标签:好的 统一 个数 重要功能 同步 设计 短信 row 文本
RabbitMQ使用发送方确认模式,确保消息正确地发送到RabbitMQ。
发送方确认模式:将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的ID。一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack(not acknowledged,未确认)消息。
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
channel.confirm_delivery()
接收方消息确认机制:消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。
这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。
下面罗列几种特殊情况:
在消息生产时,MQ内部针对每条生产者发送的消息生成一个inner-msg-id,作为去重和幂等的依据(消息投递失败并重传),避免重复的消息进入队列;
在消息消费时,要求消息体中必须要有一个bizId(对于同一业务全局唯一,如支付ID、订单ID、帖子ID等)作为去重和幂等的依据,避免同一条消息被重复消费。
由于TCP连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ使用信道的方式来传输数据。信道是建立在真实的TCP连接内的虚拟连接,且每条TCP连接上的信道数量没有限制。
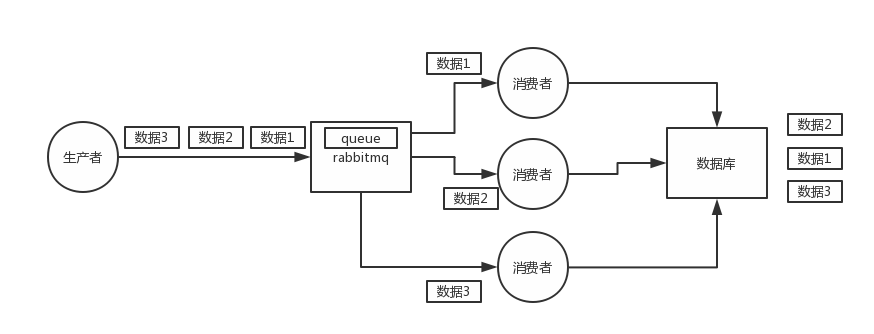
若该队列至少有一个消费者订阅,消息将以循环(round-robin)的方式发送给消费者。每条消息只会分发给一个订阅的消费者(前提是消费者能够正常处理消息并进行确认)。
从概念上来说,消息路由必须有三部分:交换器、路由、绑定。生产者把消息发布到交换器上;绑定决定了消息如何从路由器路由到特定的队列;消息最终到达队列,并被消费者接收。
常用的交换器主要分为一下三种:
消息持久化的前提是:将交换器/队列的durable属性设置为true,表示交换器/队列是持久交换器/队列,在服务器崩溃或重启之后不需要重新创建交换器/队列(交换器/队列会自动创建)。
如果消息想要从Rabbit崩溃中恢复,那么消息必须:
RabbitMQ确保持久性消息能从服务器重启中恢复的方式是,将它们写入磁盘上的一个持久化日志文件,当发布一条持久性消息到持久交换器上时,Rabbit会在消息提交到日志文件后才发送响应(如果消息路由到了非持久队列,它会自动从持久化日志中移除)。一旦消费者从持久队列中消费了一条持久化消息,RabbitMQ会在持久化日志中把这条消息标记为等待垃圾收集。如果持久化消息在被消费之前RabbitMQ重启,那么Rabbit会自动重建交换器和队列(以及绑定),并重播持久化日志文件中的消息到合适的队列或者交换器上。
RabbitMQ是 消息投递服务,在应用程序和服务器之间扮演路由器的角色,而应用程序或服务器可以发送和接收包裹。其通信方式是一种 “发后即忘(fire-and-forget)” 的单向方式。
其中消息包含两部分内容:有效载荷(payload)和标签(label)。

#rabbitmq spring.rabbitmq.host=127.0.0.1 主机 spring.rabbitmq.port=5672 端口 spring.rabbitmq.username=guest 用户名 spring.rabbitmq.password=guest 密码 spring.rabbitmq.virtual-host=/ #\u6D88\u8D39\u8005\u6570\u91CF spring.rabbitmq.listener.simple.concurrency= 10 消费者的数量 出队 spring.rabbitmq.listener.simple.max-concurrency= 10 #\u6D88\u8D39\u8005\u6BCF\u6B21\u4ECE\u961F\u5217\u83B7\u53D6\u7684\u6D88\u606F\u6570\u91CF spring.rabbitmq.listener.simple.prefetch= 1 每次从队列中取1个 #\u6D88\u8D39\u8005\u81EA\u52A8\u542F\u52A8 spring.rabbitmq.listener.simple.auto-startup=true #\u6D88\u8D39\u5931\u8D25\uFF0C\u81EA\u52A8\u91CD\u65B0\u5165\u961F spring.rabbitmq.listener.simple.default-requeue-rejected= true 消费失败后是否重新入队 #\u542F\u7528\u53D1\u9001\u91CD\u8BD5 spring.rabbitmq.template.retry.enabled=true spring.rabbitmq.template.retry.initial-interval=1000 spring.rabbitmq.template.retry.max-attempts=3 spring.rabbitmq.template.retry.max-interval=10000 spring.rabbitmq.template.retry.multiplier=1.0
18.为什么使用消息队列啊?消息队列有什么优点和缺点啊?kafka、activemq、rabbitmq、rocketmq都有什么区别以及适合哪些场景?
1.为什么使用消息队列啊?
通用回答是:我们公司有个什么业务场景,这个业务场景有个什么技术挑战,如果不用MQ可能会很麻烦,但是你现在用了MQ之后带给了你很多的好处。
比较核心的有3个业务场景:解耦、异步、削峰
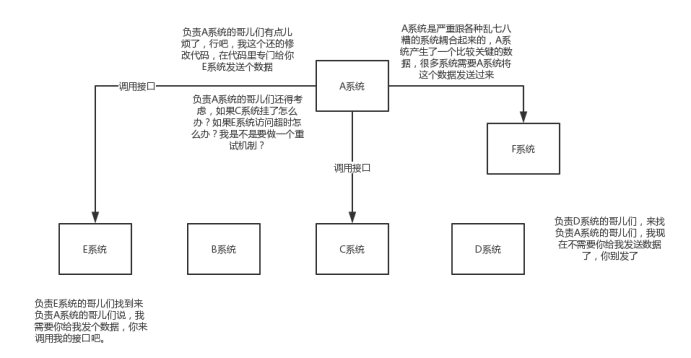
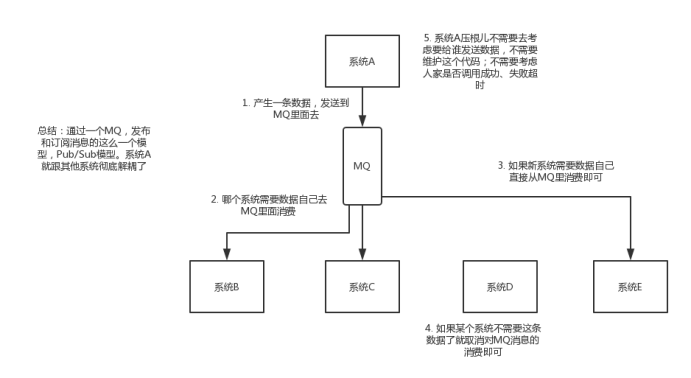
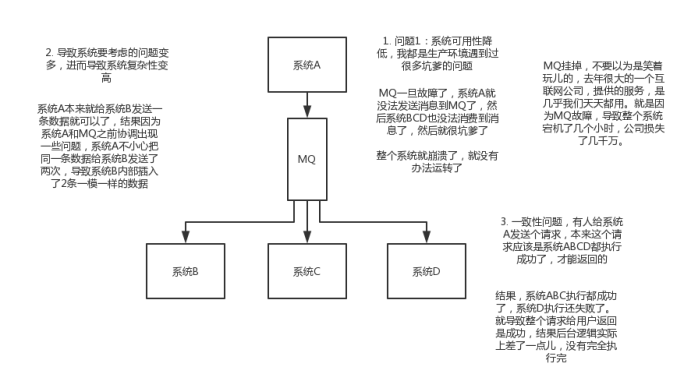
解耦:现场画个图来说明一下,A系统发送个数据到BCD三个系统,接口调用发送,那如果E系统也要这个数据呢?那如果C系统现在不需要了呢?现在A系统又要发送第二种数据了呢?A系统负责人濒临崩溃中。。。再来点更加崩溃的事儿,A系统要时时刻刻考虑BCDE四个系统如果挂了咋办?我要不要重发?我要不要把消息存起来?头发都白了啊。。。
不用MQ的系统耦合场景:
使用了MQ之后的解耦场景:
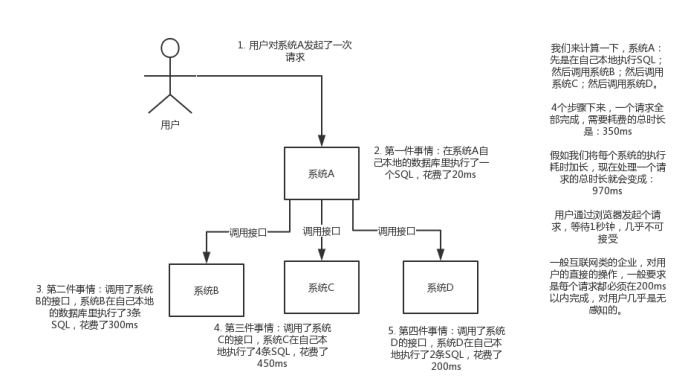
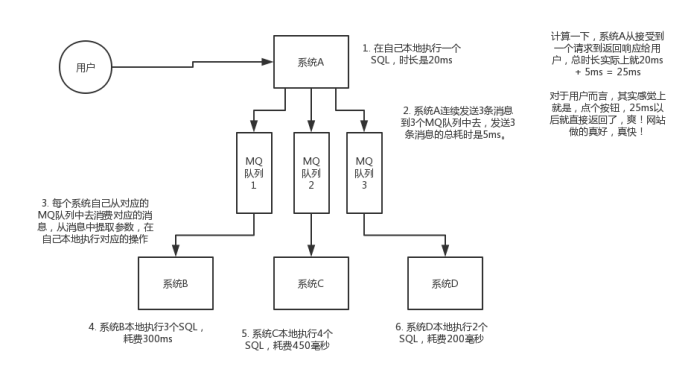
异步:现场画个图来说明一下,A系统接收一个请求,需要在自己本地写库,还需要在BCD三个系统写库,自己本地写库要3ms,BCD三个系统分别写库要300ms、450ms、200ms。最终请求总延时是3 + 300 + 450 + 200 = 953ms,接近1s,用户感觉搞个什么东西,慢死了慢死了。
