标签:数据量 alt 实践总结 想法 查询 程序代码 index sem 处理
前言最近对外接口偶现504超时问题,原因是代码执行时间过长,超过nginx配置的15秒,然后真枪实弹搞了一次接口性能优化。在这里结合优化过程,总结了接口优化的八个要点,希望对大家有帮助呀~
嘻嘻,先看一下我们对外转账接口的大概流程吧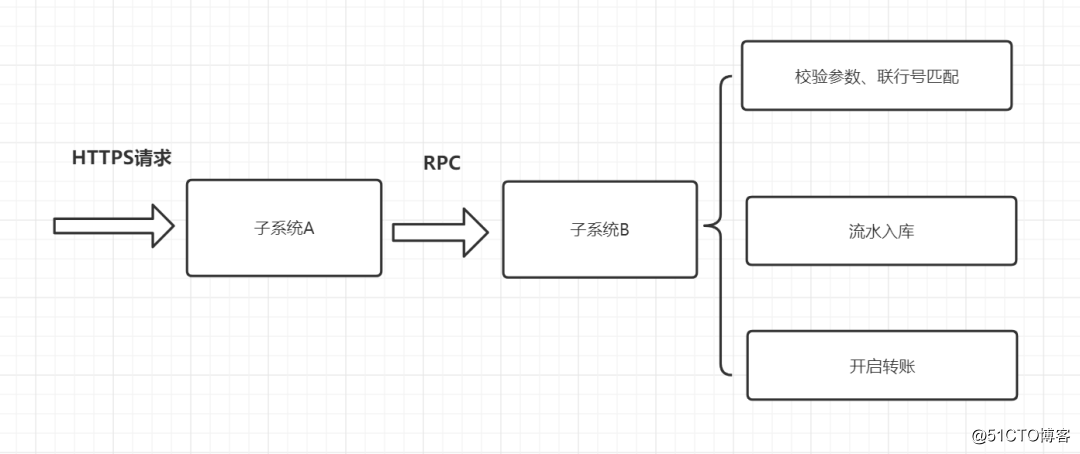
优化前:
//for循环单笔入库
for(TransDetail detail:list){
insert(detail);
}优化后:
// 批量入库,mybatis demo实现
<insert id="insertBatch" parameterType="java.util.List">
insert into trans_detail( id,amount,payer,payee) values
<foreach collection="list" item="item" index="index" separator=",">(
#{item.id}, #{item.amount},
#{item.payer},#{item.payee}
)
</foreach>
</insert>单位(ms) for循环单笔入库 批量入库
500条 1432 1153
1000条 1876 1425
打个比喻:假如你需要搬一万块砖到楼顶,你有一个电梯,电梯一次可以放适量的砖(最多放500),
你可以选择一次运送一块砖,也可以一次运送500,你觉得哪种方式更方便,时间消耗更少?耗时操作,考虑用异步处理,这样可以降低接口耗时。本次转账接口优化,匹配联行号的操作耗时有点长,所以优化过程把它移到异步处理啦,如下:
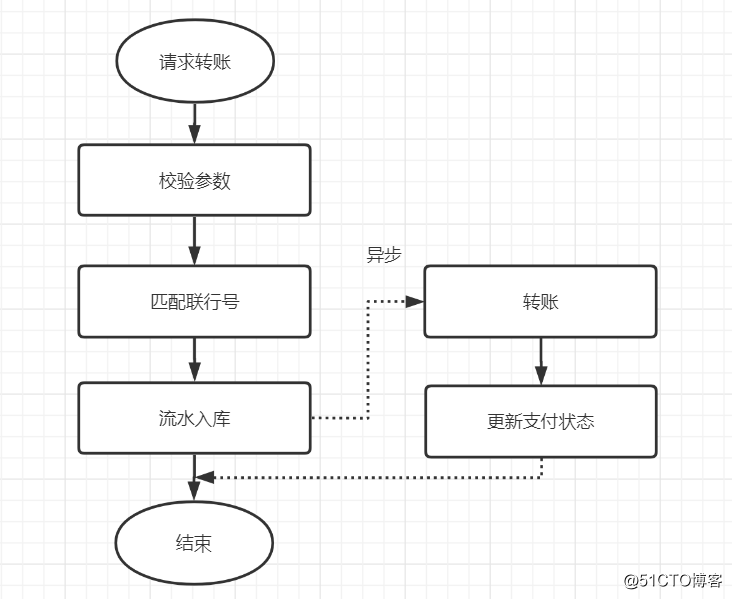
匹配联行号的操作异步处理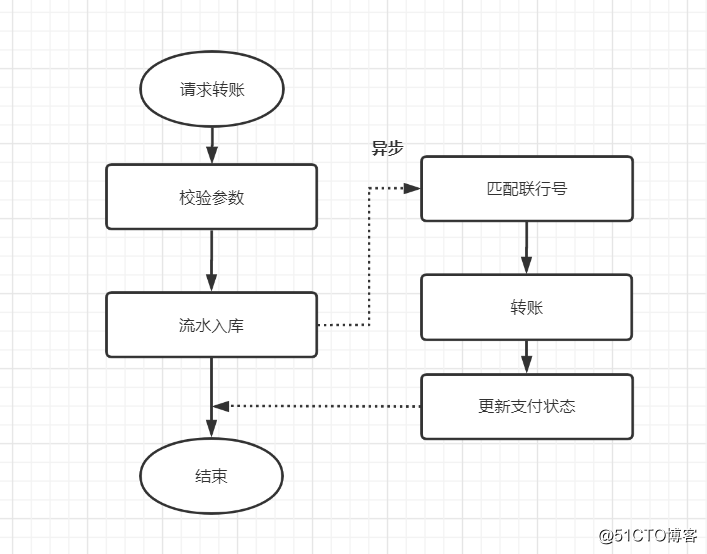
假设一个联行号匹配6ms
同步 异步
