标签:不同 content sort distrib 信息 soft 它的 join storage
经典教程 | 基于Spark GraphX实现微博二度关系推荐导读:图计算是近几年大数据领域非常受关注的热点,社交网络中的好友关系推荐是一种典型图计算场景,本文是微博关系项目团队在二度关系计算中的一些实践,供高可用架构读者参考,作者为王舜、蒋生武、田瑞林。
二度关系是指用户与用户通过关注者为桥梁发现到的关注者之间的关系。目前微博通过二度关系实现了潜在用户的推荐。用户的一度关系包含了关注、好友两种类型,二度关系则得到关注的关注、关注的好友、好友的关注、好友的好友四种类型。
如果要为全站亿级用户根据二度关系和四种桥梁类型推荐桥梁权重最高 TopN 个用户,大致估算了下总关系量在千亿级别,按照原有的 Mapreduce 模式计算整个二度关系,需要以桥梁用户为 Key,把它的关注和粉丝两个亿级的表做 Join,如果活跃用户按照亿计,平均关注量按百计, Join 需要传输的数据量为几百 TB,同时 Mapreduce 在 shuffle 过程中中间结果需要多次排序和落地到 HDFS, 按这么实现内存和带宽无法满足,而且在时效上也不能满足业务需要。
二度关系推荐可抽象成在有向图中寻找到指定顶点的最短距离为 2 的所有顶点,将满足上述条件的顶点称为顶点的二跳邻居.这是经典的图问题,使用分布式图计算模型在算法描述和扩展性上有很大的优势。
下面我们把二度关系抽象成图后举例描述下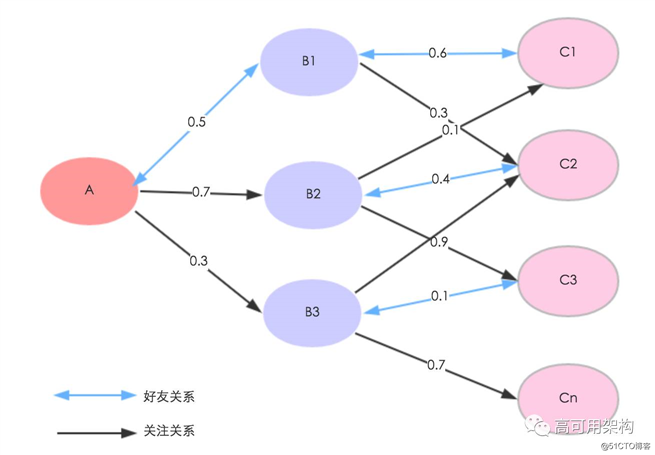
如上图所示,单向箭头表示关注关系,双向箭头表示好友关系,箭头上的数字表示边权重,如 A 到 C1 的桥梁权重 =B1(0.5+0.6)+B2(0.7+0.1)=1.9,推荐理由是好友的好友.我们需要将全站千亿级有效关注关系按上述模型计算求得 A 的二跳邻居 C,再去掉 C 中 A 直接关注的,最后将 C 按桥梁权重从高到低取 TopN。
目前业界主流的分布式图计算框架有 Giraph 和 GraphX。Giraph 是一个迭代的图计算系统。Giraph 计算的输入是由点和直连的边组成的图.例如,点可以表示人,边可以表示朋友请求.每个顶点保存一个值,每个边也保存一个值.输入不仅取决于图的拓扑逻辑,也包括定点和边的初始值.
Giraph 由 Yahoo 开源,原型是 Google 的 Pregel,在 2012 年已经成为 Apache 软件基金会的开源项目,并得到 Facebook 的支持,获得多方面的改进.