不用MQ的同步高延时请求场景:
使用了MQ进行异步之后的接口性能优化:
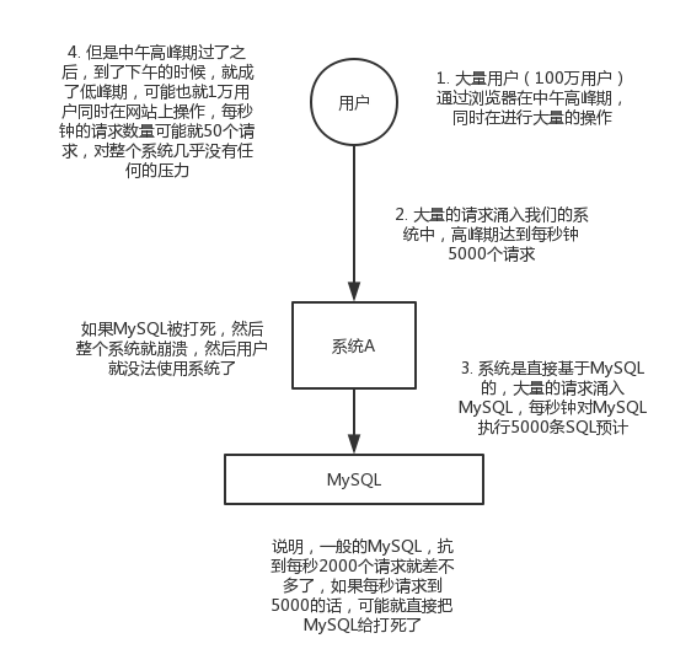
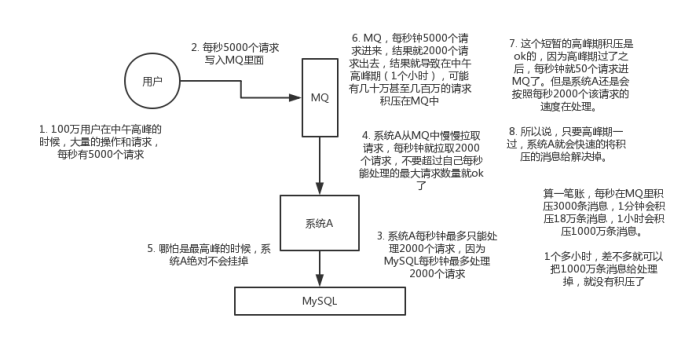
削峰:每天0点到11点,A系统风平浪静,每秒并发请求数量就100个。结果每次一到11点~1点,每秒并发请求数量突然会暴增到1万条。但是系统最大的处理能力就只能是每秒钟处理1000个请求啊。。。尴尬了,系统会死。。。
没用MQ高峰期系统被打死的场景:
使用MQ来进行削峰的场景:
(2)消息队列有什么优点和缺点啊?
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰
缺点呢?显而易见的
系统可用性降低:系统引入的外部依赖越多,越容易挂掉,本来你就是A系统调用BCD三个系统的接口就好了,本来ABCD四个系统好好的,没啥问题,你偏加个MQ进来,万一MQ挂了咋整?MQ挂了,整套系统崩溃了,你不就完了么。
系统复杂性提高:硬生生加个MQ进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已
一致性问题:A系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是BCD三个系统那里,BD两个系统写库成功了,结果C系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,最好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了10倍。但是关键时刻,用,还是得用的。。。
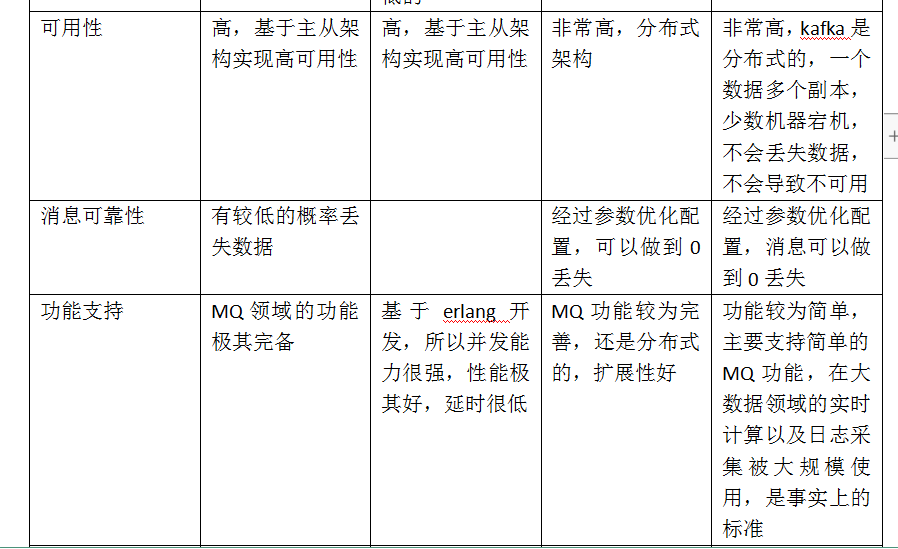
(3)kafka、activemq、rabbitmq、rocketmq都有什么优点和缺点啊?
优劣势总结:
ActiveMQ:
非常成熟,功能强大,在业内大量的公司以及项目中都有应用
偶尔会有较低概率丢失消息
而且现在社区以及国内应用都越来越少,官方社区现在对ActiveMQ 5.x维护越来越少,几个月才发布一个版本
而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用
RabbitMQ:
erlang语言开发,性能极其好,延时很低;
吞吐量到万级,MQ功能比较完备
而且开源提供的管理界面非常棒,用起来很好用
社区相对比较活跃,几乎每个月都发布几个版本分
在国内一些互联网公司近几年用rabbitmq也比较多一些
但是问题也是显而易见的,RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。
而且erlang开发,国内有几个公司有实力做erlang源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复bug。
而且rabbitmq集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是erlang语言本身带来的问题。很难读源码,很难定制和掌控。
RocketMQ:
接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障
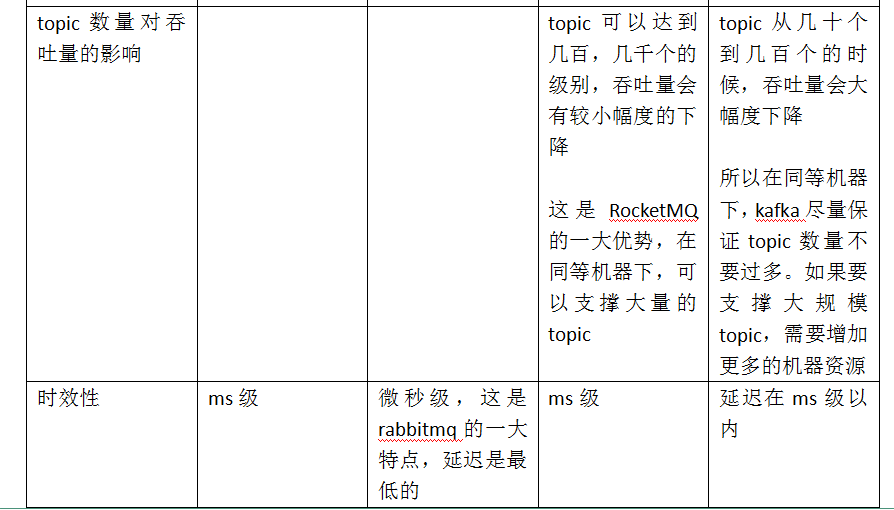
日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是ok的,还可以支撑大规模的topic数量,支持复杂MQ业务场景
而且一个很大的优势在于,阿里出品都是java系的,我们可以自己阅读源码,定制自己公司的MQ,可以掌控
社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准JMS规范走的有些系统要迁移需要修改大量代码
还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ挺好的
kafka:
kafka的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展
同时kafka最好是支撑较少的topic数量即可,保证其超高吞吐量
而且kafka唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略
这个特性天然适合大数据实时计算以及日志收集
综上所述,各种对比之后,我个人倾向于是:
一般的业务系统要引入MQ,最早大家都用ActiveMQ,但是现在确实大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,所以大家还是算了吧,我个人不推荐用这个了;
后来大家开始用RabbitMQ,但是确实erlang语言阻止了大量的java工程师去深入研究和掌控他,对公司而言,几乎处于不可控的状态,但是确实人是开源的,比较稳定的支持,活跃度也高;
不过现在确实越来越多的公司,会去用RocketMQ,确实很不错,但是我提醒一下自己想好社区万一突然黄掉的风险,对自己公司技术实力有绝对自信的,我推荐用RocketMQ,否则回去老老实实用RabbitMQ吧,人是活跃开源社区,绝对不会黄
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用RabbitMQ是不错的选择;大型公司,基础架构研发实力较强,用RocketMQ是很好的选择
如果是大数据领域的实时计算、日志采集等场景,用Kafka是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范
1、面试题
如何保证消息的可靠性传输(如何处理消息丢失的问题)?(基本也是必考的吧)
我们从下面几个方面来分析
1)生产者弄丢了数据
生产者将数据发送到rabbitmq的时候,可能数据就在半路给搞丢了,因为网络啥的问题,都有可能。
此时可以选择用rabbitmq提供的事务功能,就是生产者发送数据之前开启rabbitmq事务(channel.txSelect),然后发送消息,如果消息没有成功被rabbitmq接收到,那么生产者会收到异常报错,此时就可以回滚事务(channel.txRollback),然后重试发送消息;如果收到了消息,那么可以提交事务(channel.txCommit)。但是问题是,rabbitmq事务机制一搞,基本上吞吐量会下来,因为太耗性能。
所以一般来说,如果你要确保说写rabbitmq的消息别丢,可以开启confirm模式,在生产者那里设置开启confirm模式之后,你每次写的消息都会分配一个唯一的id,然后如果写入了rabbitmq中,rabbitmq会给你回传一个ack消息,告诉你说这个消息ok了。如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息id的状态,如果超过一定时间还没接收到这个消息的回调,那么你可以重发。
