标签:code 运算 情况 loading 就是 思路 info 存储 状态
(一)RDD、DataFream、DataSet 理解
1. RDD理解
(1) RDD定义为弹性分布式数据集合。
MR运算之间数据共享差:
MR的计算之间的数据共享只能通过将数据写入外部存储系统。后一步计算需要从外部存储系统中加载进来的方式进行。
Spark 思路相反,设计了一种抽象-RDD(弹性分布式数据集合),用户可以直接控制数据的共享。
- 用户可以控制存储到磁盘还是内存。解决了计算之间数据共享差的问题。
- 用户控制数据的分区方法。
- 用户控制数据集上等的操作。
(2) 弹性怎么理解
- 自定进行内存和磁盘两种存储方式的切换。
- TASK 和 Stage执行出差会重试。
- 使用多用户管理。允许应用程序弹性的扩展和缩减计算资源。
(3) 容错性
- 对于有检查操作的RDD,某个分区的数据丢失,RDD记录有足够的信息(根据血缘关系)来重新计算。而且只需要计算该分区数据即可。这样减小数据恢复的代价。
(4) RDD的操作包含 创建操作、转换操作、控制操作和行动操作
- 创建操作
其一:来自内存集合和外部存储系统的数据,生成RDD。其二:通过转换操作生成RDD。
- 转换操作:transform 操作。转换操作是懒执行。
- 控制操作:缓存命令等(缓存内存或者磁盘)。
- 行动操作:将结果转成scala集合或者变量。
(5) 后续
(二)基本概念
架构概念
- Application
Spark的运行程序,包含一个driver和若干个executor
- Driver
运行application的main方法。并创建spark Context
- Executor
- Spark Context:
spark应用程序的入口,负责调度各运算资源,协调workNode的executor
- Job
Spark Context 提交的具体的action操作。
- Stage
每个job被分成多个计算小组。每个小组称之为stage。也称之为TaskSet。
对job按照宽依赖进行分割。成不同的stage。
- Task
运行在executor上的运算单元。
- DAG Scheduler
能根据job构建Stage的DAG,并把stage提交给Task Scheduler
- Task Scheduler
将taskSet提交给work Node集群并返回结果。
- RDD
弹性分布式数据集合。是spark的核心模块。
- Transformations
Spark API的一种类型。对RDD的一种加工。返回结果也是RDD。是懒执行。
- Action
Spark API的一种类型。对RDD的一种加工。返回结果不是RDD。是Scala的一种集合。
(三)任务提交(不同部署模式)
Spark的运行模式分为两种。Standalone 和 YARN 两种。
1. Standalone
使用spark原生的资源管理器。Standalone模式有重要的4部分组成。Driver、master、worker、executor。
(1) Driver:是一个运行的进程。我们编写的spark程序就运行在driver上。
(2) Master:是一个进程。负责资源的调度和分配。并进行集群的监控等职责。
(3) Worker:是一个进程。核心工作有两个。A.使用内存存储RDD的部分数据(RDD是分布式数据集)。B.启动其它线程(executor),对RDD进行运算。
(4) Executor:一个worker上可以启动多个executor。Executor可以多个线程来运行task。
Client 和 cluster 模式的区分标准在于。Driver是否运行在集群上。如果运行在集群上就是cluster模式。没有运行在集群上就是client模式。
(1) Standalone client模式
