标签:str cal 功能 sse 分系统 groupby 产生 ide isa
基本概念部分,批处理和流处理的区别批处理在大数据世界有着悠久的历史,比较典型的就是spark。批处理主要操作大容量静态数据集,并在计算过程完成后返回结果。
批处理模式中使用的数据集通常符合下列特征:
(1) 有界:批处理数据集代表数据的有限集合
(2) 持久:数据通常始终存储在某种类型的持久存储位置中
(3) 大量:批处理操作通常是处理极为海量数据集的唯一方法
批处理非常适合需要访问全套记录才能完成的计算工作。例如在计算总数和平均数时,必须将数据集作为一个整体加以处理,而不能将其视作多条记录的集合。这些操作要求在计算进行过程中数据维持自己的状态。
需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从持久存储设备处理数据集,或首先将数据集载入内存,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。大量数据的处理需要付出大量时间,因此批处理不适合对处理时间要求较高的场合。流处理系统会对随时进入系统的数据进行计算。相比批处理模式,这是一种截然不同的处理方式。流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作。
流处理中的数据集是“无边界”的,这就产生了几个重要的影响:
(1) 完整数据集只能代表截至目前已经进入到系统中的数据总量。
(2) 工作数据集也许更相关,在特定时间只能代表某个单一数据项。
(3) 处理工作是基于事件的,除非明确停止否则没有“尽头”。处理结果立刻可用,并会随着新数据的抵达继续更新。
流处理系统可以处理几乎无限量的数据,但同一时间只能处理一条(真正的流处理)或很少量(微批处理,Micro-batch Processing)数据,不同记录间只维持最少量的状态。虽然大部分系统提供了用于维持某些状态的方法,但流处理主要针对副作用更少,更加功能性的处理(Functional processing)进行优化。
功能性操作主要侧重于状态或副作用有限的离散步骤。针对同一个数据执行同一个操作会或略其他因素产生相同的结果,此类处理非常适合流处理,因为不同项的状态通常是某些困难、限制,以及某些情况下不需要的结果的结合体。因此虽然某些类型的状态管理通常是可行的,但这些框架通常在不具备状态管理机制时更简单也更高效。
此类处理非常适合某些类型的工作负载。有近实时处理需求的任务很适合使用流处理模式。分析、服务器或应用程序错误日志,以及其他基于时间的衡量指标是最适合的类型,因为对这些领域的数据变化做出响应对于业务职能来说是极为关键的。流处理很适合用来处理必须对变动或峰值做出响应,并且关注一段时间内变化趋势的数据。
读取一个txt文件分别使用flink的流模式和批模式进行计算统计
使用IDEA新建一个maven项目并在pom.xml中增加2个引入
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--该插件用于将scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.4.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!--打包用 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptiorRef>jar-with-dependencies</descriptiorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>在java同目录下新建一个scala目录,设置为resource root
新建一个包 com.mafei.wc 下面新建一个WordCount的scala Object