事务机制和cnofirm机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是confirm机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息rabbitmq接收了之后会异步回调你一个接口通知你这个消息接收到了。
所以一般在生产者这块避免数据丢失,都是用confirm机制的。
2)rabbitmq弄丢了数据
就是rabbitmq自己弄丢了数据,这个你必须开启rabbitmq的持久化,就是消息写入之后会持久化到磁盘,哪怕是rabbitmq自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,rabbitmq还没持久化,自己就挂了,可能导致少量数据会丢失的,但是这个概率较小。
设置持久化有两个步骤,第一个是创建queue的时候将其设置为持久化的,这样就可以保证rabbitmq持久化queue的元数据,但是不会持久化queue里的数据;第二个是发送消息的时候将消息的deliveryMode设置为2,就是将消息设置为持久化的,此时rabbitmq就会将消息持久化到磁盘上去。必须要同时设置这两个持久化才行,rabbitmq哪怕是挂了,再次重启,也会从磁盘上重启恢复queue,恢复这个queue里的数据。
而且持久化可以跟生产者那边的confirm机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者ack了,所以哪怕是在持久化到磁盘之前,rabbitmq挂了,数据丢了,生产者收不到ack,你也是可以自己重发的。
哪怕是你给rabbitmq开启了持久化机制,也有一种可能,就是这个消息写到了rabbitmq中,但是还没来得及持久化到磁盘上,结果不巧,此时rabbitmq挂了,就会导致内存里的一点点数据会丢失。
3)消费端弄丢了数据
rabbitmq如果丢失了数据,主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了,比如重启了,那么就尴尬了,rabbitmq认为你都消费了,这数据就丢了。
这个时候得用rabbitmq提供的ack机制,简单来说,就是你关闭rabbitmq自动ack,可以通过一个api来调用就行,然后每次你自己代码里确保处理完的时候,再程序里ack一把。这样的话,如果你还没处理完,不就没有ack?那rabbitmq就认为你还没处理完,这个时候rabbitmq会把这个消费分配给别的consumer去处理,消息是不会丢的。
(2)kafka
1)消费端弄丢了数据
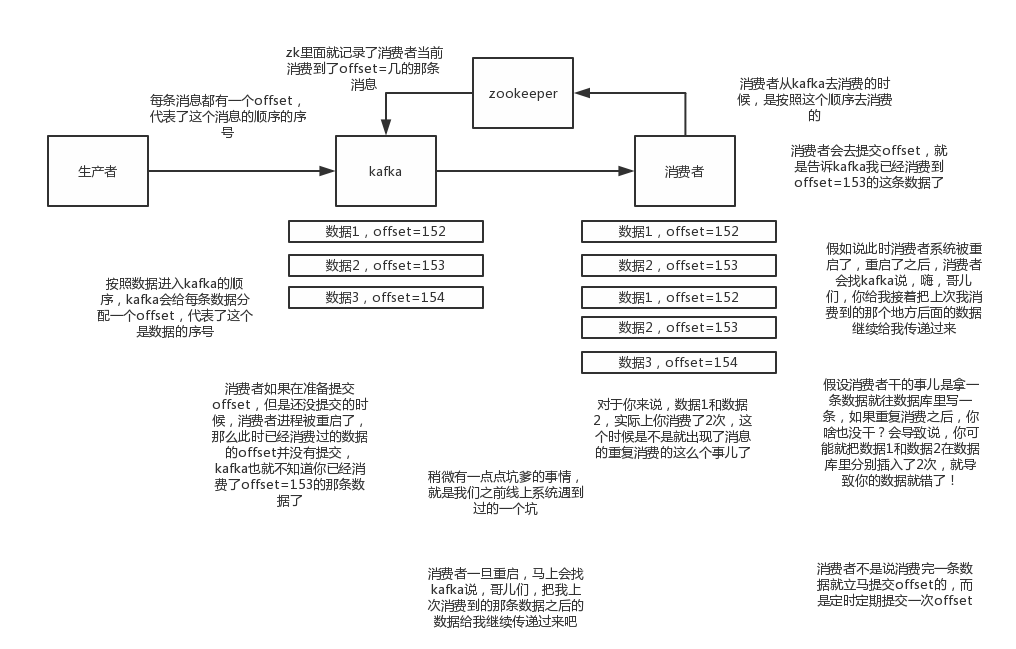
唯一可能导致消费者弄丢数据的情况,就是说,你那个消费到了这个消息,然后消费者那边自动提交了offset,让kafka以为你已经消费好了这个消息,其实你刚准备处理这个消息,你还没处理,你自己就挂了,此时这条消息就丢咯。
这不是一样么,大家都知道kafka会自动提交offset,那么只要关闭自动提交offset,在处理完之后自己手动提交offset,就可以保证数据不会丢。但是此时确实还是会重复消费,比如你刚处理完,还没提交offset,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
生产环境碰到的一个问题,就是说我们的kafka消费者消费到了数据之后是写到一个内存的queue里先缓冲一下,结果有的时候,你刚把消息写入内存queue,然后消费者会自动提交offset。
然后此时我们重启了系统,就会导致内存queue里还没来得及处理的数据就丢失了
2)kafka弄丢了数据
这块比较常见的一个场景,就是kafka某个broker宕机,然后重新选举partiton的leader时。大家想想,要是此时其他的follower刚好还有些数据没有同步,结果此时leader挂了,然后选举某个follower成leader之后,他不就少了一些数据?这就丢了一些数据啊。
生产环境也遇到过,我们也是,之前kafka的leader机器宕机了,将follower切换为leader之后,就会发现说这个数据就丢了
所以此时一般是要求起码设置如下4个参数:
给这个topic设置replication.factor参数:这个值必须大于1,要求每个partition必须有至少2个副本
在kafka服务端设置min.insync.replicas参数:这个值必须大于1,这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower吧
在producer端设置acks=all:这个是要求每条数据,必须是写入所有replica之后,才能认为是写成功了
在producer端设置retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了
我们生产环境就是按照上述要求配置的,这样配置之后,至少在kafka broker端就可以保证在leader所在broker发生故障,进行leader切换时,数据不会丢失
3)生产者会不会弄丢数据
如果按照上述的思路设置了ack=all,一定不会丢,要求是,你的leader接收到消息,所有的follower都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
问题: 如何保证消息队列的高可用啊?
RabbitMQ是比较有代表性的,因为是基于主从做高可用性的,我们就以他为例子讲解第一种MQ的高可用性怎么实现。
rabbitmq有三种模式:单机模式,普通集群模式,镜像集群模式
1)单机模式
就是demo级别的,一般就是你本地启动了玩玩儿的,没人生产用单机模式
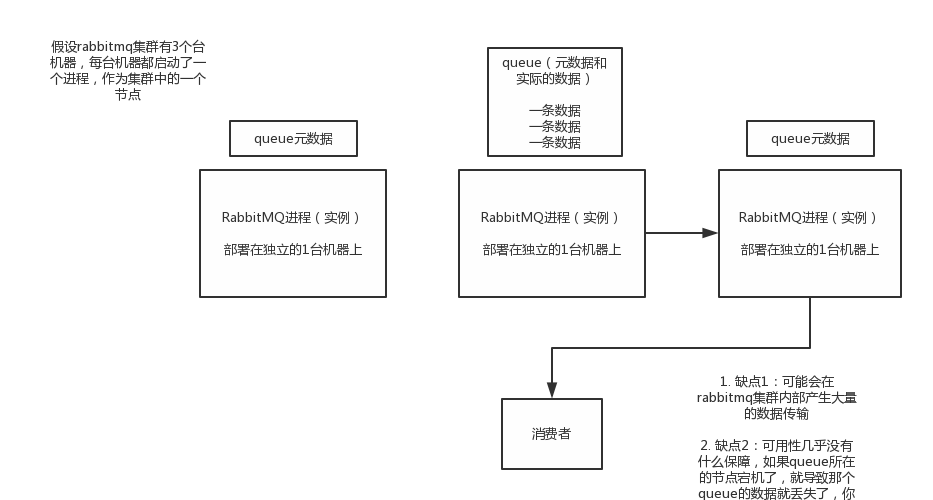
2)普通集群模式
意思就是在多台机器上启动多个rabbitmq实例,每个机器启动一个。但是你创建的queue,只会放在一个rabbtimq实例上,但是每个实例都同步queue的元数据。完了你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从queue所在实例上拉取数据过来。
这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个queue所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放queue的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让rabbitmq落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个queue拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性可言了,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个queue的读写操作。
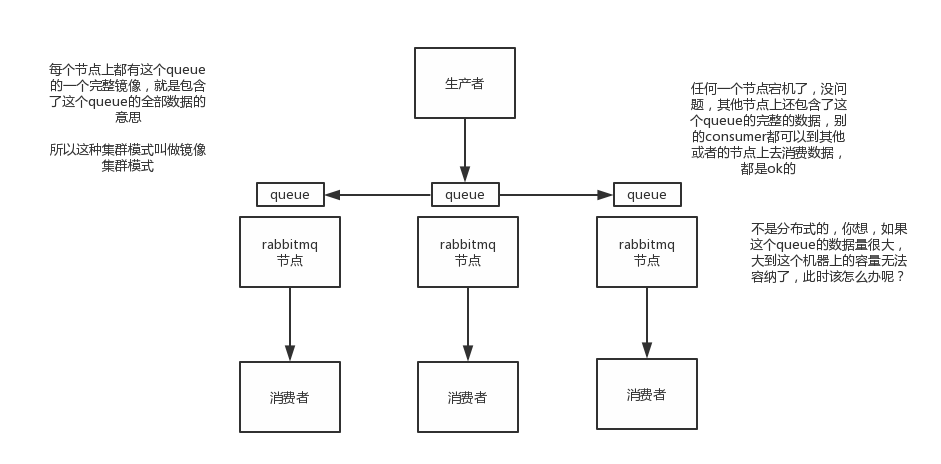
3)镜像集群模式
