标签:nes excel mat 存在 blog erb taf pre 方式
DataFrame.to_excel(excel_writer, sheet_name=‘Sheet1‘, na_rep=‘‘, float_format=None, columns=None, header=True, index=True,
index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep=‘inf‘, verbose=True, freeze_panes=None)
常用参数解析 :
excel_writer : 字符串或ExcelWriter 对象,文件路径或现有的ExcelWriter
sheet_name :字符串,默认“Sheet1”,将包含DataFrame的表的名称。
na_rep : 字符串,默认‘ ’,缺失数据表示方式
float_format : 字符串,默认None,格式化浮点数的字符串
columns : 序列,可选,要编写的列
header : 布尔或字符串列表,默认为Ture。写出列名。如果给定字符串列表,则假定它是列名称的别名。
index :布尔,默认的Ture,写行名(索引)
index_label : 字符串或序列,默认为None。如果需要,可以使用索引列的列标签。如果没有给出,标题和索引为true,则使用索引名称。如果数据文件使用多索引,则需使用序列。
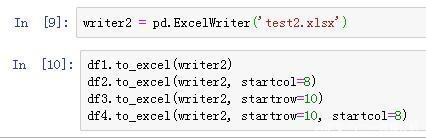
startrow :左上角的单元格行来转储数据框
startcol :左上角的单元格列转储数据帧
engine : 字符串,默认没有使用写引擎 - 您也可以通过选项io.excel.xlsx.writer,io.excel.xls.writer和io.excel.xlsm.writer进行设置。
merge_cells : 布尔,默认为Ture编码生成的excel文件。 只有xlwt需要,其他编写者本地支持unicode。
inf_rep : 字符串,默认“正”无穷大的表示(在Excel中不存在无穷大的本地表示)
freeze_panes : 整数的元组(长度2),默认为None。指定要冻结的基于1的最底部行和最右边的列
writer=pd.ExcelWriter("C:/Users/wlt/Desktop/XXX.xls")
mon1.to_excel(excel_writer=writer,sheet_name=‘201901‘)
mon2.to_excel(excel_writer=writer,sheet_name=‘201902‘)
mon3.to_excel(excel_writer=writer,sheet_name=‘201903‘)
mon4.to_excel(excel_writer=writer,sheet_name=‘201904‘)
mon5.to_excel(excel_writer=writer,sheet_name=‘201905‘)
writer.save()
writer.close()
https://blog.csdn.net/midion9/article/details/89000131
pandas - DataFrame 写入同一张excel表
标签:nes excel mat 存在 blog erb taf pre 方式
原文地址:https://www.cnblogs.com/treasury-manager/p/13957584.html