标签:arc 内存 问题 spl 例子 google 转换 产品 不可
https://www.robots.ox.ac.uk/~vgg/research/smooth-ap/
https://github.com/Andrew-Brown1/Smooth_AP
Smooth-AP: Smoothing the Path Towards Large-Scale Image Retrieval
Abstract
优化一个基于排名的度量,比如Average Precision(AP),是出了名的具有挑战性,因为它是不可微的,因此不能直接使用梯度下降方法进行优化。为此,我们引入了一个优化AP平滑近似的目标,称为Smooth-AP。Smooth-AP是一个即插即用的目标函数,允许对深度网络进行端到端训练,实现简单而优雅。我们还分析了为什么直接优化基于AP度量的排名比其他深度度量学习损失更有好处。
我们将Smooth-AP应用于标准检索基准:Stanford Online products和VehicleID,也评估更大规模的数据集:INaturalist用于细粒度类别检索,VGGFace2和IJB-C用于人脸检索。在所有情况下,我们都改善了最先进的技术的性能,特别是对于更大规模的数据集,从而证明了Smooth-AP在真实场景中的有效性和可扩展性。
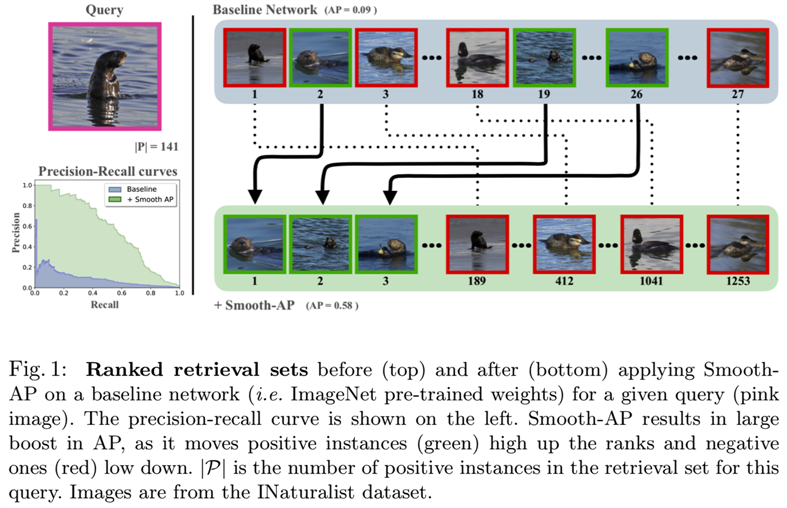
1 Introduction
本文的目标是提高“实例查询”的性能,其任务是:给定一个查询图像,根据实例与查询的相关性对检索集中的所有实例进行排序。例如,假设你有一张朋友或家人的照片,想要在你的大型智能手机图片集合中搜索那个人的所有图片;或者在照片授权网站上,您希望从一张照片开始查找特定建筑或对象的所有照片。在这些用例中,高recall是非常重要的,不同于“Google Lens”应用程序从图像中识别一个物体,其中只有一个“hit”(匹配)就足够了。
检索质量的基准度量是Average Precision(AP)(或其广义变体,Normalized Discounted Cumulative Gain,其中包括非二进制相关性判断)。随着深度神经网络的兴起,端到端训练已经成为解决特定视觉任务的实际选择。然而,AP和类似度量的核心问题是,它们包含了一个既不可微也不可分解的离散排序函数。因此,他们的直接优化,例如梯度下降方法,是出了名的困难。