500条 3000ms ~
1000条 6000ms ~
在适当的业务场景,恰当地使用缓存,是可以大大提高接口性能的。这里的缓存包括:Redis,JVM本地缓存,memcached,或者Map等。
这次转账接口,使用到缓存啦,举个简单例子吧~
以下是输入用户账号,匹配联行号的流程图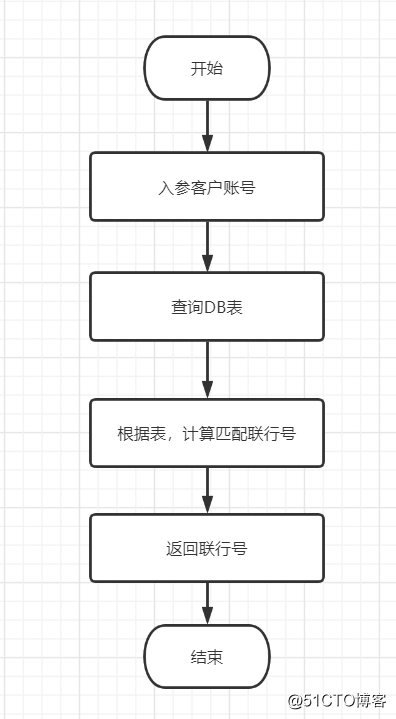
恰当使用缓存,代替查询DB表,流程图如下: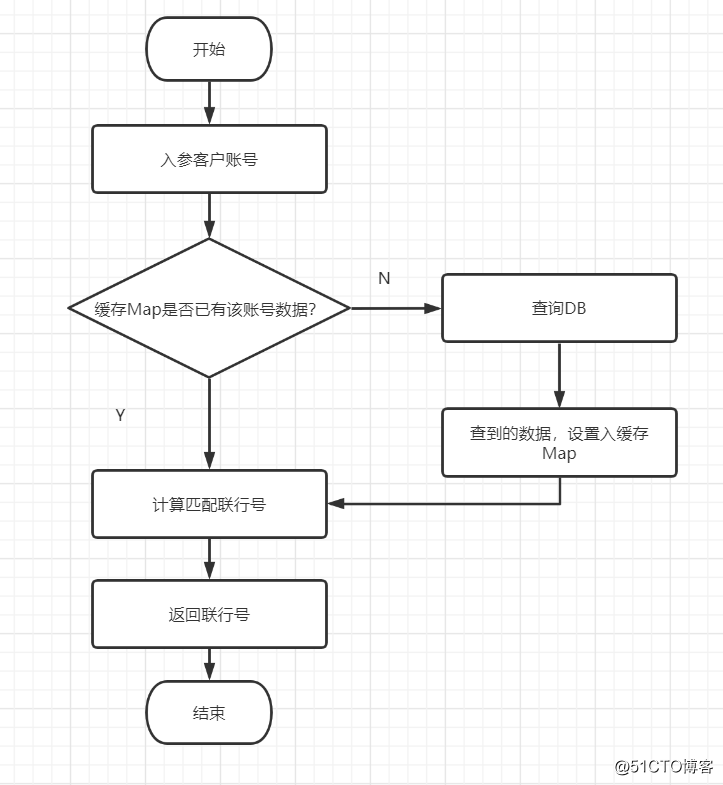
优化程序逻辑、程序代码,是可以节省耗时的。
我这里就本次的转账接口优化,举个例子吧~
优化前,联行号查询了两次(检验参数一次,插入DB前查询一次),如下伪代码:
punlic void process(Req req){
//检验参数,包括联行号(前端传来的payeeBankNo可以为空,但是如果后端没匹配到,会抛异常)
checkTransParams(Req req);
//Save DB
saveTransDetail(req);
}
void checkTransParams(Req req){
//check Amount,and so on.
checkAmount(req.getamount);
//check payeebankNo
if(Utils.isEmpty(req.getPayeeBankNo())){
String payeebankNo = getPayeebankNo(req.getPayeeAccountNo);
if(Utils.isEmpty(payeebankNo){
throws Exception();
}
}
}
int saveTransDetail(req){
String payeebankNo = getPayeebankNo(req.getPayeeAccountNo);
req.setPayeeBankNo(payeebankNo);
insert(req);
...
