标签:逻辑 基本 tin 技术 inf img templates 地址 jsb
Alertmanager 邮件报警展示报警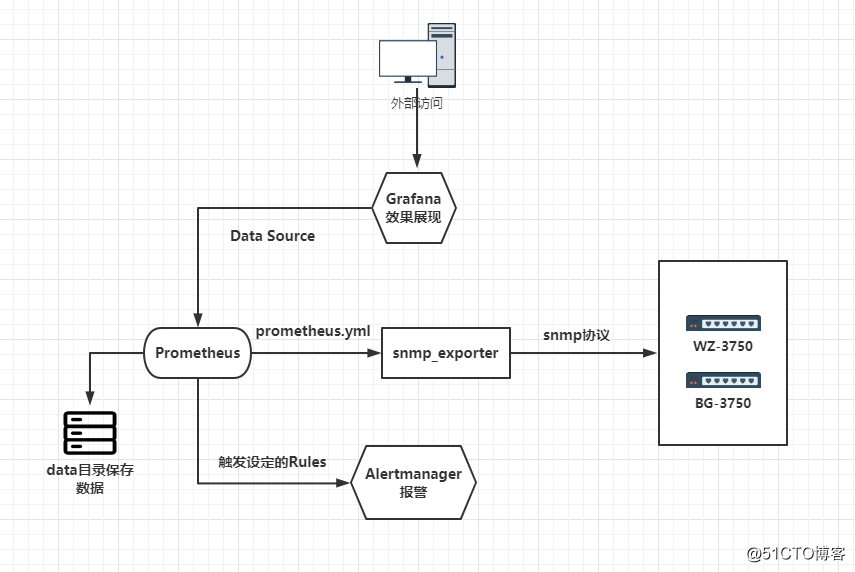
[root@localhost alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: ‘smtp.163.com:25‘
smtp_from: ‘***@163.com‘
smtp_auth_username: ‘***@163.com‘
smtp_auth_password: ‘PASSWORD‘
route:
# group_by: [‘alertname‘]
group_wait: 10s
group_interval: 1m
repeat_interval: 1m
receiver: ‘jsb‘
receivers:
- name: ‘jsb‘
email_configs:
- to: "TARGET_ADDRESS@163.com"
# 使用 alertmanager 自带的 amtool 工具检查一下alertmanager.yml 配置文件书写是否正确
[root@localhost alertmanager]# ./amtool check-config alertmanager.yml
Checking ‘alertmanager.yml‘ SUCCESS
Found:
- global config
- route
- 0 inhibit rules
- 1 receivers
- 0 templates
[root@localhost alertmanager]# systemctl restart alertmanager
[root@localhost alertmanager]# netstat -tnlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 20451/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 20561/master
tcp6 0 0 :::22 :::* LISTEN 20451/sshd
tcp6 0 0 :::3000 :::* LISTEN 11761/docker-proxy
tcp6 0 0 ::1:25 :::* LISTEN 20561/master
tcp6 0 0 :::9116 :::* LISTEN 27273/snmp_exporter
tcp6 0 0 :::9090 :::* LISTEN 25929/docker-proxy
tcp6 0 0 :::9093 :::* LISTEN 4509/alertmanager
tcp6 0 0 :::9094 :::* LISTEN 4509/alertmanager
cat prometheus.yml
···
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.202.239:9093 # Alertmanager 的ip地址
# Load rules once and periodically evaluate them according to the global ‘evaluation_interval‘.
rule_files:
- "rules/*.rules"
# - "second_rules.yml"
···
[root@e36188d4c068 prometheus]# cat rules/test.rules
groups:
- name: test_rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
serverity: error
annotations:
summary: "Instance {{ $labels.instance}} shutdown one minutes!!!"
description: "{{ $labels.instance }} of job {{ $labels.job }} yi shutdown 1 minutes"
[root@e36188d4c068 prometheus]# cat rules/cpu.rules
groups:
- name: host
rules:
- alert: NodeCPUUsage
annotations:
description: "{{ $labels.instance }} CPU > 60% (The current value: {{ $value }})"
summary: "Instance {{ $labels.instance }} too high!!!"
