标签:info 基于 存在 amp 服务类 监控 方式 实战 unix
Grab熔断器设计:如何应对突发打车峰值在东南亚,一旦下雨往往就不小。它成为一个重要的情绪因素,尤其是当你被困在外面的时候,你就会面临糟糕的一天。
在 Grab 的早期,如果雨来的时间不对,比如上班早高峰时间,那么我们这些工程师那一天也不好过。
在那个时候,Grab 叫车服务的需求增长速度远超我们的技术系统扩展能力,我们经常要加班到深夜,以确保系统能够处理不断增长的请求。当打车预订量突然激增时,我们的系统还是难以承载。
此外,还有其他因素导致了需求激增,例如,当公共交通服务出现故障,或者当大型活动如国际音乐会结束,所有的游客需要同时乘车。
经过思考,我们发现这些突发事件背后有两个方面的因素。
第一,这些事件都是局部事件。需求的增加来自于一个特定的地理位置,有时是一个很小的区域。这些局部事件有可能对我们的系统造成很大的负荷,以至于影响到地理位置以外的其他用户的体验。
其次,潜在的问题是,这些特定地理区域当时缺乏车辆供应。
在 Grab,我们的目标一直都是在每个人需要的时候和地点都能找到合适的司机,但上面这种情况,本来也是不可能达到的。我们需要找到一种方法来确保这种局部的需求激增不会影响到我们满足其他用户需求的能力。
Spampede 熔断器的灵感来自于我们之前博客上曾经提过的一个概念--熔断器。https://engineering.grab.com/designing-resilient-systems-part-1
在软件中,就如电子产品中一样,熔断器的设计是为了保护系统在面对不利条件下的短路。
下面我们来分析一下。
熔断器包括两个关键的概念:熔断和不利条件。
首先,熔断,在这里指的是对特定的订单量能够通过的最小处理量,通过这样做,减少系统的整体负荷。第二,不利条件,指的是在短时间内,在一个小的地理区域内,存在对某项服务大量未完成的请求。基于这两个概念,我们设计了以下流程。
首先,我们需要以位置感知的方式跟踪未分配的请求。为了做到这一点,我们使用 Geohash 整数算法对未分配请求的取值位置进行转换。
转换后,得到的值就是一个准确的位置。我们可以通过降低精度,将这个位置转换为 "桶" 或区域。
这种方法绝不是最好的,当然也不完全跟当地的地理位置相关,但是它的 CPU 效率非常高,而且不需要通过网络 API 调用外部资源。
现在我们可以跟踪未分配的请求,我们需要一种方法让跟踪有时间维度相关。毕竟,交通状况、司机位置和乘客需求是不断变化的。我们本来可以实现像滑动窗口总和这样的精确的东西,但是这样做会带来很多的复杂性,而且 CPU 和内存成本也会大大增加。
通过使用 Unix 时间戳,我们通过直接的公式将当前时间转换为 "桶" 的时间。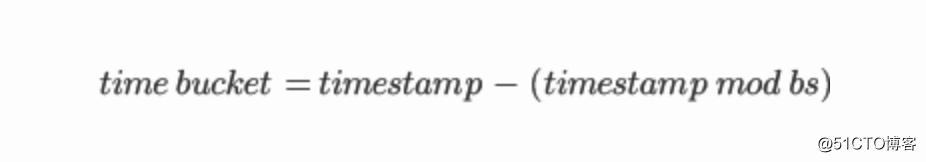
其中 bs 为时间桶的大小,单位为秒数。
通过位置和时间桶的计算,我们可以用 Redis 来追踪未分配的预订。也可以使用其他的数据存储软件,但 Redis 对我们来说非常熟悉,它也是经过实战检验的。
为了做到这一点,我们首先通过结合服务类型、地理位置和时间桶来构建 Redis key。有了这个 key,我们调用增加计数 INCR 命令,它将存储在该位置的值递增,并返回新的值。
如果返回的值是 1,这表明本地调用是这个时间桶的第一个值,然后我们将进行第二次调用 EXPIRE。将在 Redis 项上设置一个存活时间(TTL),让数据进行自我清理。
你会注意到,我们是盲目的调用增量,只在需要的时候再进行第二次 EXPIRE 调用。这种模式比起使用更传统的、load-check-store 的模式更有效率,也更节省资源。
下一步就是配置了。具体来说,就是设置在熔断器开启之前,在特定的位置和时间桶中,可以存在多少个未分配的预订量。我们再次使用 Redis。同样,使用 Redis 是因为对它相当熟悉。
最后要说明的是,我们在预订处理开始前就执行了检查,强调一下,在调用任何其他服务之前,我们就执行了检查代码。这个代码会将地点、时间和所请求的服务与当前配置的 Spampede 设置,以及之前未分配的预订量进行比较。如果已经达到了最大值,那么我们立即停止处理。
这听起来可能有点刺耳 — 还没有尝试调用就立即拒绝?但 Spampede 过滤器的设计目的就是为了防止过度的、局部的需求影响到系统的所有用户。
作为一个程序员,读到这里,可能会觉得很奇怪,有意把预订量降下来,这样会影响业务的发展。
说到底,我们想要做的只是帮助人们到达他们想要去的地方。这个过程是一个系统安全机制:确保系统健康并能够达成送达乘客这一目标。
如果我不强调一下这是关键软件工程的启示,是观察者效应和 CAP 定理的基本目标的结合,那我就失职了。观察者效应是指为了观察一个系统带来的指令及监控等成本,会对系统本身的运行产生影响。
一般来说,监测和限制的精度或一致性越高,消耗资源成本就越高。
在这种情况下,我们有意选择了最节省资源的方案,用较低的精度来换取更多的吞吐量。
英文原文:
https://engineering.grab.com/preventing-app-performance-degradation-due-to-sudden-ride-demand-spikes
参考阅读:
本文由高可用架构翻译,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。

标签:info 基于 存在 amp 服务类 监控 方式 实战 unix
原文地址:https://blog.51cto.com/14977574/2546127