GraphX 是是 Apache 的开源项目 Spark 的重要部分,最早是伯克利 AMPLAB 的分布式图计算框架项目,后来整合到 Spark 中成为一个核心组件。GraphX 是 Spark 中用于图和图并行计算的 API,其实是 GraphLab 和 Pregel 在 Spark(Scala) 上的重写及优化,跟其他分布式图计算框架相比, GraphX 最大的优点,在 Spark 之上提供一栈式数据解决方案,可以方便且高效地完成图计算的一整套流水作业.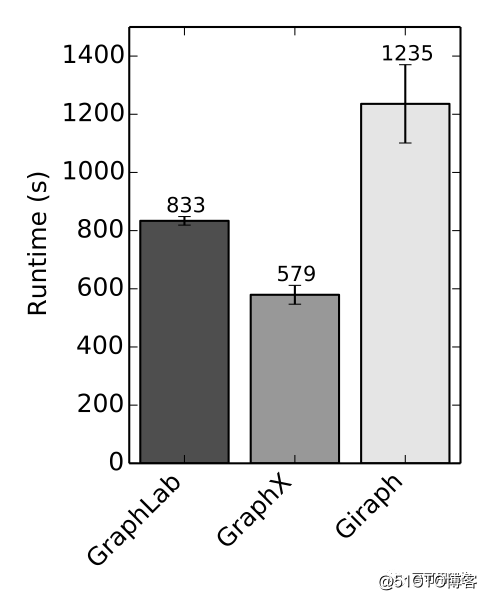
End-to-end PageRank performance (20 iterations, 3.7B edges)
GraphX 借助 Spark,将图表示为 RDD,一种分布式的能载入内存的数据集。较之 mapreduce 顺序处理数据,鉴于内存具有天然的随机访问特性, Spark 的大多数操作都在内存中完成,因此更适合处理图问题。GraphX 处理端到端的图迭代问题在运行时间上也快于 Giraph( 见上图 ),因此我们决定采用 GraphX 做二度关系挖掘和推荐。
属性图 : 属性图是一个有向多重图,它带有连接到每个顶点和边的用户定义的对象。有向多重图中多个并行 (parallel) 的边共享相同的源和目的地顶点.支持并行边的能力简化了建模场景,这个场景中,相同的顶点存在多种关系 ( 例如 likes 和 blocks),每个顶点由一个唯一的 long 型的 VertexID 作为顶点 ID。
一个属性图 Graph 由两个 RDD 构成分别是 :VertexRDD[VD] 和 EdgeRDD[ED],分别表示顶点和边。VD 和 ED 分别表示顶点和边的属性类型.他们和 RDD 一样,属性图是不可变的、分布式的、容错的.其中最关键的是不变性.逻辑上,所有图的转换和操作都产生了一个新图;物理上, GraphX 会有一定程度的不变顶点和边的复用优化,对用户透明。
下图是一个属性图的例子.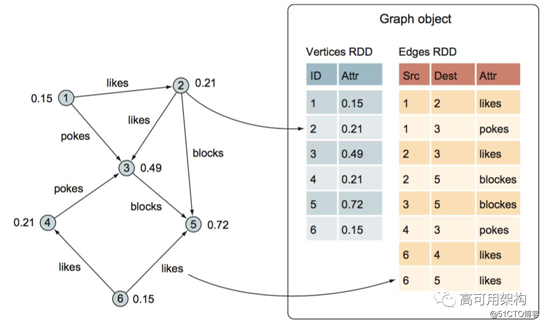
顶点和边 : 众所周知,图结构中最基本的要素是顶点和边。GraphX 描述的是拥有顶点属性和边属性的有向图。GraphX 提供顶点( Vertex)、边( Edge)、边三元组( EdgeTriplet)三种视图。GraphX 的各种图操作也是在这三种视图上完成的.如下图所示,顶点包含顶点 ID 和顶点数据( VD);边包含源顶点 ID( srcId)、目的顶点 ID( dstId)和边数据( ED).边三元组是边的扩展,它在边的基础上提供了边的源顶点数据、目的顶点数据.在许多图计算操作中,需要将边数据以及边所连接的顶点数据一起组成边三元组,然后在边三元组上进行操作.
