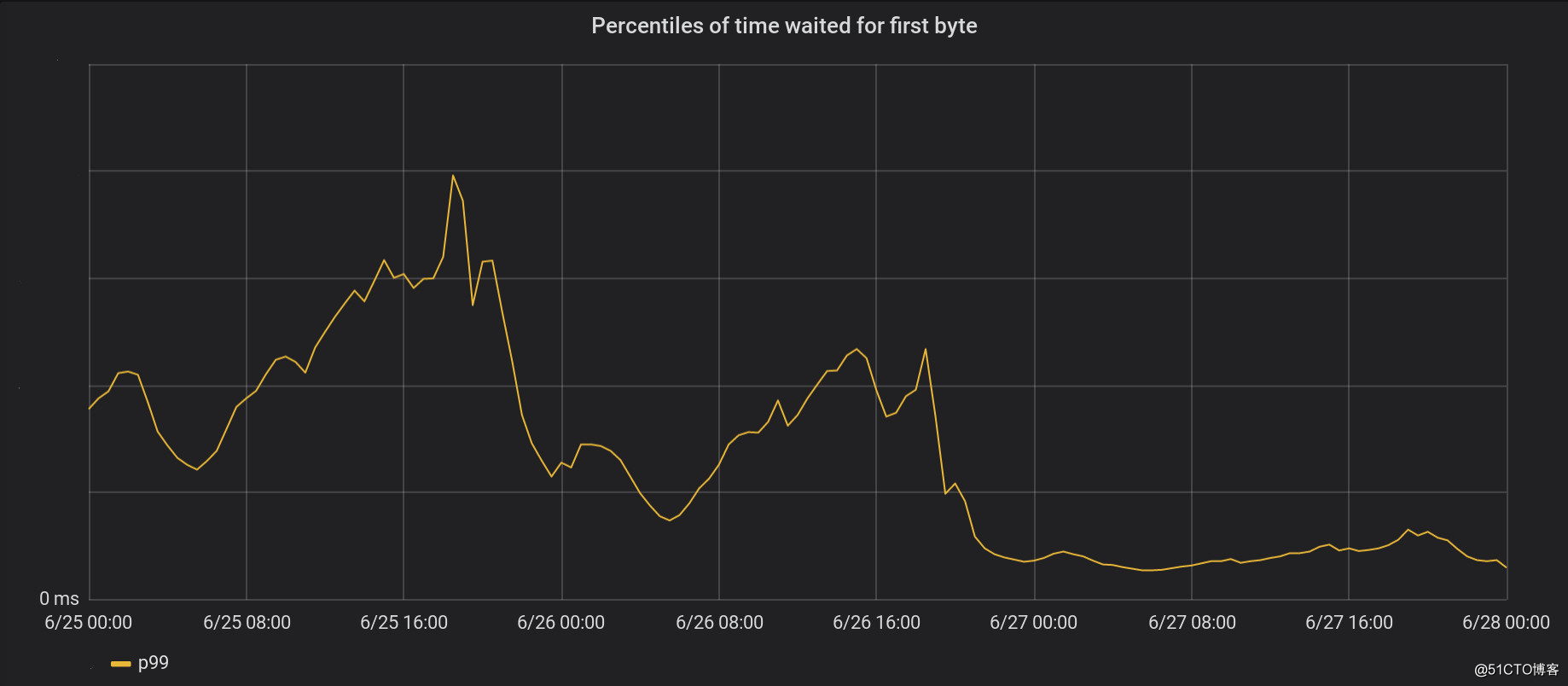
6月26日,我们对我们最繁忙的5个数据中心进行了升级,然后在第二天进行了全球范围使用。 总体峰值p99 TTFB(首字节响应时间)提高了6倍。实际上,把我们一天处理的请求节约的时间加和(每秒800万请求),我们为互联网节省了54年。
我们的事件循环处理仍然不是完全非阻塞的。 第一次缓存文件的时候( open(O_CREAT)和rename()),或重新做验证更新的时候,依然是会阻塞的。 但是由于我们的缓存命中率较高,上述情况较为罕见,所以暂时问题不大。 在未来,我们也考虑将这些代码移出事件循环以进一步改善我们的p99延迟。
结论
NGINX是一个功能强大的平台,但应对Linux上极高的I/O负载可能具有挑战性。 上游NGINX可以在单独的线程中处理文件读取,但在我们的规模下,我们需要做的更好才能应对挑战。
英文原文:
https://blog.cloudflare.com/how-we-scaled-nginx-and-saved-the-world-54-years-every-day/?ref
相关阅读:
本文作者Ka-Hing Cheung,由方圆翻译,转载本文请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
Cloudflare Nginx优化成果:每天为互联网节约54年
标签:线程池 展望 方式 硬盘 情况下 内核 open 全球 字节
原文地址:https://blog.51cto.com/14977574/2546793