运行第一个简单的demo,从文件中读取数据,做一些过滤,分割,分组统计,求和等操作
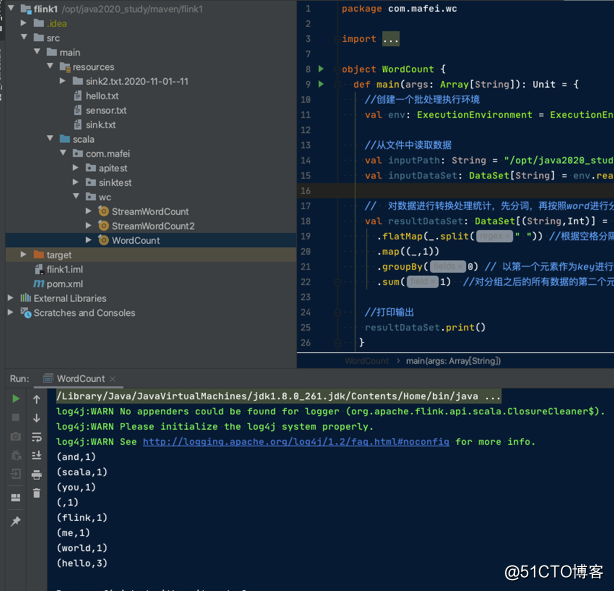
package com.mafei.wc
import org.apache.flink.api.scala.ExecutionEnvironment
//把scala里面定义的隐式转换拿出来
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
//创建一个批处理执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//从文件中读取数据
val inputPath: String = "/opt/java2020_study/maven/flink1/src/main/resources/hello.txt"
val inputDataSet: DataSet[String] = env.readTextFile(inputPath)
// 对数据进行转换处理统计,先分词,再按照word进行分组,最后聚合统计
val resultDataSet: DataSet[(String,Int)] = inputDataSet
.flatMap(_.split(" ")) //根据空格分隔
.map((_,1))
.groupBy(0) // 以第一个元素作为key进行分组统计
.sum(1) //对分组之后的所有数据的第二个元素求和
//打印输出
resultDataSet.print()
}
}
1、新建一个StreamWorldCount流处理class
package com.mafei.wc
import org.apache.flink.streaming.api.scala._
object StreamWordCount {
def main(args: Array[String]): Unit = {
//创建流处理的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//接收一个socket文本流
val inputDataStream = env.socketTextStream("127.0.0.1",7777)
//进行转换处理统计
val resultDataStreams = inputDataStream
.flatMap(_.split(" ")) //按照空格进行分割
.filter(_.nonEmpty) //过滤非空的数据
.map((_, 1)) //每次给key设置数量
.keyBy(0) //按照第一个key来做聚合
.sum(1) //做统计
resultDataStreams.print()
//最终执行的操作
env.execute("stream world count")
}
}2、新开一个终端,监听本机7777端口
nc -lk 77773、启动代码,发现程序在监听端口数据中,
4、到第二步新开的端口上随意输出字符,回车,可以看到代码在实时计算中
上面都是直接在本地运行的flink任务,下面在flink 服务器上跑一波
新建一个测试的类,从socket中读取数据并做一些分组计算等等
不同点在于socket的server IP信息不是写死在代码中,而是通过flink运行时传参实现
package com.mafei.wc
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
object StreamWordCount2 {
def main(args: Array[String]): Unit = {
//创建流处理的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// env.setParallelism(10) //针对整个任务设置并行度