GraphX 将图数据以 RDD 分布式地存储在集群的顶点上,使用顶点 RDD( VertexRDD)、边 RDD( EdgeRDD)存储顶点集合和边集合。顶点 RDD 通过按顶点的 ID 进行哈希分区,将顶点数据以多分区形式分布在集群上.边 RDD 按指定的分区策略( Partition Strategy)进行分区(默认使用边的 srcId 进行哈希分区),将边数据以多分区形式分布在集群.另外,顶点 RDD 中还拥有顶点到边 RDD 分区的路由信息——路由表.路由表存在顶点 RDD 的分区中,它记录分区内顶点跟所有边 RDD 分区的关系.在边 RDD 需要顶点数据时(如构造边三元组),顶点 RDD 会根据路由表把顶点数据发送至边 RDD 分区。如下图所示,按顶点分割方法将图分解后得到顶点 RDD、边 RDD 和路由表。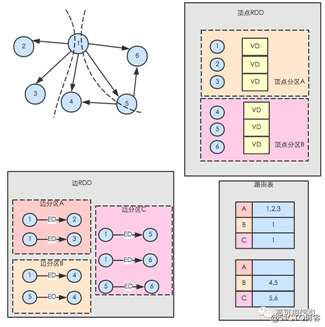
在图计算过程中,有些边的计算需要顶点数据,即需形成边三元组视图,如 PageRank 算法生出边的权值,这需要将顶点的权值发送至出边所在的边 RDD 分区。GraphX 依据路由表,从顶点 RDD 中生成与边 RDD 分区相对应的重复顶点视图( ReplicatedVertexView),它的作用是作为中间 RDD,将顶点数据传送至边 RDD 分区.重复顶点视图按边 RDD 分区并携带顶点数据的 RDD,如图下图所示,重复顶点分区 A 中便携带边 RDD 分区 A 中的所有的顶点,它与边 RDD 中的顶点是 co-partition(即分区个数相同,且分区方法相同).在图计算时, GraphX 将重复顶点视图和边 RDD 进行拉链( zipPartition)操作,即将重复顶点视图和边 RDD 的分区一一对应地组合起来,从而将边与顶点数据连接起来,使边分区拥有顶点数据.整个形成边三元组过程,只有在顶点 RDD 形成重复顶点视图中存在分区间数据移动,拉链操作不需要移动顶点数据和边数据.由于顶点数据一般比边数据要少的多,而且随着迭代次数的增加,需要更新的顶点数目也越来越少,重复顶点视图中携带的顶点数据也相应减少,这样就可以大大减少数据的移动量,加快执行速度。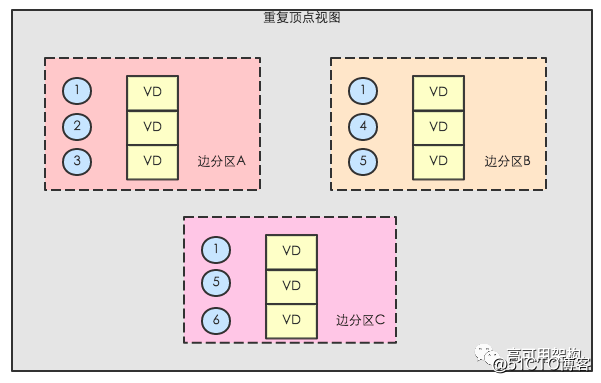
GraphX 在顶点 RDD 和边 RDD 的分区中以数组形式存储顶点数据和边数据,目的是为了不损失元素访问性能。GraphX 在分区里建立了众多索引结构,高效地实现快速访问顶点数据或边数据.在迭代过程中,图的结构不会发生变化,因而顶点 RDD、边 RDD 以及重复顶点视图中的索引结构全部可以重用,当由一个图生成另一个图时,只须更新顶点 RDD 和 RDD 的数据存储数组.索引结构的重用,是 GraphX 保持高性能的关键,也是相对于原生 RDD 实现图模型性能能够大幅提高的主要原因.
先构造一个属性图,每个顶点的属性 Attr 为 Map(dstId->distance),初始化为 Map( 该顶点 ID->0) 。然后进行两次迭代求解二度关系.