在本文中,我们引入了一种新的可微AP近似,Smooth-AP,它允许用于基于排序任务的深度网络的端到端训练。Smooth-AP是一种简单、优雅、可扩展的方法,它通过放宽在使用了sigmoid函数的非可微AP中的指示函数(indicator function), 去采用即插即用的目标函数的形式。为了证明其有效性,我们在两个常用的图像检索基准上进行了实验,即Stanford Online Products和VehicleID,其中Smooth-AP优于所有最近的AP近似方法[5,54]以及最近的深度度量学习方法。我们还在三个大规模检索数据集(VGGFace2, IJB-C, INaturalist)上进行了实验,这些数据集比现有的检索基准大了一个数量级。据我们所知,这是第一个证明了在拥有数百万张图像的数据集上训练AP网络以完成图像检索任务的可能性的工作。我们发现,与最近提出的所有AP近似方法相比,性能有了很大的提高,而且,有些令人惊讶的是,性能也显著优于强验证系统[14,36],这反映了这样一个事实,即度量学习方法在训练大规模检索系统时确实效率低下,而这些系统是由全局排名指标来衡量的。
2 Related Work
作为信息检索的一个基本组成部分[38],优化排序指标的算法多年来一直是广泛研究的焦点。一般来说,之前的方法可以分为两种研究路线,即度量学习和AP的直接近似。
Image Retrieval. 这是视觉界研究最多的话题之一。几个主题已经在文献中探索,例如,一个主题是关于检索的速度和探索近似近邻的方法[13,28,29,31,47,60]。另一个主题是关于如何获得用于检索的紧凑的图像描述符,以减少内存占用。描述符通常是通过局部特征的集合来构建的,例如Fisher向量[46]和VLAD[2,30]。最近,神经网络在学习图像检索的表示方面取得了令人印象深刻的进展[1,3,18,51,69],但普遍的是选择用于训练的损失函数;特别是,理想情况下,它应该是一种能够促进良好排名的损失。
Metric Learning. 为了避免直接优化基于排序的度量的困难,比如Average Precision,有大量的工作集中在度量学习[1,2,4,8,10,12,31,34,42,44,52,64,70,73]。例如contrastive[12]和triplet[73]损失,考虑成对或三对元素,迫使所有正的实例在高维嵌入空间内接近,而把负例的用固定的距离(边界)隔开。然而,正如Burges等人[4]所指出的,由于pair/triplet提供的排序-位置感知有限,模型很可能会浪费容量,以牺牲高阶正实例的排序为代价来提高低(差)阶正实例的排序。更有相关性的是,list-wise方法[4,8,42,44,70]查看了检索集中的许多例子,并被证明可以提高训练效率和性能。尽管取得了成功,但度量学习方法的一个缺点是,它们大多是由最小化距离驱动的,因此忽略了改变排名顺序的重要性——后者在使用基于排序的度量时至关重要。