expr: avgBusy1 > 60
for: 1m
labels:
severity: warning
# 使用 promtool 检查配置文件书写是否正确,然后重启 prometheus
[root@e36188d4c068 prometheus]# ./promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 2 rule files found
Checking rules/cpu.rules
SUCCESS: 1 rules found
Checking rules/test.rules
SUCCESS: 1 rules found
[root@e36188d4c068 prometheus]# systemctl restart prometheus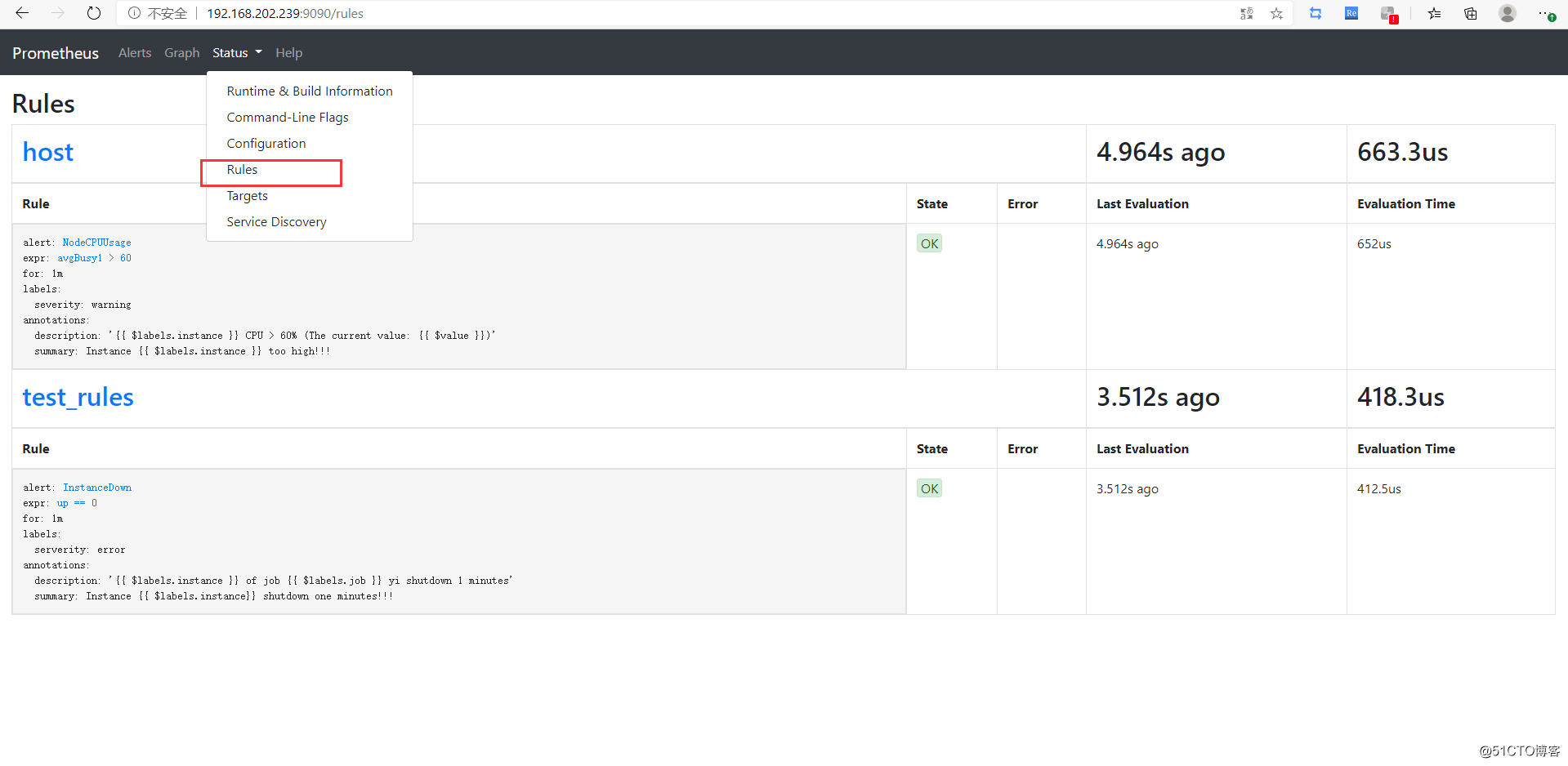