第一次迭代 : 遍历每条边,将 dst 顶点属性 dstAttr 中的跳数字段标记为 1 发给 src 顶点, src 收到后合并到顶点属性 srcAttr 里.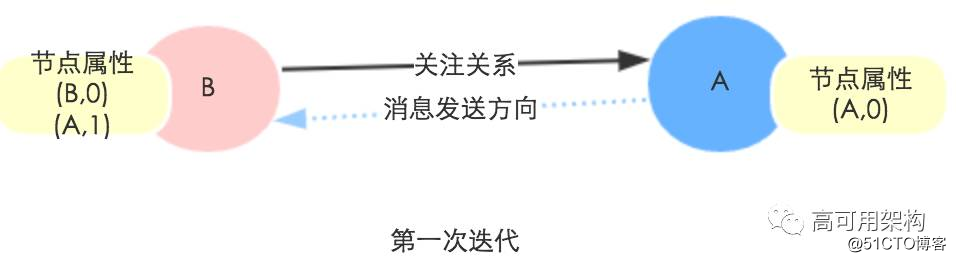
第二次迭代 : 遍历边筛选出 dstAttr 里面跳数为 1 的 Key-Value 发给对应的 src 顶点,并将 dstId 加入桥梁顶点,最后聚合这些消息得到所有 2 跳邻居。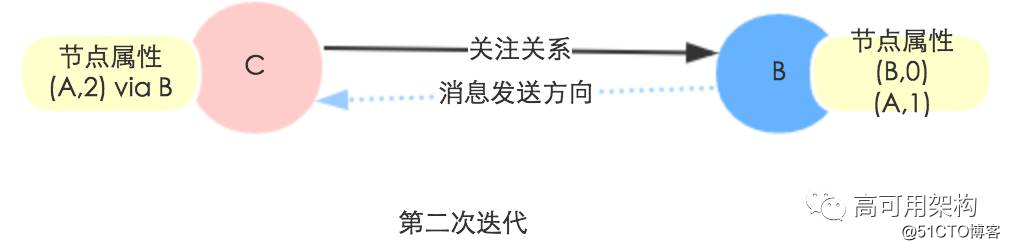
最佳实践
如上所述, Graphx 使用的是 Vertex-Cut( 点分割 ) 方式存储图,用三个 RDD 存储图数据信息:VertexTable(ID, data): ID 为顶点 ID,data 为顶点属性
EdgeTable(pid, src, dst, data): pid 为分区 ID,src 为源顶点 ID , dst 为目的顶点 ID, data 为边属性
RoutingTable(ID,pid): ID 为顶点 ID, pid 为分区 ID
点分割存储实现如下图所示: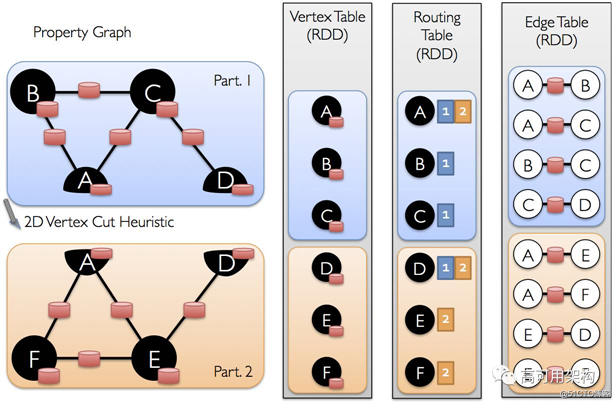
用户可指定不同的分区策略.分区策略会将边分配到各个边分区,顶点 Master 分配到各个顶点分区,重复顶点视图会缓存本地边关联点的副本.划分策略的不同会影响到所需要缓存的副本数量,以及每个边分区分配的边的均衡程度,需要根据图的结构特征选取最佳策略.
下图展示了 GraphX 自带的 4 种边分区模式.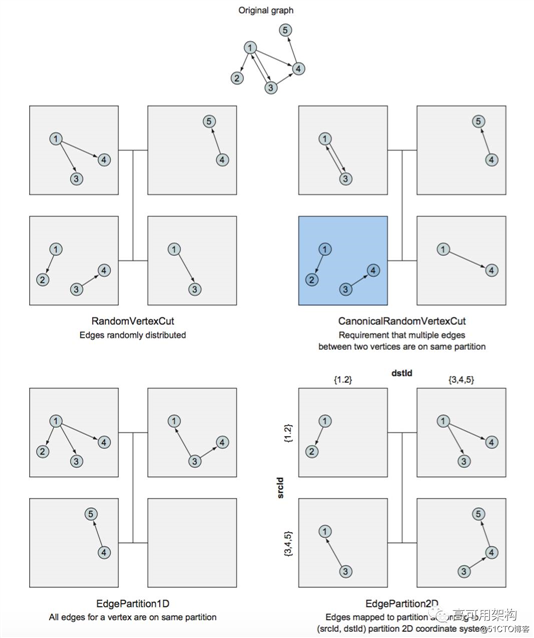
考虑到我们具体应用场景,在经过第一次迭代后图中的桥梁顶点 B 将会收到它关注顶点发来的消息 , 其属性会变大约 100 倍.在第二次迭代的时候,如果同一个顶点 B 被分到不同的边分区,在其属性 update 的时候也会被复制多份到重复顶点视图,根据我们图的规模,这个复制量无论是内存和带宽都扛不住.
