标签:order compress ase input user use put 文件中 分割
在hive的日常使用中,经常需要将hive表中的数据导出来,虽然hive提供了多种导出方式,但是面对不同的数据量、不同的需求,如果随意就使用某种导出方式,可能会导致导出时间过长,导出的结果不满足需求,甚至造成集群资源不必要的浪费。因此本文主要对hive支持的几种导出方式的使用进行整理,并给出每种导出方式的使用场景,便于指导操作者能够选取最佳的导出方式。
(1)导出到本地文件系统
示例如下:
|
insert overwrite local directory ‘/home/data/‘ select * from hive_table; |
(2)导出到HDFS
导入到HDFS和导入本地文件类似,去掉HQL语句的LOCAL就可以了。
示例如下:
|
insert overwrite directory ‘/home/data/‘ select * from hive_table; |
利用insert overwrite将查询结果导出本地或hdfs的方式可以指定导出的数据格式和字段的分割符,示例如下:
|
insert overwrite local directory ‘/home/data/‘ select * from hive_table row format delimited fields terminated by ‘\t’ #字段间用\t分割 stored as textfile; #导出文件的存储格式为textfile |
使用场景:
1) 由于这种方式导出数据时会启动MApReduce任务来完成导出,所以这种方式不适合导出数据量极少的情况,因为数据量很少时也会启MapReduce任务消耗集群资源,且导出速度比不启MapReduce导出方式的速度要慢;
2) 适用于对导出数据格式有要求的场景,如:指定数据文件类型、字段分割符;
3) 这种方式导出的路径只能指定到文件夹,不支持导出到指定的文件中,且在文件夹下可能产生多个文件,并非仅一个文件,所以此方式适用于将数据导出到本地或HDFS目录下,且对存储数据的文件名和文件数量无要求。
使用beeline执行示例:
|
beeline -u jdbc:hive2://hadoop1:10000/default "select * from hive_table" > /home/data/data.txt |
使用hive -e执行示例:
|
hive -e "select * from hive_table" > /home/data/data.txt; |
注:如果追加,使用“>>”重定向到文件中;如果覆盖,使用“>”重定向到文件中。
适用场景:
1)这种方式导出数据时不会启动MapReduce任务,适用于数据量较少的情况;
2)此方式支持指定导出的文件名,导出的结果只能存放到本地,且只生成一个文件,所以适用于将hive数据导出到本地的某个文件中的场景。
3)不支持指定导出文件的分割符。
示例如下:
|
insert into table new_table select * from hive_table; |
适用场景:适用于将导出的结果存放到另一张hive表中,便于通过sql做二次分析。
示例如下:
|
export table hive_table to ‘/home/data/‘; |
适用场景:这种方式只能导出数据到HDFS上,但是导出的速度比较快,因此适用于hive数据的批量迁移。
将hive数据拷贝到HDFS示例:
|
hdfs dfs -cp /user/hive/warehouse/hive_table /home/data/; |
将hive数据保存到本地:
|
hdfs dfs -get /user/hive/warehouse/hive_table /home/data/; |
使用场景:适用于数据文件恰好是用户需要的格式,只需要拷贝文件或文件夹就可以。
Sqoop是连接关系型数据库和hadoop的桥梁,主要有两个方面:一是将关系型数据库的数据导入到hadoop及其相关的系统中,如Hive和Hbase;二是将数据从Hadoop系统里抽取并导出到关系型数据库中。这里以将hive数据导入到mysql库为例。
示例如下:
|
./sqoop export \ --connect jdbc:mysql://192.168.0.70:3306/sqooptest \ #数据库连接url --username root \ #数据库用户名 --password 123456 \ #数据库密码 --table person_hive \ #要导入到的关系数据库表 --num-mappers 1 \ #启动N个map来并行导出数据 --export-dir /user/hive/warehouse/sqooptest.db/person #导出hive表数据存储路径 --input-fields-terminated-by "\t" #字段间的分隔符 |
适用场景:这种方式适用于将hive表数据导入到关系数据库中。
以上共整理了6种hive数据导出的方式,每种导出方式都有各自的应用场景,在选择导出方式时,首先应该考虑导出数据的存储位置,主要包括:本地、HDFS、Hive表、关系型数据库;其次是导出数据的存储格式,如果对导出格式有要求,一定要从可以指定数据格式的方式中选;最后是导出的数据量,如果数据量小,避免选择会启MapReduce任务的导出方式,可以减少导出时间。
导出的hive数据时的注意事项:
hive导出时需要需要修改yarn的队列和对输出结果进行压缩。
(1)调整yarn的队列
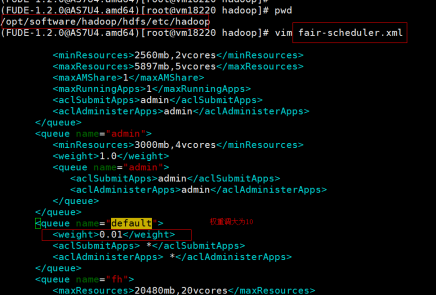
步骤一:调整主备节点上的默认队列的优先级,调整为10。如图:
步骤二:在主备节点上执行以下命令:
|
yarn rmadmin -refreshQueues |
(2)在执行语句中加入对结果压缩的配置,配置内容如下:
|
set hive.exec.compress.output=false;set mapred.output.compress=false; |
使用示例如下:
|
hive -e "set hive.exec.compress.output=false;set mapred.output.compress=false;insert overwrite local directory ‘$dpath‘ row format delimited fields terminated by ‘\t‘ NULL DEFINED AS ‘‘ select * from $ttb;" |
标签:order compress ase input user use put 文件中 分割
原文地址:https://www.cnblogs.com/sheng-sjk/p/13940642.html