Optimizing Average Precision (AP). 最近在检索界,直接优化不可微AP的趋势又重新流行起来。复杂的方法[5,10,16,23,24,25,40,48,53,54,61,63,64,76,78]已经开发出来,以克服AP优化中的不可分解和不可微性的挑战。方法包括:通过把每个相关性分数看作高斯随机变量[63]来创建一个分布排名、loss-augmented推论[40]、直接损失最小化[61]、优化平滑和可微的AP上界[40,41,78]、训练一个LSTM去近似离散排名步骤[16]、可微的histogram binning[5,23,24,53,64](如listwise loss)、错误驱动的更新方案[11]和最近的黑箱优化[54]方法。信息检索界在AP优化方面取得了显著进展[4,9,19,35,50,63],但是这些方法在很大程度上被视觉界所忽视,这可能是因为它们从未在大规模图像检索中得到证明,或者由于所提出的平滑目标的复杂性。这项工作的动机之一是为了表明,随着深度学习研究的进展,例如自微分、更好的优化技术、大规模数据集和快速计算设备,直接优化AP近似值是可能的,而且实际上非常容易。
3 Background
在这一节中,我们定义了整篇文章中使用的符号。
Task definition. 给定一个输入查询,检索系统的目标是在检索集![]() 中,基于他们与查询的相关性,排序所有的实例。对于每个查询实例
中,基于他们与查询的相关性,排序所有的实例。对于每个查询实例![]() ,检索集被分成正例
,检索集被分成正例![]() 和负例
和负例![]() 集,分别使用所有实例的同类和不同类组成。注意,对于每个查询,有一个不同的正例子和负例集。
集,分别使用所有实例的同类和不同类组成。注意,对于每个查询,有一个不同的正例子和负例集。
Average Precision (AP). AP是信息检索任务[38]的标准度量之一。它是一个单一值,定义为精确-召回曲线下的面积。对于一个查询![]() ,检索集中所有实例的预测相关性分数是通过一个选定的度量来度量的。在我们的例子中,我们使用余弦相似度(尽管Smooth-AP方法与这个选择无关):
,检索集中所有实例的预测相关性分数是通过一个选定的度量来度量的。在我们的例子中,我们使用余弦相似度(尽管Smooth-AP方法与这个选择无关):
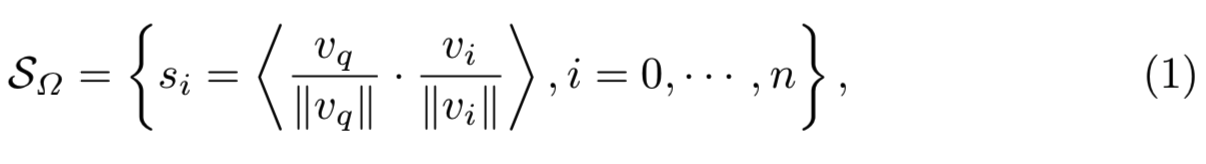
其中![]() 分别是正、负相关性分数集合,vq表示查询向量,vi表示向量检索集。查询
分别是正、负相关性分数集合,vq表示查询向量,vi表示向量检索集。查询![]() 的AP可以计算为:
的AP可以计算为:
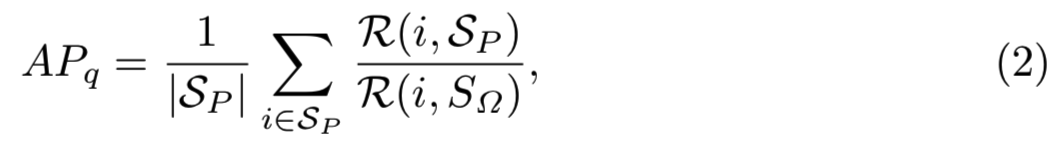
其中![]() 分别表示实例i在
分别表示实例i在![]() 和
和![]() 中的排序。注意,在本论文中提到的排序假设为proper排序,即不会有两个样本等价排序。