我们分区的思路是考虑到消息发送方向是按照粉丝 (src) 方向,尽量把同 dstId 的分到同一分区里面以降低 dstAttr 的副本数.如下图所示,避免 dst 为超级顶点 ( 关注大量用户,同时有大量粉丝 ) 在属性发生变更时被大量复制撑爆内存.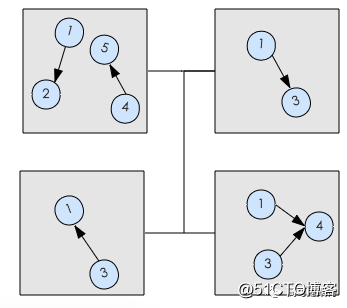
每一次 task 只能处理一个 partition 的数据,这个值太小了会导致每片数据量太大,导致内存压力,或者诸多 executor 的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降低。推荐分区数是集群 CPU 总核数的 3 到 4 倍。
aggregateMessages 是 Graphx 最重要的 API, 1.2 版本添加的新函数,用于替换 mapReduceTriplets。目前 mapReduceTriplets 最终也是使用兼容的 aggregateMessages。改用 aggregateMessages 后,性能提升 30%。GraphX 的 pregel 也能实现邻边消息聚合,在二度关系求解场景下未被采用,因为其终止条件之一是本次收到消息的活跃顶点数 activeMessages 为 0,每次迭代都会调用 activeMessages = messages.count() 计算活跃顶点数。但是 count() 这个 reduce 方法会产生一个新的 job,非常耗时.根据我们的场景,迭代次数是确定的两次,因此选用 aggregateMessages,其返回值即是收到消息的活跃顶点 VertexRDD,避免了在迭代过程中使用 count。
aggregateMessages 在逻辑上分为三步:
它实现分为 map 阶段和 reduce 阶段.
phase1.aggregateMessages
map
GraphX 使用顶点 RDD 更新重复顶点视图.重复顶点视图与边 RDD 进行分区拉链( zipPartitions)操作,将顶点数据传往边 RDD 分区,实现边三元组视图。对边 RDD 进行 map 操作,依据用户提供的函数为每个边三元组产生一个消息( Msg),生成以顶点 ID、消息为元素的 RDD,其类型为 RDD[(VertexId, Msg)]。
phase2.aggregateMessages
reduce
reduce 阶段首先对 step1 中的消息 RDD 按顶点分区方式进行分区(使用顶点 RDD 的分区函数),分区后的消息 RDD 与该图的顶点 RDD 元素分布状况将完全相同.在分区时, GraphX 会使用用户提供的聚合函数合并相同顶点的消息,最终形成类似顶点 RDD 的消息 RDD。
另外,在使用 aggregateMessages 的时候需要注意参数 tripletFields,这个参数用来指定发送的消息域,默认发所有 (src 属性 ,dst 属性和 edge 属性 )。根据我们的模型和算法,消息发送方向是关注的反方向,数据只需要 dstAttr,因此可将 tripletFields 设置为 TripletFields.Dst。这样只会复制顶点的 dst 属性,降低网络传输开销.
Spark 默认使用的是 Java
Serialization,性能、空间表现都比较差,官方推荐的是 Kryo
Serialization,序列化速度更快,压缩率也更高.在 Spark UI 上能够看到序列化占用总时间开销的比例,采用 Kryo 序列化后 RDD 存储比 Java 序列化节省大约 9 倍的空间,见下图。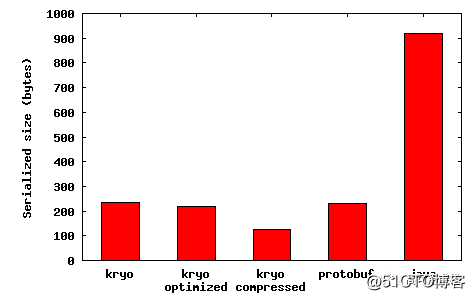
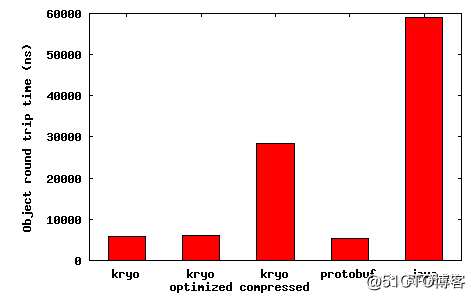
图片来源:https://github.com/EsotericSoftware/kryo/wiki/Benchmarks-for-Kryo-version-1.x
一旦启用 Kryo 序列化机制以后,可带来如下几点性能提升 :
在使用的时候需要注意 : 如果是我们自己定义的数据类型,需要在 Kryo 中注册.代码如下:
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("Spark.serializer", "org.Apache.Spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)
下面这张图展示了 Spark on YARN 内存结构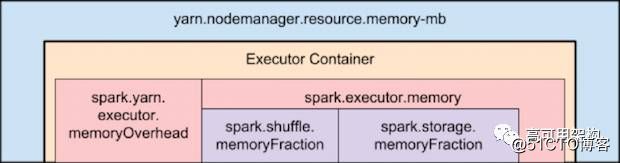
