标签:start 梯度下降法 vol 回顾 介绍 abd epo out code
深度学习测试题(1)答案和解析1.损失函数的定义预测值与真实值之间的差距。选A。
题中给出的是一个sigmoid函数极限的是在(0,1),这里问的是它的导数S‘(x)=S(x)(1-S(x)),所以应该是0。选B。
根据复合函数求二阶导数,容易得出答案1/4。选A。
首先被计算的是激活函数的梯度,选C。
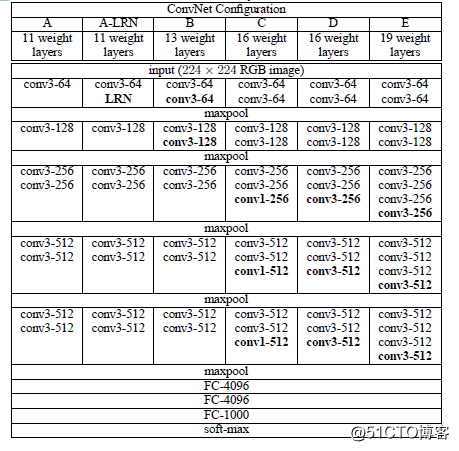
我们针对VGG16进行具体分析发现,VGG16共包含:
13个卷积层(Convolutional Layer),分别用conv3-XXX表示
3个全连接层(Fully connected Layer),分别用FC-XXXX表示
5个池化层(Pool layer),分别用maxpool表示
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是
VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
所以这里的16层指的是需要参与训练的层数。选C。
6.这题考察的是大家对keras搭建卷积神经网络的掌握能力。根据题意应选A。
举例 keras搭建VGG16网络部分展示
7.此题与上题类似,参考上图,选A。
8.选D。这图考察梯度消失的概念,dropout是防止过拟合的。
二、不定项选择题
选ABD。
补充:深度信念网络(DBN)通过采用逐层训练的方式,解决了深层次神经网络的优化问题,通过逐层训练为整个网络赋予了较好的初始权值,使得网络只要经过微调就可以达到最优解。
选ABD。
优化器超参数:包括学习率、minn_batch大小、迭代的epoch次数;
模型超参数:包括网络层数和隐藏层单元数。
选BD。
梯度是一个向量,目标函数在具体某点沿着梯度的相反方向下降最快,一个形象的比喻是想象你下山的时候,只能走一步下山最快的方向即是梯度的相反方向,每走一步就相当于梯度下降法的一次迭代更新。
选AB。常用的就是最大池化层和平均池化层。
选A。Dropout的做法是在训练过程中按一定的比例随机忽略或屏蔽一些神经元。


标签:start 梯度下降法 vol 回顾 介绍 abd epo out code
原文地址:https://blog.51cto.com/14993422/2548644