中的排序。注意,在本论文中提到的排序假设为proper排序,即不会有两个样本等价排序。
Ranking Function (![]() ). 指明AP是基于排序的方法,直接优化的关键元素是定义一个实例i的排序
). 指明AP是基于排序的方法,直接优化的关键元素是定义一个实例i的排序![]() 。在这里,我们遵循[50]将其定义为:
。在这里,我们遵循[50]将其定义为:
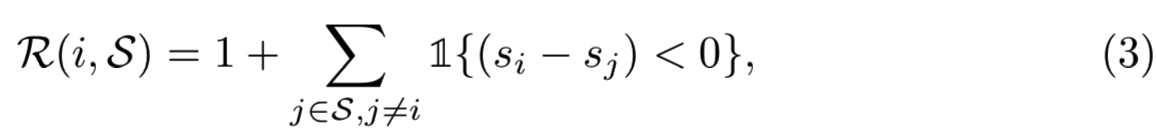
其中![]() 表示指示函数,
表示指示函数,![]() 表示任意集合,如
表示任意集合,如![]() 。简单来说,其可以通过计算差分矩阵
。简单来说,其可以通过计算差分矩阵![]() 实现:
实现:

来自等式(2)的用于一个查询实例![]() 的真实AP为:
的真实AP为:
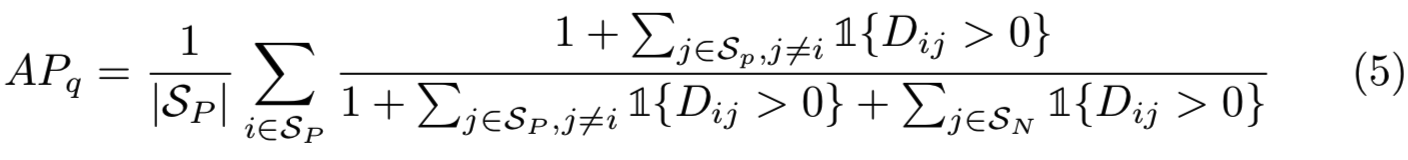
Derivatives of Indicator. 用来计算AP的特殊指示函数是一个Heaviside step function ![]() [50],其分布式导数定义为Dirac delta function:
[50],其分布式导数定义为Dirac delta function:
![]()
这要么是处处平坦的,即处处零梯度的;要么是不连续的,因此不能用基于梯度的方法对其进行优化(图2)。
4 Approximating Average Precision (AP)
如上所述,AP和类似的度量标准包括一个既不可微也不可分解的离散排序函数。在本节中,我们首先描述了Smooth-AP,它本质上用sigmoid函数代替了离散的指示函数,然后我们分析了它与其他排序损失的关系,如triplet loss[26,73]、FastAP[5]和Blackbox AP[54]。
4.1 Smoothing AP
为了平滑排序过程,实现AP的直接优化,Smooth-AP使用了一个简单的解决办法,即使用sigmoid函数![]() 替换指示函数
替换指示函数![]() ,其中
,其中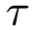 表示调节锐度的温度指标:
表示调节锐度的温度指标:

替换![]() 到等式(5)中,即真正的AP被近似为:
到等式(5)中,即真正的AP被近似为:
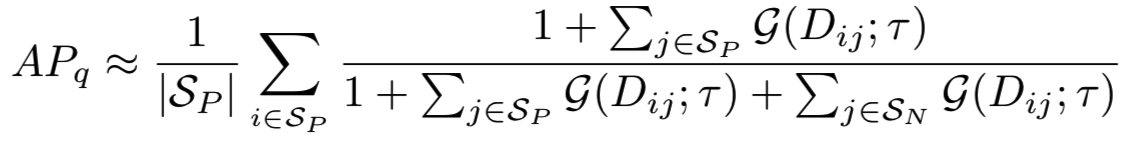
有着更严格的近似,且当![]() 是收敛于原来的指示函数。优化期间,目标函数被表示为:
是收敛于原来的指示函数。优化期间,目标函数被表示为:
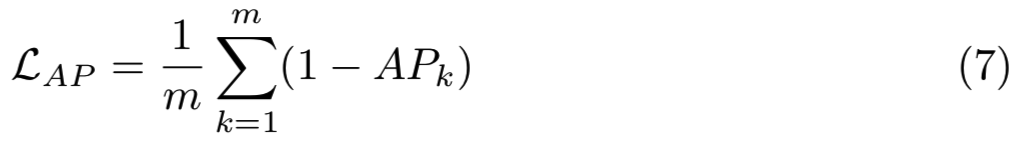