在实际二度关系求解中,每个 stage 以 shuffle 为界,上游 stage 做 map task,每个 map task 将计算结果数据分成多份,每一份对应到下游 stage 的每个 partition 中,并将其临时写到磁盘,该过程叫做 shuffle write ;下游 stage 做 reduce task,每个 reduce task 通过网络拉取上游 stage 中所有 map task 的指定分区结果数据,该过程叫做 shuffle read,最后完成 reduce 的业务逻辑,如下图所示,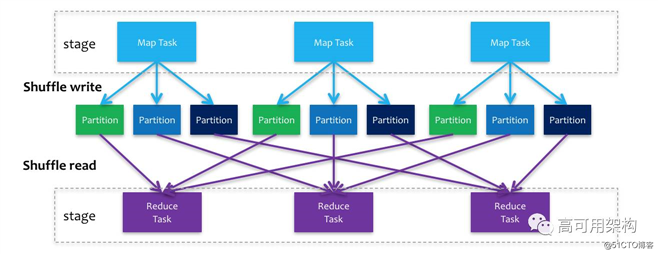
map task 将 R 个 shuffle 文件写盘 ( 采用 SortShuffleManager),其中 R 为 reduce task 的数目。在写盘前,会先将数据写入内存 buffer,当 buffer 满了才会溢写到磁盘文件中,Reduce task 会拉取自己需要的数据,如果 Map 和 Reduce 发生在不同的机器上,便会产生网络传输开销。实践中,如果 shuffle 时内存比较紧张,就需要适当调整 Spark.shuffle.memoryFraction 参数,这个参数表示 executor 内存中分配给 shuffle read task 进行聚合操作的内存比例,默认值 0.2,可将其调大,避免由于内存不足导致聚合过程中频繁读写磁盘.
其次是将文件压缩方式设置为 snnapy 压缩,取代原有的 lzf,可减少 map 阶段 io 文件 buffer 的内存使用量
( 400k per file-> 32k per file) conf.set("Spark.io.compression.codec","org.Apache.Spark.io.SnnapyCompressionCodec")
同时注意上图中的 Spark.storage.memoryFraction,这个参数表示 RDD Cache 所用的内存比例,默认为 0.6。我们使用 Kryo 序列化后, RDD 内存占用缩减到了原来的 1 / 9,因此将这个参数调小为 0.3,腾出更多的内存给 executor 使用。
在实际运行中还出现过如下错误
Java.util.concurrent.TimeoutException:
Futures timed out after [120 second]
解决
由网络或者 GC 引起, worker 或 executor 没有接收到 executor 或 task 的心跳反馈。提高 Spark.network.timeout 的值,根据情况改成 300(5min) 或更高。默认为 120(120s).
本文主要介绍了 Spark GraphX 一些基本原理,以及用于微博二度关系推荐中的一些思考及实践经验,经过实际场景运行,基于 GraphX 做的好友的好友的关系推荐,在时效和推荐转化率上均有更好的效果。
#
1.http://spark.apache.org/docs/latest/graphx-programming-guide.html
2.GraphX A Resilient Distributed Graph System on Spark annotated, https://amplab.cs.berkeley.edu/wp-content/uploads/2013/05/grades-graphx_with_fonts.pdf
3.Spark Graphx In Action
4.https://endymecy.gitbooks.io/spark-graphx-source-analysis/content/vertex-cut.html
5.https://spark.apache.org/docs/latest/tuning.html
6.http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/
7.Optimizing Shuffle Performance in Spark, https://people.eecs.berkeley.edu/~kubitron/courses/cs262a-F13/projects/reports/project16_report.pdf
8.https://www.iteblog.com/archives/1672
9.http://sharkdtu.com/posts/spark-shuffle.html
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。

经典教程 | 基于Spark GraphX实现微博二度关系推荐
标签:不同 content sort distrib 信息 soft 它的 join storage
原文地址:https://blog.51cto.com/14977574/2547417