这种模式,才是所谓的rabbitmq的高可用模式,跟普通集群模式不一样的是,你创建的queue,无论元数据还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。
这样的话,好处在于,你任何一个机器宕机了,没事儿,别的机器都可以用。坏处在于,第一,这个性能开销也太大了吧,消息同步所有机器,导致网络带宽压力和消耗很重!第二,这么玩儿,就没有扩展性可言了,如果某个queue负载很重,你加机器,新增的机器也包含了这个queue的所有数据,并没有办法线性扩展你的queue
那么怎么开启这个镜像集群模式呢?我这里简单说一下,避免面试人家问你你不知道,其实很简单rabbitmq有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候可以要求数据同步到所有节点的,也可以要求就同步到指定数量的节点,然后你再次创建queue的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
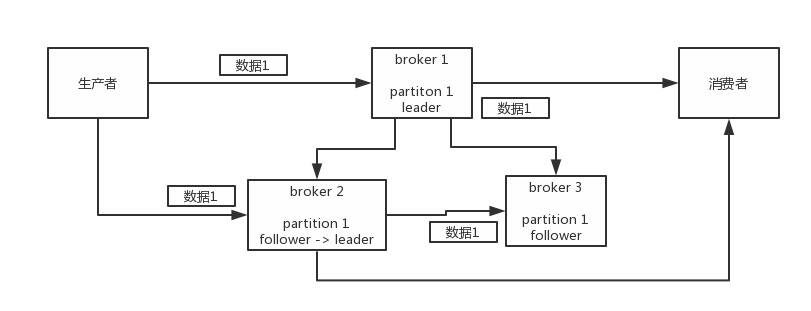
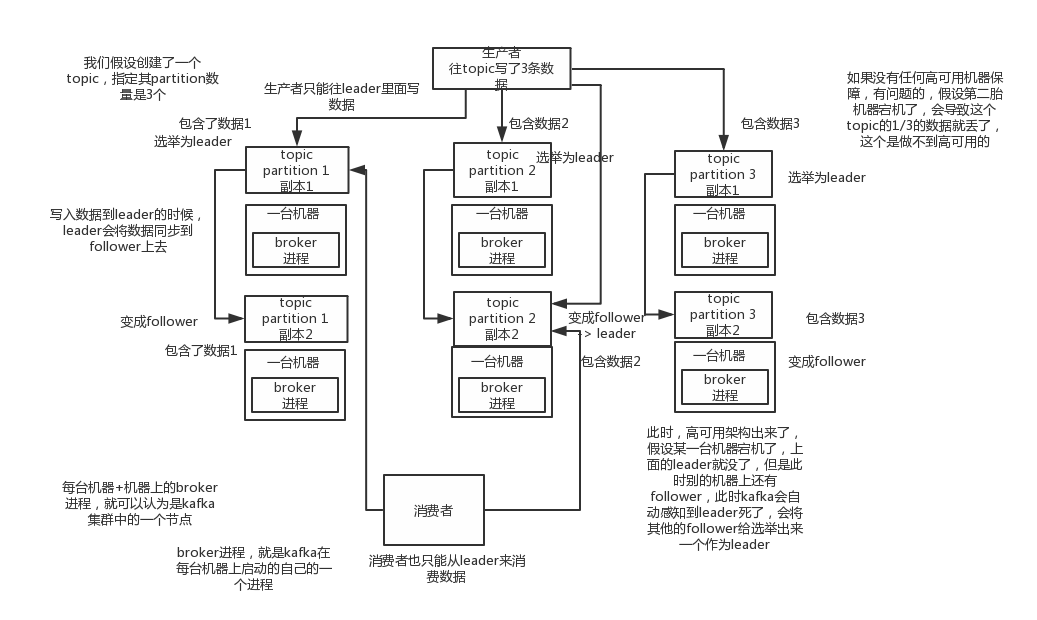
(2)kafka的高可用性
kafka一个最基本的架构认识:多个broker组成,每个broker是一个节点;你创建一个topic,这个topic可以划分为多个partition,每个partition可以存在于不同的broker上,每个partition就放一部分数据。
这就是天然的分布式消息队列,就是说一个topic的数据,是分散放在多个机器上的,每个机器就放一部分数据。
实际上rabbitmq之类的,并不是分布式消息队列,他就是传统的消息队列,只不过提供了一些集群、HA的机制而已,因为无论怎么玩儿,rabbitmq一个queue的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个queue的完整数据。
kafka 0.8以前,是没有HA机制的,就是任何一个broker宕机了,那个broker上的partition就废了,没法写也没法读,没有什么高可用性可言。
kafka 0.8以后,提供了HA机制,就是replica副本机制。每个partition的数据都会同步到吉他机器上,形成自己的多个replica副本。然后所有replica会选举一个leader出来,那么生产和消费都跟这个leader打交道,然后其他replica就是follower。写的时候,leader会负责把数据同步到所有follower上去,读的时候就直接读leader上数据即可。只能读写leader?很简单,要是你可以随意读写每个follower,那么就要care数据一致性的问题,系统复杂度太高,很容易出问题。kafka会均匀的将一个partition的所有replica分布在不同的机器上,这样才可以提高容错性。
这么搞,就有所谓的高可用性了,因为如果某个broker宕机了,没事儿,那个broker上面的partition在其他机器上都有副本的,如果这上面有某个partition的leader,那么此时会重新选举一个新的leader出来,大家继续读写那个新的leader即可。这就有所谓的高可用性了。
写数据的时候,生产者就写leader,然后leader将数据落地写本地磁盘,接着其他follower自己主动从leader来pull数据。一旦所有follower同步好数据了,就会发送ack给leader,leader收到所有follower的ack之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候,只会从leader去读,但是只有一个消息已经被所有follower都同步成功返回ack的时候,这个消息才会被消费者读到。
面试题
如何保证消息不被重复消费啊(如何保证消息消费时的幂等性)?
2、面试官心里分析
其实这个很常见的一个问题,这俩问题基本可以连起来问。既然是消费消息,那肯定要考虑考虑会不会重复消费?能不能避免重复消费?或者重复消费了也别造成系统异常可以吗?这个是MQ领域的基本问题,其实本质上还是问你使用消息队列如何保证幂等性,这个是你架构里要考虑的一个问题。
面试官问你,肯定是必问的,这是你要考虑的实际生产上的系统设计问题。
3、面试题剖析
回答这个问题,首先你别听到重复消息这个事儿,就一无所知吧,你先大概说一说可能会有哪些重复消费的问题。
首先就是比如rabbitmq、rocketmq、kafka,都有可能会出现消费重复消费的问题,正常。因为这问题通常不是mq自己保证的,是给你保证的。然后我们挑一个kafka来举个例子,说说怎么重复消费吧。
kafka实际上有个offset的概念,就是每个消息写进去,都有一个offset,代表他的序号,然后consumer消费了数据之后,每隔一段时间,会把自己消费过的消息的offset提交一下,代表我已经消费过了,下次我要是重启啥的,你就让我继续从上次消费到的offset来继续消费吧。
但是凡事总有意外,比如我们之前生产经常遇到的,就是你有时候重启系统,看你怎么重启了,如果碰到点着急的,直接kill进程了,再重启。这会导致consumer有些消息处理了,但是没来得及提交offset,尴尬了。重启之后,少数消息会再次消费一次。
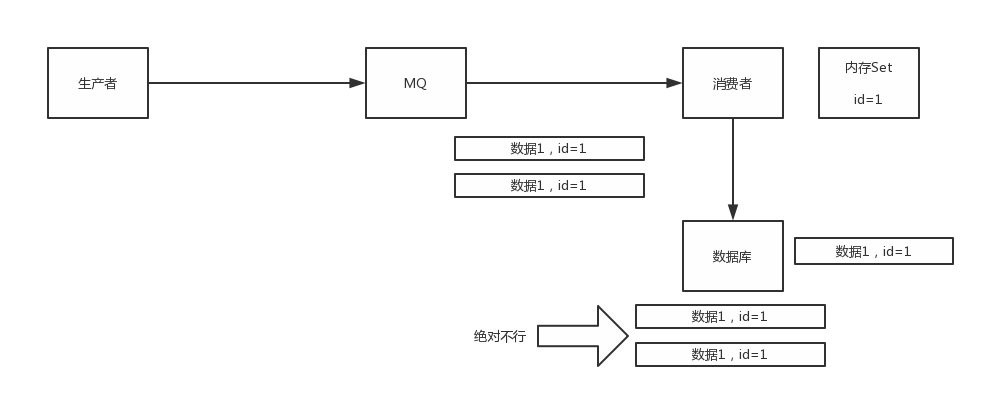
其实重复消费不可怕,可怕的是你没考虑到重复消费之后,怎么保证幂等性。
给你举个例子吧。假设你有个系统,消费一条往数据库里插入一条,要是你一个消息重复两次,你不就插入了两条,这数据不就错了?但是你要是消费到第二次的时候,自己判断一下已经消费过了,直接扔了,不就保留了一条数据?
一条数据重复出现两次,数据库里就只有一条数据,这就保证了系统的幂等性
幂等性,我通俗点说,就一个数据,或者一个请求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错。
那所以第二个问题来了,怎么保证消息队列消费的幂等性?
其实还是得结合业务来思考,我这里给几个思路:
(1)比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update一下好吧
(2)比如你是写redis,那没问题了,反正每次都是set,天然幂等性
(3)比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单id之类的东西,然后你这里消费到了之后,先根据这个id去比如redis里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个id写redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
还有比如基于数据库的唯一键来保证重复数据不会重复插入多条,我们之前线上系统就有这个问题,就是拿到数据的时候,每次重启可能会有重复,因为kafka消费者还没来得及提交offset,重复数据拿到了以后我们插入的时候,因为有唯一键约束了,所以重复数据只会插入报错,不会导致数据库中出现脏数据
如何保证MQ的消费是幂等性的,需要结合具体的业务来看
如何保证消息的顺序性?