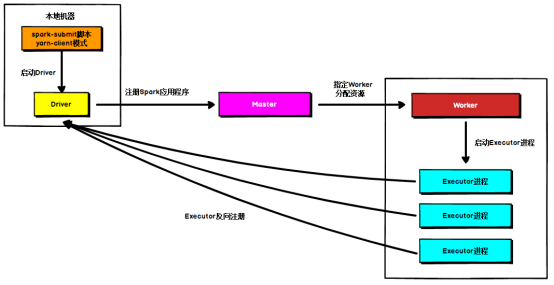
- Driver 在任务提交的机器上(client)运行。
- Driver向Master注册应用程序。
- Master根据实际情况分配资源。并通知资源对应的worker。
- Worker 启动container进行。Container向driver反向注册自己。
====================================任务提交流==============================
- DAG scheduler 根据job的宽依赖拆分成stage的DAG。然后提交给TASK Scheduler,并由TASK scheduler 提交给executor
- 各个executor 实时上报task的运行状态。
- Driver 在job运行完成后,向Master 注销自己。
(2) Standalone cluster模式
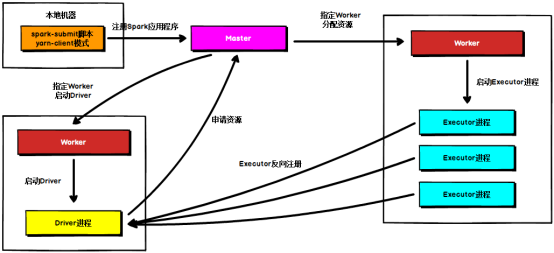
- 本地机器向master提交应用程序。
- Master指定一个worker 的executor启动driver。
- Driver向Master注册并申请计算资源。
- Master分配资源并指定对应的worker,启动executor。各个executor向driver反向注册。
================================任务运行流程=================================
- DAG scheduler 根据job的宽依赖拆分成stage的DAG。然后提交给TASK Scheduler,并由TASK scheduler 提交给executor
- H.各个executor 实时上报task的运行状态。
- I.Driver 在job运行完成后,向Master 注销自己。
2. YARN
YARN client 模式
运行在Hadoop的资源管理器YARN之上。
(1) YARN client 模式
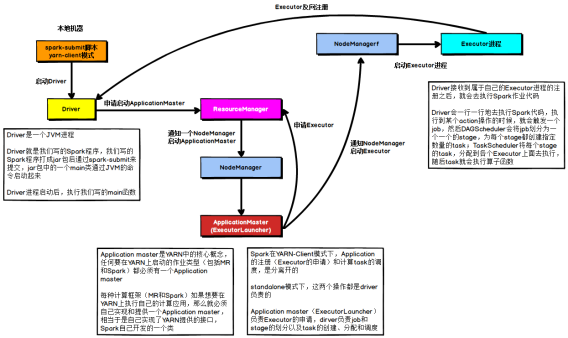
- Driver运行在任务提交的机器上。Driver 向RM申请运行Application Master。
- RM 分配一个Node Manager 的container ,启动Application Master。AM向RM的ASM注册自己。
- AM向RM申请job运算资源Executor。
- AM向资源对应的Node Manager 发送命令,启动executor 。各个executor向AM反向注册自己。
- 各个executor 实时汇报task的运行情况。
- Job运行完成后。AM向RM注销自己。
(2) YARN cluster 模式
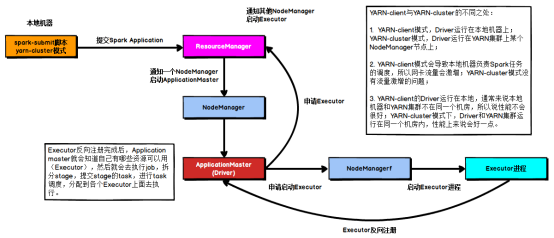
- 任务提交给RM。RM寻找一个合适的Node Manager 的container 。启动driver和Application Master。
- AM向RM注册并申请资源。
- AM对资源对应的Node Manager 发送命令,启动executor
- Executor 向AM反向注册自己。
- DAG Scheduler 根据job的宽依赖拆分构建stage的DAG,并提交给Task Scheduler .由Task Scheduler 提交给executor并运行。
- Executor 实时汇报运行情况。
- 运行结束后,AM向RM注销自己。
spark学习(一) --spark基本概念和任务调度
标签:code 运算 情况 loading 就是 思路 info 存储 状态
原文地址:https://www.cnblogs.com/maopneo/p/13948024.html