}优化后,只在校验参数的时候插叙一次,然后设置到对象里面~ 入库前就不用再查啦,伪代码如下:
void checkTransParams(Req req){
//check Amount,and so on.
checkAmount(req.getamount);
//check payeebankNo
if(Utils.isEmpty(req.getPayeeBankNo())){
String payeebankNo = getPayeebankNo(req.getPayeeAccountNo);
if(Utils.isEmpty(payeebankNo){
throws Exception();
}
}
//查询到有联行号,直接设置进去啦,这样等下入库不用再插入多一次
req.setPayeeBankNo(payeebankNo);
}
int saveTransDetail(req){
insert(req);
...
}很多时候,你的接口性能瓶颈就在SQL这里,慢查询需要我们重点关注的点呢。
我们可以通过这些方式优化我们的SQL:
加索引
有兴趣的朋友可以看一下我这篇文章呢,很详细的SQL优化点:
后端程序员必备:书写高质量SQL的30条建议
压缩传输内容,文件变得更小,因此传输会更快啦。10M带宽,传输10k的报文,一般比传输1M的会快呀;打个比喻,一匹千里马,它驮着一百斤的货跑得快,还是驮着10斤的货物跑得快呢?
如果数据太大,落地数据库实在是慢的话,可以考虑先用文件的方式保存,或者考虑MQ,先落地,再异步保存到数据库~
本次转账接口,如果是并发开启,10个并发度,每个批次1000笔数据,数据库插入会特别耗时,大概10秒左右,这个跟我们公司的数据库同步机制有关,并发情况下,因为优先保证同步,所以并行的插入变成串行啦,就很耗时。
优化前,1000笔先落地DB数据库,再异步转账,如下: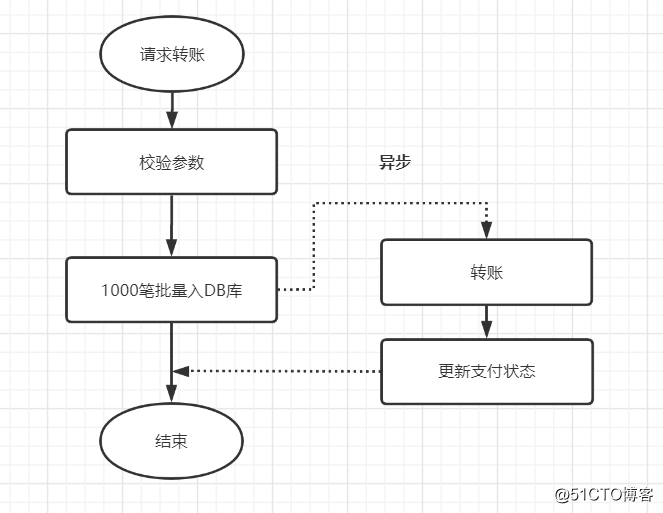
先保存数据到文件,再异步下载下来,插入数据库,如下: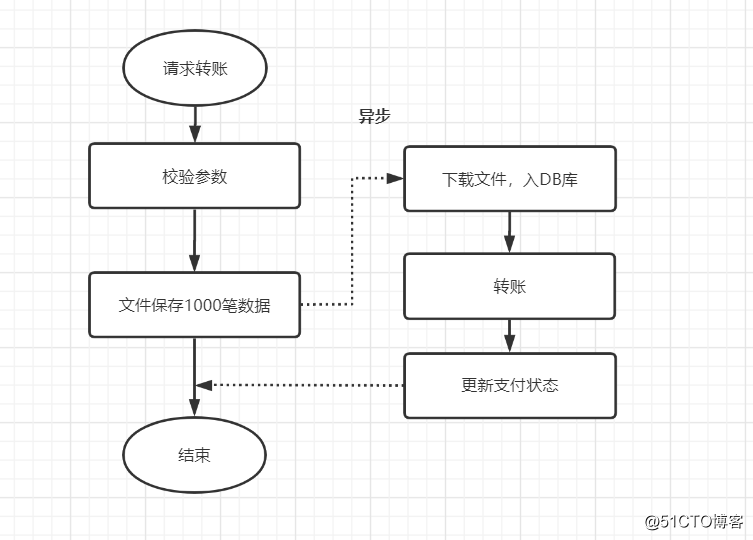
这点个人觉得还是很重要的,有些需求需要好好跟产品沟通的。
比如有个用户连麦列表展示的需求,产品说要展示所有的连麦信息,如果一个用户的连麦列表信息好大,你拉取所有连麦数据回来,接口性能就降下来啦。如果产品打桩分析,会发现,一般用户看连麦列表,也就看前几页~因此,奸笑,哈哈~ 其实,那个超大分页加载问题也是类似的。即limit +一个超大的数,一般会很慢的~~
本文呢,基于一次对外接口耗时优化的实践,总结了优化接口性能的八个点,希望对大家日常开发有帮助哦~嘻嘻,有兴趣可以逛逛我的github哈,本文会收藏到github里滴哈

标签:数据量 alt 实践总结 想法 查询 程序代码 index sem 处理
原文地址:https://blog.51cto.com/14989534/2547136