2、面试官心里分析
其实这个也是用MQ的时候必问的话题,第一看看你了解不了解顺序这个事儿?第二看看你有没有办法保证消息是有顺序的?这个生产系统中常见的问题。
3、面试题剖析
我举个例子,我们以前做过一个mysql binlog同步的系统,压力还是非常大的,日同步数据要达到上亿。mysql -> mysql,常见的一点在于说大数据team,就需要同步一个mysql库过来,对公司的业务系统的数据做各种复杂的操作。
你在mysql里增删改一条数据,对应出来了增删改3条binlog,接着这三条binlog发送到MQ里面,到消费出来依次执行,起码得保证人家是按照顺序来的吧?不然本来是:增加、修改、删除;你楞是换了顺序给执行成删除、修改、增加,不全错了么。
本来这个数据同步过来,应该最后这个数据被删除了;结果你搞错了这个顺序,最后这个数据保留下来了,数据同步就出错了。
先看看顺序会错乱的俩场景
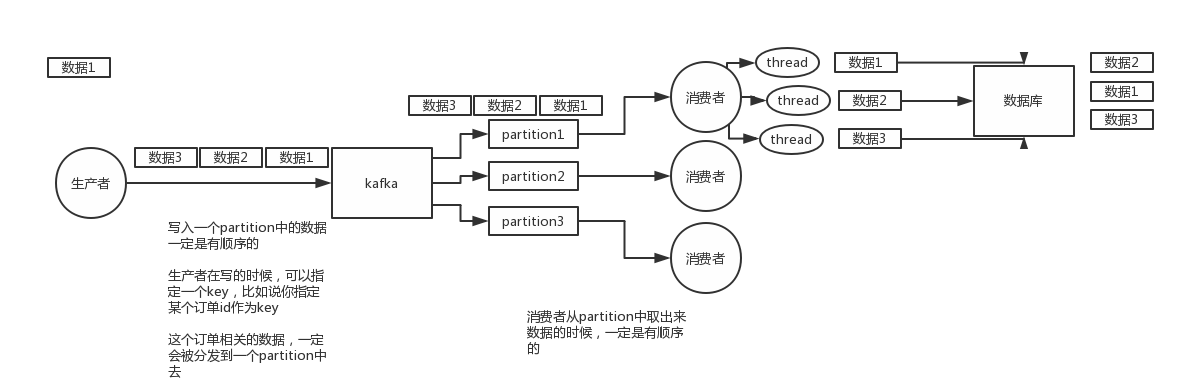
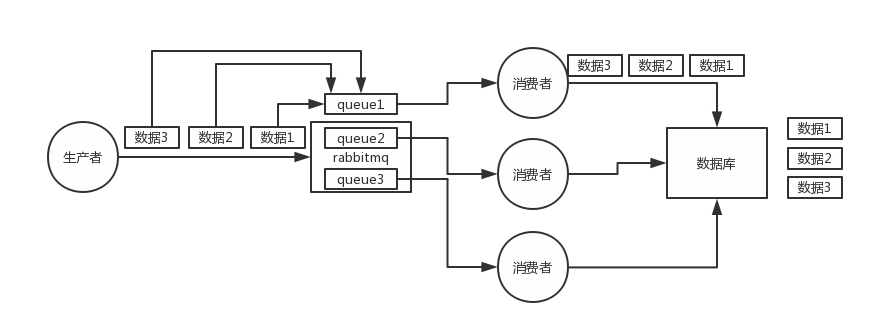
(1)rabbitmq:一个queue,多个consumer,这不明显乱了
(2)kafka:一个topic,一个partition,一个consumer,内部多线程,这不也明显乱了
那如何保证消息的顺序性呢?简单简单
(1)rabbitmq:拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理
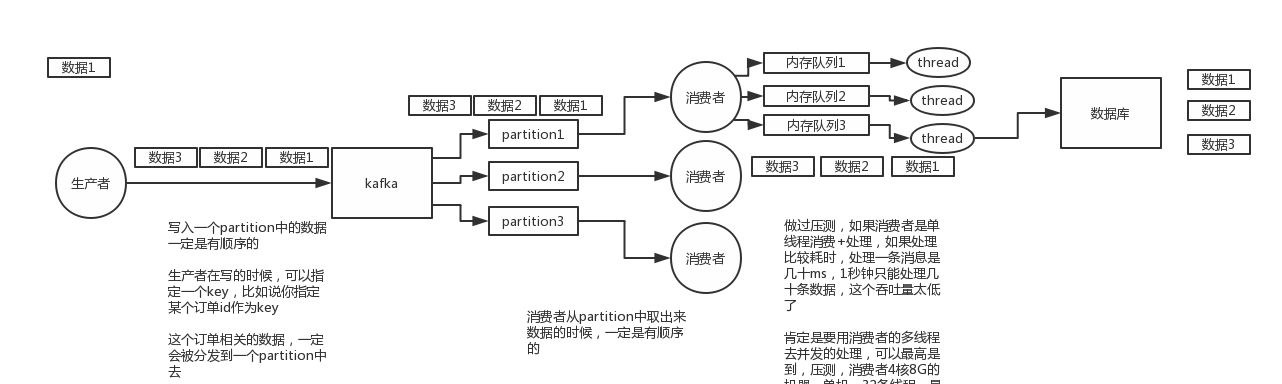
(2)kafka:一个topic,一个partition,一个consumer,内部单线程消费,写N个内存queue,然后N个线程分别消费一个内存queue即可
如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
2、面试官心里分析
你看这问法,其实本质针对的场景,都是说,可能你的消费端出了问题,不消费了,或者消费的极其极其慢。接着就坑爹了,可能你的消息队列集群的磁盘都快写满了,都没人消费,这个时候怎么办?或者是整个这就积压了几个小时,你这个时候怎么办?或者是你积压的时间太长了,导致比如rabbitmq设置了消息过期时间后就没了怎么办?
所以就这事儿,其实线上挺常见的,一般不出,一出就是大case,一般常见于,举个例子,消费端每次消费之后要写mysql,结果mysql挂了,消费端hang那儿了,不动了。或者是消费端出了个什么叉子,导致消费速度极其慢。
3、面试题分析
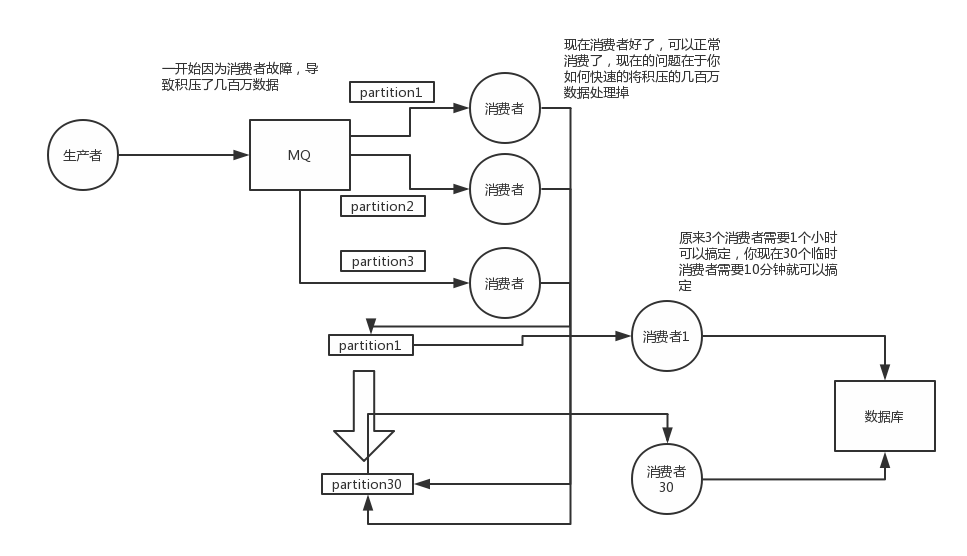
关于这个事儿,我们一个一个来梳理吧,先假设一个场景,我们现在消费端出故障了,然后大量消息在mq里积压,现在事故了,慌了
(1)大量消息在mq里积压了几个小时了还没解决
几千万条数据在MQ里积压了七八个小时,从下午4点多,积压到了晚上很晚,10点多,11点多
这个是我们真实遇到过的一个场景,确实是线上故障了,这个时候要不然就是修复consumer的问题,让他恢复消费速度,然后傻傻的等待几个小时消费完毕。这个肯定不能在面试的时候说吧。
一个消费者一秒是1000条,一秒3个消费者是3000条,一分钟是18万条,1000多万条
所以如果你积压了几百万到上千万的数据,即使消费者恢复了,也需要大概1小时的时间才能恢复过来
一般这个时候,只能操作临时紧急扩容了,具体操作步骤和思路如下:
1)先修复consumer的问题,确保其恢复消费速度,然后将现有cnosumer都停掉
2)新建一个topic,partition是原来的10倍,临时建立好原先10倍或者20倍的queue数量
3)然后写一个临时的分发数据的consumer程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的10倍数量的queue
4)接着临时征用10倍的机器来部署consumer,每一批consumer消费一个临时queue的数据
5)这种做法相当于是临时将queue资源和consumer资源扩大10倍,以正常的10倍速度来消费数据
6)等快速消费完积压数据之后,得恢复原先部署架构,重新用原先的consumer机器来消费消息
(2)这里我们假设再来第二个坑
假设你用的是rabbitmq,rabbitmq是可以设置过期时间的,就是TTL,如果消息在queue中积压超过一定的时间就会被rabbitmq给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在mq里,而是大量的数据会直接搞丢。
这个情况下,就不是说要增加consumer消费积压的消息,因为实际上没啥积压,而是丢了大量的消息。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上12点以后,用户都睡觉了。
这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入mq里面去,把白天丢的数据给他补回来。也只能是这样了。
假设1万个订单积压在mq里面,没有处理,其中1000个订单都丢了,你只能手动写程序把那1000个订单给查出来,手动发到mq里去再补一次
(3)然后我们再来假设第三个坑
如果走的方式是消息积压在mq里,那么如果你很长时间都没处理掉,此时导致mq都快写满了,咋办?这个还有别的办法吗?没有,谁让你第一个方案执行的太慢了,你临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后走第二个方案,到了晚上再补数据吧。
如果让你写一个消息队列,该如何进行架构设计啊?说一下你的思路
2、面试官心里分析
其实聊到这个问题,一般面试官要考察两块:
(1)你有没有对某一个消息队列做过较为深入的原理的了解,或者从整体了解把握住一个mq的架构原理
(2)看看你的设计能力,给你一个常见的系统,就是消息队列系统,看看你能不能从全局把握一下整体架构设计,给出一些关键点出来
说实话,我一般面类似问题的时候,大部分人基本都会蒙,因为平时从来没有思考过类似的问题,大多数人就是平时埋头用,从来不去思考背后的一些东西。类似的问题,我经常问的还有,如果让你来设计一个spring框架你会怎么做?如果让你来设计一个dubbo框架你会怎么做?如果让你来设计一个mybatis框架你会怎么做?