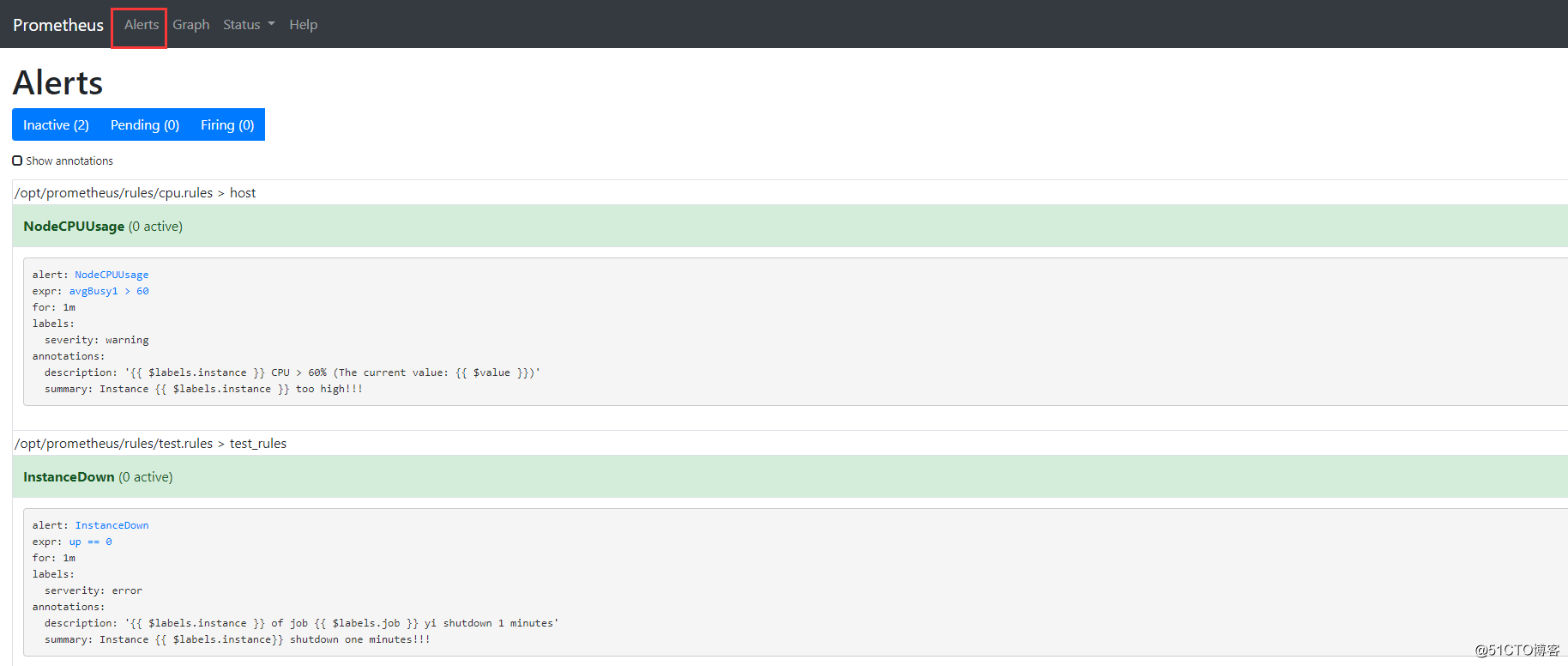
我们这正常的交换机 cpu 使用率是 35% 左右,会有一点浮动,但是基本上就是这样,通过修改 rules/cpu.rules 中的阈值,进行触发邮件报警;
expr: avgBusy1 > 30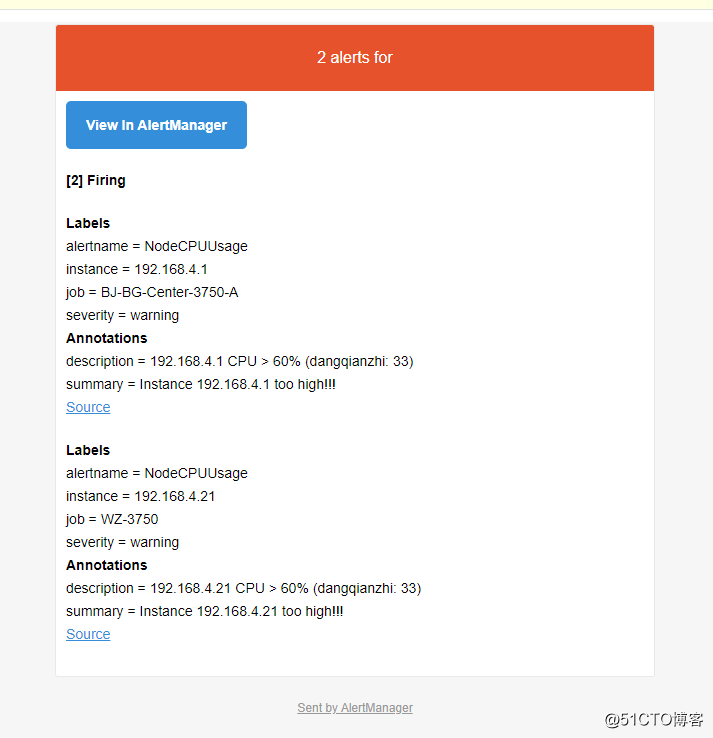
(四) Prometheus 监控思科交换机---Alertmanager 邮件报警展示报警
标签:逻辑 基本 tin 技术 inf img templates 地址 jsb
原文地址:https://blog.51cto.com/liujingyu/2541782