//env.disableOperatorChaining() //关闭任务合并
//从外部命令中提取参数,作为socket主机名和端口号
val paramTool: ParameterTool = ParameterTool.fromArgs(args)
val host: String = paramTool.get("host")
// val port: Int = paramTool.getInt("port")
//接收一个socket文本流
val inputDataStream = env.socketTextStream(host,7777)
// val inputDataStream = env.socketTextStream("127.0.0.1",7777)
//进行转换处理统计
val resultDataStreams = inputDataStream
.flatMap(_.split(" "))
.filter(_.nonEmpty)
// .map((_, 1)).setParallelism(3) //针对单个算子设置并行度
.map((_, 1)).setParallelism(2) //针对单个算子设置并行度
.keyBy(0)
.sum(1)
resultDataStreams.print().setParallelism(1) //也可以针对输出设置并行度,用来类似输出到文件的场景等
env.execute("stream world count")
}
}
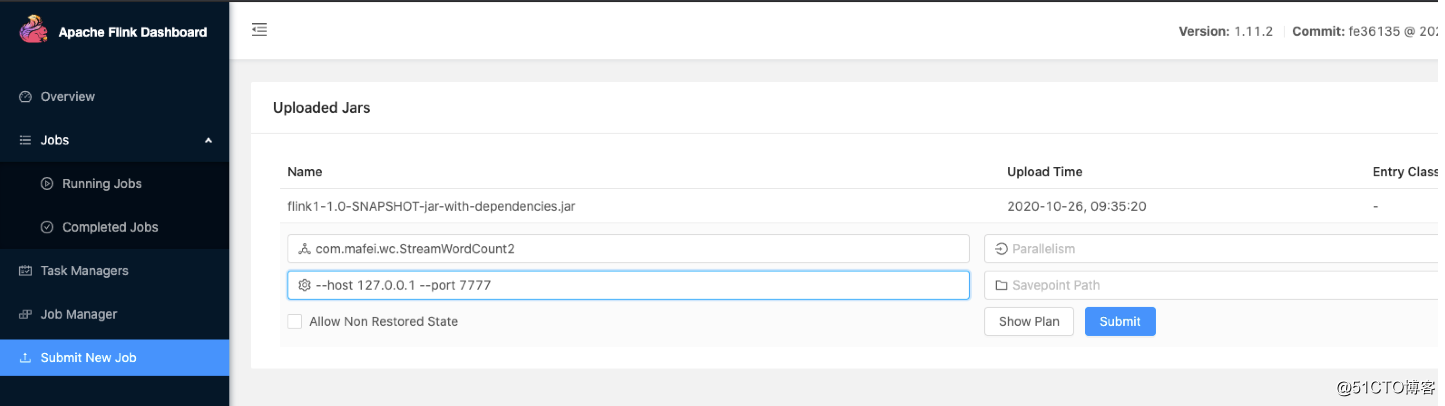
把代码打包成jar包,然后打开flink的8081默认web页面,在Submit New Job一栏,上传打包好的jar包
页面上点击上传后的jar包,
在Entry Class栏输入 com.mafei.wc.StreamWordCount2
在Program Arguments 输入: --host 127.0.0.1 --port 7777
最终效果:
服务器上监听nc程序:
安装nc: yum install nc -y
监听7777端口: nc -lk 7777
最终flink界面上任务运行效果图: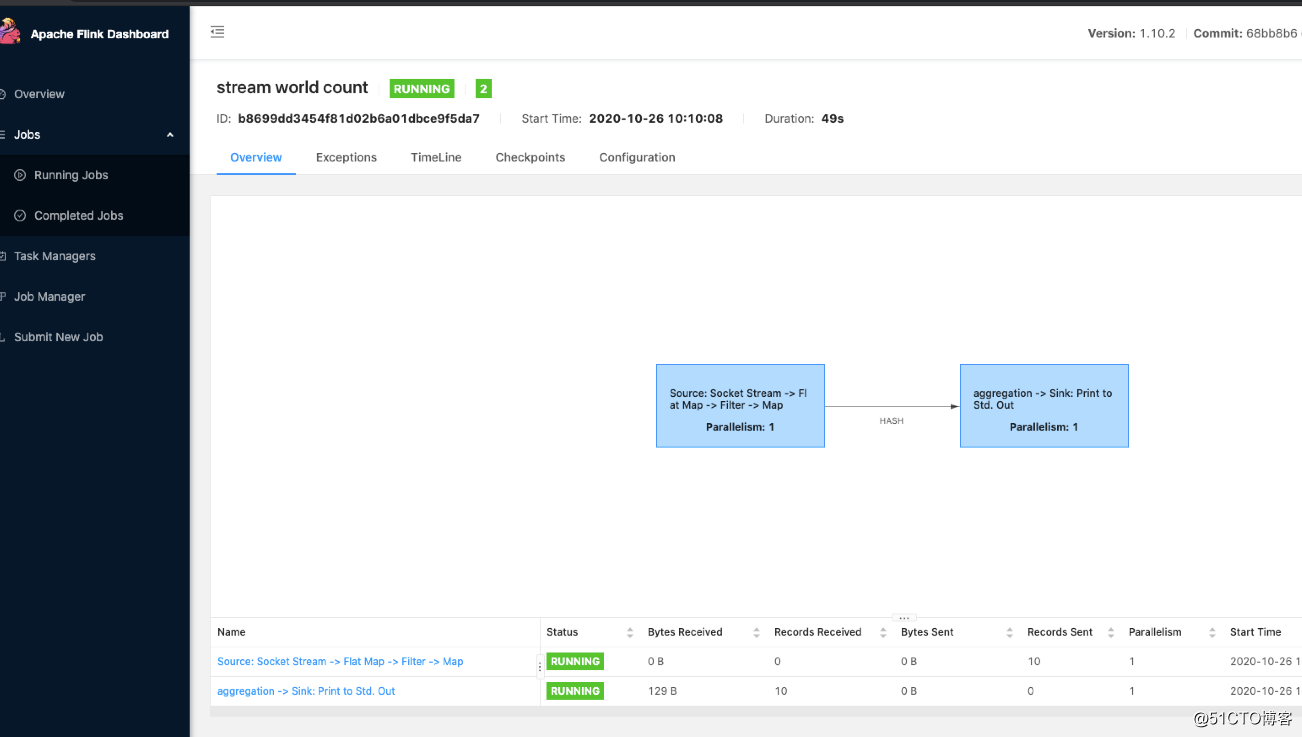
看flink输出效果(记得在socket那个终端上随意敲一些数据):
tail -f /opt/flink-1.10.2/log/flink*
(sd,1)
(fg,1)
(sdfg,1)
(s,1)
(dfg,1)
(sdf,1)
(g,1)
(wert,1)
(wert,2)
(xdfcg,1)命令行执行方式:
把打包好的jar包手动上传到服务器上
/opt/flink-1.10.2/bin/flink run -c com.mafei.wc.StreamWordCount2 -p 1 /opt/flink1-1.0-SNAPSHOT-jar-with-dependencies.jar --host localhost --port 7777
列出来所有任务:
/opt/flink-1.10.2/bin/flink list
列出来所有任务-包含已运行完成的
/opt/flink-1.10.2/bin/flink list -a
取消任务
/opt/flink-1.10.2/bin/flink cancel 43dcc61e27b64e63306c9e9ab1b8e0f9
Flink从入门到真香(1-分别使用流模式和批模式运行第一个demo)
标签:str cal 功能 sse 分系统 groupby 产生 ide isa
原文地址:https://blog.51cto.com/mapengfei/2546985