3、面试题剖析
其实回答这类问题,说白了,起码不求你看过那技术的源码,起码你大概知道那个技术的基本原理,核心组成部分,基本架构构成,然后参照一些开源的技术把一个系统设计出来的思路说一下就好
比如说这个消息队列系统,我们来从以下几个角度来考虑一下
(1)首先这个mq得支持可伸缩性吧,就是需要的时候快速扩容,就可以增加吞吐量和容量,那怎么搞?设计个分布式的系统呗,参照一下kafka的设计理念,broker -> topic -> partition,每个partition放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给topic增加partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了?
(2)其次你得考虑一下这个mq的数据要不要落地磁盘吧?那肯定要了,落磁盘,才能保证别进程挂了数据就丢了。那落磁盘的时候怎么落啊?顺序写,这样就没有磁盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是kafka的思路。
(3)其次你考虑一下你的mq的可用性啊?这个事儿,具体参考我们之前可用性那个环节讲解的kafka的高可用保障机制。多副本 -> leader & follower -> broker挂了重新选举leader即可对外服务。
(4)能不能支持数据0丢失啊?可以的,参考我们之前说的那个kafka数据零丢失方案
其实一个mq肯定是很复杂的,面试官问你这个问题,其实是个开放题,他就是看看你有没有从架构角度整体构思和设计的思维以及能力。确实这个问题可以刷掉一大批人,因为大部分人平时不思考这些东西。
消息什么情况下会丢失?配合mandatory参数或备份交换器来提高程序的健壮性
发送消息的交换器并没有绑定任何队列,消息将会丢失
交换器绑定了某个队列,但是发送消息时的路由键无法与现存的队列匹配
预估队列的使用情况?
在后期运行过程中超过预定的阈值,可以根据实际情况对当前集群进行扩容或者将相应的队列迁移到其他集群。
消费消息?
推模式,拉模式
保证消息的可靠性?
RabbitMQ 提供了消息确认机制( message acknowledgement)。 消费者在订阅队列时,可以指定 autoAck 参数,当 autoAck 等于 false 时, RabbitMQ 会等待消费者显式地回复确认信号后才从内存(或者磁盘)中移去消息(实质上
是先打上删除标记,之后再删除)。当 autoAck 等于 true 时, RabbitMQ 会自动把发送出去的 消息置为确认,然后从内存(或者磁盘)中删除,而不管消费者是否真正地消费到了这些消息。
在ack为false的情况下,消费者获取消息迟迟没有发送消费者确认消息的信号或者消费者断开,怎么办?
当 autoAck 参数置为 false,对于 RabbitMQ 服务端而言,队列中的消息分成了两个部分: 一部分是等待投递给消费者的消息:一部分是己经投递给消费者,但是还没有收到消费者确认信号的消息。 如果 RabbitMQ 一直没有收到消费者的确认信号,并且消费此消息的消费者己经 断开连接,则 RabbitMQ 会安排该消息重新进入队列,等待投递给下一个消费者,当然也有可 能还是原来的那个消费者。RabbitMQ 不会为未确认的消息设置过期时间,它判断此消息是否需要重新投递给消费者的唯一依据是消费该消息的消费者连接是否己经断开,这么设计的原因是 RabbitMQ 允许消费者 消费一条消息的时间可以很久很久。
在消费者接收到消息后,如果想明确拒绝当前的消息而不是确认,那么应该怎么做呢?
RabbitMQ 在 2.0.0 版本开始引入了 Basic .Reject 这个命令,消费者客户端可以调用与其对 应的 channel.basicReject 方法来告诉 RabbitMQ 拒绝这个消息。
//Channel 类中的 basicReject 方法定义如下:
//其中 deliveryTag 可以看作消息的编号 ,它是一个 64 位的长整型值,最大值是 9223372036854775807。如果 //requeue 参数设置为 true,则 RabbitMQ 会重新将这条消息存入 队列,以便可以发送给下一个订阅的消费者;如果 //requeue 参数设置为 false,则 RabbitMQ 立即会把消息从队列中移除,而不会把它发送给新的消费者。
void basicReject(long deliveryTag, boolean requeue) throws IOException
注意:Basic.Reject 命令一次只能拒绝一条消息 ,如果想要批量拒绝消息 ,则可以使用 Basic.Nack 这个命令
//消费者客户端可以调用 channel.basicNack 方法来实现,方法定 义如下:
//其中 deliveryTag 和 requeue 的含义可以参考 basicReject 方法。 multiple 参数
//设置为 false 则表示拒绝编号为 deliveryT坷的这一条消息,这时候 basicNack 和 basicReject 方法一样; //multiple 参数设置为 true 则表示拒绝 deliveryTag 编号之前所 有未被当前消费者确认的消息。
void basicNack(long deliveryTag, boolean multiple, boolean requeue) throws IOException
注意:
将 channel.basicReject 或者 channel.basicNack 中的 requeue 设直为 false,可以启用”死信队列”的功能。死信队列可以通过检测被拒绝或者未送达的消息来追踪问题
请求RabbitMQ重新发送还未被确认的消息?
//Basic.Recover 具备可重入队列的特性
Basic.RecoverOk basicRecover() throws IOException;
Basic.RecoverOk basicRecover(boolean requeue) throws IOException;
channel.basicRecover 方法用来请求 RabbitMQ 重新发送还未被确认的消息。 如果 requeue 参数设置为 true,则未被确认的消息会被重新加入到队列中,这样对于同一条消息 来说,可能会被分配给与之前不同的消费者。如果 requeue 参数设置为 false,那么同一条消 息会被分配给与之前相同的消费者。默认情况下,如果不设置 requeue 这个参数,相当于
channel.basicRecover(true) ,即 requeue 默认为 true
交换器无法根据自身的类型和路由键找到一个符合条件 的队列
当 mandatory 参数设为 true 时,交换器无法根据自身的类型和路由键找到一个符合条件 的队列,那么 RabbitMQ 会调用 Basic.Return 命令将消息返回给生产者。当 mandatory 参 数设置为 false 时,出现上述情形,则消息直接被丢弃
生产者如何获取到没有被正确路由到合适队列的消息呢?
可以通过调用channel.addReturnListener来添加ReturnListener监听器实现。RabbitMQ 会通过 Basic . Return 返回 “mandatory test” 这条消息,之后生产者客户端通过 ReturnListener 监昕到了这个事 件,上面代码的最后输出应该是”Basic.Retum 返回的结果是: mandatory test”
mandatory和immediate参数的区别
mandatory 参数告诉服务器至少将该消息路由到一个队列中, 否则将消息返 回给生产者。 immediate 参数告诉服务器, 如果该消息关联的队列上有消费者, 则立刻投递: 如果所有匹配的队列上都没有消费者,则直接将消息返还给生产者, 不用将消息存入队列而等 待消费者了。
未被路由到的消息应该怎么处理?
发送消息的时候设置mandatory参数,添加ReturnListener监听器接收未被路由到的返回消息
采用备份交换器AE,可以将未被路由的消息存储在RabbitMQ中,通过声明交换器的时候添加AE参数实现,或者通过策略的方式实现,同时使用,前者优先级高,会覆盖掉Policy的设置
备份交换器需要注意?
如果设置的备份交换器不存在,客户端和RabbitMQ服务端都不会有异常出现,此时消息会丢失
如果备份交换器没有绑定任何队列,客户端和RabbitMQ服务端都不会有异常出现,此时消息会丢失
如果备份交换器没有任何匹配的队列,客户端和RabbitMQ服务端都不会有异常出现,此时消息会丢失
如果备份交换器和mandatory参数一起使用,那么mandatory参数无效
怎么为消息设置过期时间TTL?
通过队列属性设置,队列中所有消息都有相同的过期时间,声明队列的时候在channel.queueDeclare加入TTL参数
对消息本身进行单独设置,每条消息的TTL可以不同,在channel.basicPublish方法参数中设置
同时使用以上两种方式设置过期时间,以较小的为准
消息在队列中的生存时间一旦超过设置的TTL值,就变成死信,消费者无法再收到该消息(不是绝对的)
如果不设置 TTL.则表示此消息不会过期;如果将 TTL 设置为 0,则表示除非此时可以直接将消息投递到消费者,否则该消息会被立即丢弃,这个特性可以部分替代 RabbitMQ 3.0 版本之前的 immediate 参数
对过期消息处理?
设置队列 TTL 属性的方法,一旦消息过期,就会从队列中抹去,队列中己过期的消息肯定在队 列头部, RabbitMQ 只要定期从队头开始扫描是否有过期的消息即可,
消息本身进行单独设置,即使消息过期,也不会马上从队列中抹去,因为每条消息是否过期是在即将投递到消费者之前判定的。每条消息的过期时间不同,如果要删除所有过期消息势必要扫描整个队列,所以不如等到此消息即将 被消费时再判定是否过期, 如果过期再进行删除即可。
怎么设置队列的过期时间?
通过 channel . queueDeclare 方法中的 x-expires 参数可以控制队列被自动删除前处 于未使用状态的时间。未使用的意思是队列上没有任何的消费者,队列也没有被重新声明,并且在过期时间段内也未调用过 Basic . Get 命令。
RabbitMQ 会确保在过期时间到达后将队列删除,但是不保障删除的动作有多及时 。在 RabbitMQ 重启后,持久化的队列的过期时间会被重新计算。
什么是死信队列?
DLX,全称为 Dead-Letter-Exchange,可以称之为死信交换器,也有人称之为死信邮箱。当消息在一个队列中变成死信 (dead message) 之后,它能被重新被发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。
DLX 也是一个正常的交换器,和一般的交换器没有区别,它能在任何的队列上被指定, 实 际上就是设置某个队列的属性。当这个队列中存在死信时 , RabbitMQ 就会自动地将这个消息重新发布到设置的 DLX 上去,进而被路由到另一个队列,即死信队列。
什么是延迟队列?
? 延迟队列存储的对象是对应的延迟消息,所谓“延迟消息”是指当消息被发送后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费
延迟队列应用场景?
订单系统,用延迟队列处理超时订单
用户希望通过手机远程遥控家里的智能设备在指定的时间进行工作。这时候就可以将 用户指令发送到延迟队列,当指令设定的时间到了再将指令推送到智能设备。
持久化?
交换器的持久化
交换器的持久化是通过在声明交换器时将 durable 参数置为 true 实现的,如果交换器不设置持久化,那么在 RabbitMQ 服务重启之后,相关的交换器元数据会丢失, 不过消息不会丢失,只是不能将消息发送到这个交换器中了。对一个长期使用的交换器来说,建议将其置为持久化的。
队列的持久化
队列的持久化是通过在声明队列时将 durable 参数置为 true 实现的,如果队列不设置持久化,那么在 RabbitMQ 服务重启之后,相关队列的元数据会丢失,此时数据也会丢失。
消息的持久化
通过将消息的投递模式 (BasicProperties 中的 deliveryMode 属性)设置为 2 即可实现消息的持久化。
在这段时间内 RabbitMQ 服务节点发生了岩机、重启等异常情况,消息保存还没来得及落盘,那么这些消息将RabbitMQ 实战指南会丢失。这个问题怎么解决呢?
? 可以引入 RabbitMQ 的镜像队列机制,相当于配置了副本,如果主节点 Cmaster) 在此特殊时间内挂掉,可以自动切换到从节点 Cslave ), 这样有效地保证了高可用性
当消息的生产者将消息发送出去之后,消息到底有没有正确地到达服务器呢?
通过事务机制实现,比较消耗性能
客户端发送 Tx.Select. 将信道置为事务模式;
Broker 回复 Tx. Select-Ok. 确认己将信道置为事务模式:
在发送完消息之后,客户端发送 Tx.Commit 提交事务;
Broker 回复 Tx. Commi t-Ok. 确认事务提交。
通过发送方确认机制实现
消费端对消息的处理?
过推模式或者拉模式的方 式来获取井消费消息,当消费者处理完业务逻辑需要手动确认消息己被接收,这RabbitMQ才能把当前消息从队列中标记清除
如果消费者由于某些原因无法处理当前接收到的消息, 可以通过 channel . basicNack 或者 channel . basicReject 来拒绝掉。
消费端存在的问题?
消息分发
同一个队列拥有多个消费者,会采用轮询的方式分发消息给消费者,若其中有的消费者任务重,有的消费者很快处理完消息,导致进程空闲,这样对导致整体应用吞吐量下降,为了解决上面的问题,用到channel.basicQos 方法允许限制信道上的消费者所能保持的最大未确认消息的数量。Basic.Qos 的使用对于拉模式的消费方式无效.
举例如下:
在订阅消费队列之前,消费端程序调用了 channel.basicQos(5) ,之后订 阅了某个队列进行消费。 RabbitMQ 会保存一个消费者的列表,每发送一条消息都会为对应的消费者计数,如果达到了所设定的上限,那么 RabbitMQ 就不会向这个消费者再发送任何消息。 直到消费者确认了某条消息之后 , RabbitMQ将相应的计数减1,之后消费者可以继续接收消息, 直到再次到达计数上限。这种机制可以类比于 TCP!IP中的”滑动窗口”。
消息顺序性
生产者使用了事务机制可能会破坏消息顺序性
生产者发送消息设置了不同的超时时间,并且设置了死信队列
消息设置了优先级
可以考虑在消息体内添加全局有序标识来实现
弃用QueueingConsumer,Spring提供的RabbitMQ采用的是DefaultConsume
内存溢出,由于某些原因,队列之中堆积了比较多的消息,可能导致消费者客户端内存溢出假死,发生恶性循环,使用 Basic . Qos 来解决,一定要在调用 Basic . Consume 之前调用 Basic.Qos
才能生效。
会拖累同一个connection下的所有信道,使其性能降低
同步递归调用QueueingConsumer会产生死锁
RabbitMQ的自动连接恢复机制不支持QueueingConsumer这种形式
QueueingConsumer不是事件驱动的
消息传输保障?
一般消息中间件的消息传输保障分为三个等级
At most once: 最多一次。消息可能会丢失,但绝不会重复传输。
At least once: 最少一次。消息绝不会丢失,但可能会重复传输。
Exactly once: 恰好一次。每条消息肯定会被传输一次且仅传输一次。
RabbitMQ支持其中的“最多一次”和“最少一次”。
其中”最少一次”投递实现需要考虑 以下这个几个方面的内容:
消息生产者需要开启事务机制或者 publisher confirm 机制,以确保消息可以可靠地传 输到 RabbitMQ 中。
消息生产者需要配合使用 mandatory 参数或者备份交换器来确保消息能够从交换器 路由到队列中,进而能够保存下来而不会被丢弃。
消息和队列都需要进行持久化处理,以确保 RabbitMQ 服务器在遇到异常情况时不会造成消息丢失。
消费者在消费消息的同时需要将 autoAck 设置为 false,然后通过手动确认的方式去 确认己经正确消费的消息,以避免在消费端引起不必要的消息丢失。
“最多一次”的方式就无须考虑以上那些方面,生产者随意发送,消费者随意消费,不过这 样很难确保消息不会丢失。
提高数据可靠性途径?
设置 mandatory 参数或者备份交换器 (immediate 参数己被陶汰);
设置 publisher conflITll机制或者事务;
设置交换器、队列和消息都为持久化;
设置消费端对应的 autoAck 参数为 false 井在消费完消息之后再进行消息确认
rabbit面试题
1.什么是rabbitmq
采用AMQP高级消息队列协议的一种消息队列技术,最大的特点就是消费并不需要确保提供方存在,实现了服务之间的高度解耦
2.为什么要使用rabbitmq
1.在分布式系统下具备异步,削峰,负载均衡等一系列高级功能;
2.拥有持久化的机制,进程消息,队列中的信息也可以保存下来。
3.实现消费者和生产者之间的解耦。
4.对于高并发场景下,利用消息队列可以使得同步访问变为串行访问达到一定量的限流,利于数据库的操作。
5.可以使用消息队列达到异步下单的效果,排队中,后台进行逻辑下单。
3.使用rabbitmq的场景
1.服务间异步通信
2.顺序消费
3.定时任务
4.请求削峰
4.如何确保消息正确地发送至RabbitMQ? 如何确保消息接收方消费了消息?
发送方确认模式:
将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的ID。
一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。
如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack(not acknowledged,未确认)消息。
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
接收方确认机制
接收方消息确认机制:消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。
这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。保证数据的最终一致性;
下面罗列几种特殊情况:
如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ会认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消息重复消费的隐患,需要去重)
如果消费者接收到消息却没有确认消息,连接也未断开,则RabbitMQ认为该消费者繁忙,将不会给该消费者分发更多的消息。
5.如何避免消息重复投递或重复消费?
在消息生产时,MQ内部针对每条生产者发送的消息生成一个inner-msg-id,作为去重的依据(消息投递失败并重传),避免重复的消息进入队列;
在消息消费时,要求消息体中必须要有一个bizId(对于同一业务全局唯一,如支付ID、订单ID、帖子ID等)作为去重的依据,避免同一条消息被重复消费。
6.消息基于什么传输?
由于TCP连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ使用信道的方式来传输数据。信道是建立在真实的TCP连接内的虚拟连接,且每条TCP连接上的信道数量没有限制。
7.消息如何分发?
若该队列至少有一个消费者订阅,消息将以循环(round-robin)的方式发送给消费者。每条消息只会分发给一个订阅的消费者(前提是消费者能够正常处理消息并进行确认)。
通过路由可实现多消费的功能
8.消息怎么路由?
消息提供方->路由->一至多个队列
消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。
通过队列路由键,可以把队列绑定到交换器上。
消息到达交换器后,RabbitMQ会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则);
常用的交换器主要分为一下三种:
fanout:如果交换器收到消息,将会广播到所有绑定的队列上
direct:如果路由键完全匹配,消息就被投递到相应的队列
topic:可以使来自不同源头的消息能够到达同一个队列。 使用topic交换器时,可以使用通配符
9.如何确保消息不丢失?
消息持久化,当然前提是队列必须持久化
RabbitMQ确保持久性消息能从服务器重启中恢复的方式是,将它们写入磁盘上的一个持久化日志文件,当发布一条持久性消息到持久交换器上时,Rabbit会在消息提交到日志文件后才发送响应。
一旦消费者从持久队列中消费了一条持久化消息,RabbitMQ会在持久化日志中把这条消息标记为等待垃圾收集。如果持久化消息在被消费之前RabbitMQ重启,那么Rabbit会自动重建交换器和队列(以及绑定),并重新发布持久化日志文件中的消息到合适的队列。
10.使用RabbitMQ有什么好处?
服务间高度解耦,
异步通信性能高,
流量削峰
…
11.rabbitmq的集群
镜像集群模式
你创建的queue,无论元数据还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。
好处在于,你任何一个机器宕机了,没事儿,别的机器都可以用。坏处在于,第一,这个性能开销也太大了吧,消息同步所有机器,导致网络带宽压力和消耗很重!第二,这么玩儿,就没有扩展性可言了,如果某个queue负载很重,你加机器,新增的机器也包含了这个queue的所有数据,并没有办法线性扩展你的queue
12.mq的缺点
系统可用性降低
系统引入的外部依赖越多,越容易挂掉,本来你就是A系统调用BCD三个系统的接口就好了,人ABCD四个系统好好的,没啥问题,你偏加个MQ进来,万一MQ挂了咋整?MQ挂了,整套系统崩溃了,你不就完了么。
系统复杂性提高:
硬生生加个MQ进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已
一致性问题:
A系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是BCD三个系统那里,BD两个系统写库成功了,结果C系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,最好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了10倍。但是关键时刻,用,还是得用的。。。
RabbitMQ 在上一家公司已经接触过了, 但是懵懵懂懂的. 不是很清楚. 具体怎么个逻辑.
这次公司打算搭建新的系统. 领导要求研究一下MQ.
经过研究得出的结论是. MSMQ的设计理念不适合做系统的底层框架. 他不适合做分布式系统. 最主要的是. MSMQ如果没有消费者, 默认消息是一直存在的.
而RabbitMQ的设计理念是.只要有接收消息的队列. 邮件就会存放到队列里. 直到订阅人取走. . 如果没有可以接收这个消息的消息队列. 默认是抛弃这个消息的..
下面就把我的研究结果写一下.
如何在新的系统中使用RabbitMQ.
系统设计的两个重大问题.
第一条要满足未来的业务需求的不断变化和增加. 也就是可扩展性.
第二条要满足性能的可伸缩性. 也就是可集群性…通过增加机器能处理更多的请求
第三条要解耦合.
如果不解耦合, 未来业务增加或变更的时候你还在修改3年前写的代码.试问你有多大的把握保证升级好系统不出问题? 如何可以写新的代码而不用修改老代码所带来的好处谁都知道…
第四条简单易懂.
以上4条在任何一个系统中都要遵循的原则. 以前是无法做到的. 自从有了MQ以后. 这些都可以同时做到了.
以前的设计理念是把系统看作一个人,按照工作的指令从上到下的执行.
现在要建立的概念是, 把系统的各个功能看作不同的人. 人与人之间的沟通通过消息进行交流传递信息…
有了MQ以后把一个人的事情分给了不同的人, 分工合作所带来的好处是专业化, 并行化. 当然也引入了一些麻烦,性能开销多一些, 工作任务的完整性不能立即得到反馈.幸好我们可以通过最终一致性.来解决这个麻烦的问题…
下面进入正题.
第一个问题RabbitMQ是如何支持可扩展性的.
如上图, 寄件人P是系统的一个功能模块. 用来发送消息. 一般是在某些重要的业务状态变更时发送消息. 例如: 新订单产生时, 订单已打包时, 订单已出库时, 订单已发出时.
那么当事件 新订单产生时, 我们需要把这个信息告诉谁呢? 给财务? 还是给仓库发货?
这个地方最大的重点是. 当事件产生时. 根本不关心. 该投递给谁.
我只要把我的重要的信息投到这个乱七八糟的MQ系统即可. 其它人你该干嘛干嘛. 反正我的任务完成了. (有没有甩手掌柜的感觉..)
我只要告诉系统,我的事件属于那一类.
例如: “某某省.某某市.某某公司.产生新订单”
那么这个地址就属于 投递地址.. 至于这个地址具体投到哪个邮箱那是邮局的事情.
当然还有一些具体的订单内容也属于要告诉系统的内容.
那么下一个问题来了, 邮局怎么知道 你的这个消息应该投递给谁?
参考我们现实世界中的邮寄系统.是默认的省市县这么投递的. 这是固定思维.
但是我们的MQ系统中不是这样的. 是先有收件人的邮箱. (队列Queue). MQ才能投递. 否则就丢弃这个信息…
所以MQ系统应该先有收件人的邮箱 Queue 也就是队列. 才能接收到信息.
再有邮局
再有发信息的人.
RabbitMQ能实现系统扩展的一个重要功能在于, 可以两个邮箱收同一个地址的信.
翻译成专业的话 RabbitMQ 可以 两个队列Queue订阅同一个RoutingKey的信息..
RabbitMQ在投递的时候,会把一份信息,投递到多个队列邮箱中Queue…
这是系统可扩展性的基础.
第二个问题RabbitMQ如何满足性能的可伸缩性. 也就是可集群性
先上图
从上图, 可以看到. 性能扩展的关键点就在于 订阅人C1, 订阅人C2 轮流收到邮箱队列里面的信息, 订阅人C1和订阅人C2收到的信息内容不同, 但都属于同一类….
所以. 订阅人C1和订阅人C2是干同一种工作的客户端.用来提高处理能力.
上面说完了,如何使用. 下面再分析一下几个关注点.
如果订阅人的down机了. 信息会丢失吗?
事实上是不会的. 只要有邮箱(队列Queue)存在.信息就一直存在, 除非订阅人去取走.
如果订阅人一直down机, 邮箱队列能存多少信息?会不会爆掉?
理论上和实际上都是有上限的不可能无限多. 具体多少看硬盘吧..我没测到过上限.
我这篇文章并不打算讲解邮局的4种投递模式. 有其它文章讲的很好. 我只打算使用topic这种模式. 因为它更灵活一些.
再说一下我的另外两个观点.
不要在业务程序中用代码定义创建 邮局 ExChange. 和邮箱Queue队列 这属于系统设计者要构架的事情. 要有专门独立的程序和规则去创建. 这样可以统一管理事件类型.避免过多的乱七八糟的RoutingKey混乱.
我的理解认为
消息系统的分布式可扩展的实现在于消息广播, 集群性的实现在于邮箱队列.
RabbitMQ是先广播后队列的.
Exchange: 就是邮局的概念等同于 中国邮政和顺丰快递、
routingkey: 就是邮件地址的概念.
queue: 就是邮箱接收软件,但是可以接收多个地址的邮件,通过bind实现。
producer: 消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
其它关于投递模式, 请参考下面的两篇文章.
在边读边写的情况下:速率只与网络带宽正相关,网络使用率最高能达到接近100%,并且数据使用率很高(90%以上)。
在千兆网下,以500KB一条数据为例,读写速率均能达到200条/s,约为100MB/s。
在只写不读的情况下:写入速率瓶颈在于硬盘写入速度。
Windows环境下,在安装前设置环境变量:RABBITMQ_BASE=D:\RabbitMQ_Data
表现:磁盘写满后发送、读取程序均不能连接服务。
解决方法:将Queue、Exchange设置为Durable即不会发生数据丢失问题。
通过a.关闭服务;b.删除占位文件、erl_crash.dump;c.重启服务 三步操作后,磁盘会清理出10M左右空间,此时读取数据程序便可正常工作。
正确设计的架构,应确保RabbitMQ不会发生磁盘写满崩溃的情况。
在网络带宽占满的情况下,通过集群的方式解决吞吐量不足的问题需要多台效果才明显。
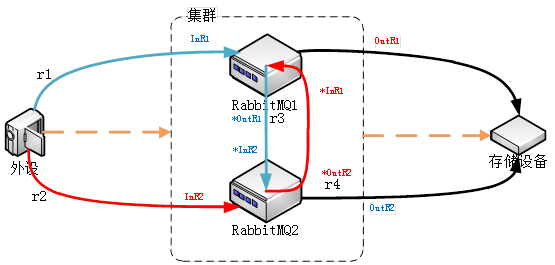
假设外设吞吐率为d条/s,外设向RabbitMQ1发送的概率为r1,向RabbitMQ2发送的概率为r2,RabbitMQ1需要向RabbitMQ2转发的概率为r3,RabbitMQ2需要向RabbitMQ1转发的概率为r3。那么RabbitMQ1进入的吞吐率为:(r1*d + r4*r2*d) 条/s ≈ 3d/4条/s,RabbitMQ2进入的吞吐率为:(r2*d + r3*r1*d) 条/s ≈ 3d/4条/s;这样的确比只使用一台RabbitMQ的吞吐率d条/s要求低些。
N台RabbitMQ的集群,每台的平均吞吐率为:(2N-1)d/(N*N) 条/s;N=3时,平均吞吐率为5d/9条/s;N=4时,平均吞吐率为7d/16条/s。
解决方法:多台RabbitMQ服务器提供服务,在客户端以轮循方式访问服务,若1台down掉则不使用此台的队列服务,服务器之间没有联系,这样N台RabbitMQ的平均吞吐率为:1d/N 条/s。具体实现可以,专写一个用户收发RabbitMQ消息的jar/dll,在配置文件里填写RabbitMQ机器地址,使用轮循询问、收发的方式,提供给应用程序以黑盒方式调用。下面提供了java版本的收发实现。
发送端sender.xml配置:
<!-- 处理器相关 -->
<bean id="sender" class="demo.Sender">
<property name="templates">
<list>
<ref bean="template1" />
<!-- <ref bean="template2" /> -->
</list>
</property>
</bean>
<bean id="timeFlicker" class="demo.TimeFlicker">
<property name="handlers">
<list>
<ref bean="sender" />
</list>
</property>
</bean>
<!-- 处理器相关 -->
<!-- amqp配置 相关 -->
<rabbit:connection-factory id="connectionFactory1"
host="192.1.11.108" username="guest" password="guest" virtual-host="/" />
<rabbit:connection-factory id="connectionFactory2"
host="192.1.11.172" username="guest" password="guest" virtual-host="/" />
<!-- amqp配置 相关 -->
<!-- 发送相关 -->
<rabbit:template id="template1" connection-factory="connectionFactory1"
exchange="exchange" />
<rabbit:template id="template2" connection-factory="connectionFactory2"
exchange="exchange" />
<!-- 发送相关 -->
说明:这里配置了两个RabbitMQ服务器,timeFlicker的目的是过一段时间把不能服务的RabbitMQ服务器重新添加到列表中,重试发送。
接收端receiver.xml配置:
<!-- amqp配置 相关 -->
<rabbit:connection-factory id="connectionFactory1"
host="192.1.11.108" username="guest" password="guest" virtual-host="/" />
<rabbit:connection-factory id="connectionFactory2"
host="192.1.11.172" username="guest" password="guest" virtual-host="/" />
<!-- amqp配置 相关 -->
<!-- 监听相关 -->
<bean id="Recv1" class="demo.Recv1" />
<rabbit:listener-container id="Listener1"
connection-factory="connectionFactory1" prefetch="1" acknowledge="auto">
<rabbit:listener ref="Recv1" method="listen"
queue-names="queue1" />
</rabbit:listener-container>
<bean id="Recv2" class="demo.Recv2" />
<rabbit:listener-container id="Listener"
connection-factory="connectionFactory1" prefetch="1" acknowledge="auto">
<rabbit:listener ref="Recv2" method="listen"
queue-names="queue2" />
</rabbit:listener-container>
<!-- 监听相关 -->
说明:这里监听了两个RabbitMQ服务器,此处不需要timeFlicker。
如需具体代码可以联系本人 。
我认为MQ丢数据的问题,主要是同步还是异步刷盘、断电是否导致的。只要send反馈正确,确保发送被接收,receive时有反馈后才会删除数据;同步刷盘,或异步刷盘不断电的,就不会丢失消息,
程序对于发送反馈异常的,要记录;MQ对于receive无反馈的,有重发机制,可能会有一条数据发送多次的情况,要在程序中剔除。
原文地址:https://www.cnblogs.com/hello-/articles/10345021.html
标签:好的 统一 个数 重要功能 同步 设计 短信 row 文本
原文地址:https://www.cnblogs.com/-xuan/p/13915082.html