平滑参数支配了替换指示函数![]() 的sigmoid的温度。它定义了一个操作区域,其中的差分矩阵的项是由Smooth-AP损失给定的梯度。如果项排列错误,Smooth-AP将尝试将它们转换到正确的顺序。具体来说,一个小的值导致小的操作区域(图2 (b) -标注在sigmoid导数中可见梯度的小区域,即横轴0处的有梯度区域),和更严格的真实AP的近似。在零点周围梯度的强加速(图2 (b) - (c)第二行)是复制AP期望质量的基础,因为它鼓励实例在嵌入空间的转移,其导致排名的变化(因此改变AP),而不是改变一些大距离的实例但不改变排序。较大的值提供了一个大的操作区域,然而,以AP的一个松散的近似为代价,因为它偏离了原始的指示函数。
的sigmoid的温度。它定义了一个操作区域,其中的差分矩阵的项是由Smooth-AP损失给定的梯度。如果项排列错误,Smooth-AP将尝试将它们转换到正确的顺序。具体来说,一个小的值导致小的操作区域(图2 (b) -标注在sigmoid导数中可见梯度的小区域,即横轴0处的有梯度区域),和更严格的真实AP的近似。在零点周围梯度的强加速(图2 (b) - (c)第二行)是复制AP期望质量的基础,因为它鼓励实例在嵌入空间的转移,其导致排名的变化(因此改变AP),而不是改变一些大距离的实例但不改变排序。较大的值提供了一个大的操作区域,然而,以AP的一个松散的近似为代价,因为它偏离了原始的指示函数。
Relation to Triplet Loss. 在这里,我们证明了triplet损失(一个流行的替代排序损失)实际上是优化了距离度量而不是排序度量,其在使用排序度量进行评估时结果是次优的。如等式(5)所示,优化AP的目标等价于最小化所有的![]() ,即violating项。我们之所以这样等价,是因为这些项指的是这样一种情况:就查询的相关性而言,负例排在了正例的前面。只有当所有正例都排在负例前面时,才能获得最佳AP。
,即violating项。我们之所以这样等价,是因为这些项指的是这样一种情况:就查询的相关性而言,负例排在了正例的前面。只有当所有正例都排在负例前面时,才能获得最佳AP。
例如,考虑一个具有预测相关性分数和ground-truth相关性标签的查询实例:
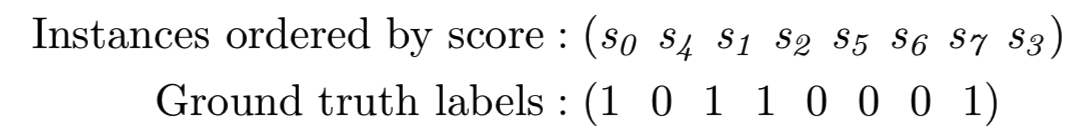
其中violating项有![]() 。
。
理想的AP损失实际上会不平等地对待每一个项,即模型将被迫花费更多的能力去转移s4和s1之间的顺序,而不是s3和s7,因为这会对AP的改善产生更大的影响。
对这些violating情况的另一种解释,也可以从triplet损失的角度得出。具体来说,如果我们将查询实例视为一个“anchor”,sj表示“anchor”与负例之间的相似性,si表示“anchor”与正例之间的相似性。在本例中,triplet损失试图优化margin hinge损失:
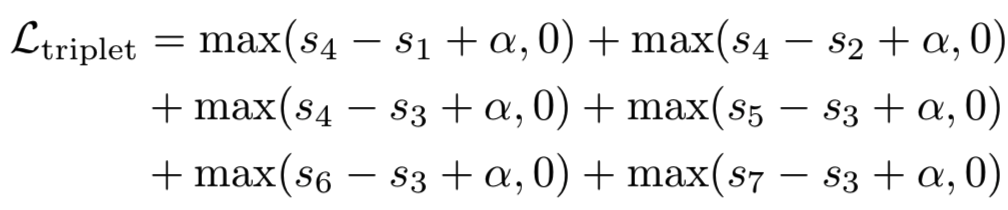
这可以看作是对AP优化目标的可微近似,其中指示函数已被margin hinge损失取代,从而解决了梯度问题。然而,使用triplet损失来近似AP可能会遇到两个问题:首先,所有的项都是线性结合的,并且在Ltriplet中同等对待。这样一个替代损失可能会迫使模型优化AP只有一个小的影响的项,如在triplet损失中,优化s4?s1和优化s7?s4是相同的。然而,从AP的角度来看,在高排名处纠正错误排序的实例是十分重要的。其次,线性导数意味着优化过程纯粹是基于距离(而不是排序顺序),这使得AP在评价时处于次优状态。例如,在triplet损失情况下,将s4?s1的距离从0.8减小到0.5等同于从0.2减小到?0.1。然而,在实践中,后一种情况(移动顺序)对AP计算的影响显然要比前一种情况大得多。
Comparison to other AP-optimising methods. Smooth-AP与最近引入的FastAP和Blackbox AP之间的两个关键区别是Smooth-AP (i)提供了更接近AP的方法,以及(ii)实现起来更简单。首先,由于采用了sigmoid函数,Smooth-AP优化了排序度量,因此与AP具有相同的目标。相比之下,FastAP和Blackbox AP对不可微(分段常数)函数进行线性插值,这可能会导致与triplet损失相同的潜在问题,即优化距离度量,而不是排名。其次,Smooth-AP只需将AP目标中的指标函数替换为sigmoid函数即可。FastAP使用抽象,比如Histogram Binning,而Blackbox AP使用数值导数的变体。这些差异通过几个数据集上的Smooth-AP改进的性能得到了肯定(第6.5节)。

5 Experimental Setup
在本节中,我们将描述用于评估、测试协议和实现细节的数据集。接下来的步骤是采用一个预先训练好的网络,并使用Smooth-AP损失进行微调。具体来说,ImageNet预训练网络用于对象/动物检索数据集,高性能人脸验证模型用于人脸检索数据集。
5.1 Datasets
我们评估Smooth-AP损失的五个数据集包含广泛的领域和大小。其包括常用的检索基准数据集,以及一些额外的大规模(>100K图像)数据集。表1描述了它们的详细信息。
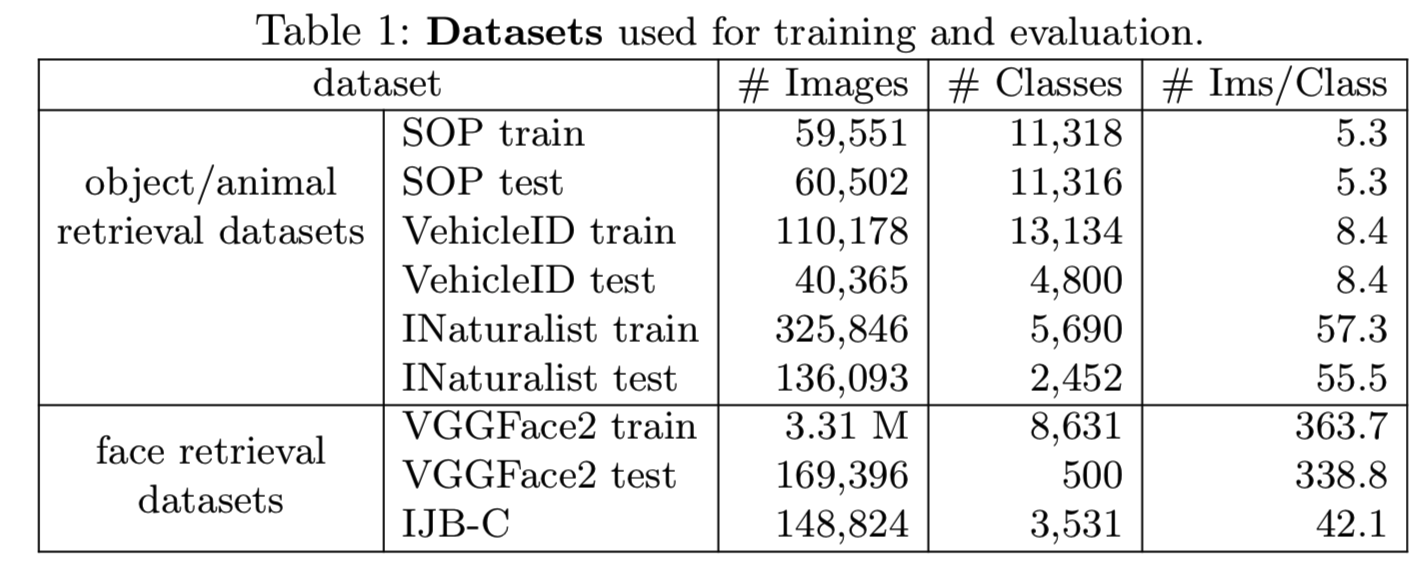
Stanford Online Product (SOP)[61]最初是为调查度量学习问题而收集的。其中包括12万张网上销售的产品图片。我们使用与[70]相同的评估协议和训练/测试分割。
VehicleID[67]包含26267个车辆类别的222,736幅图像,其中有13,134类用于训练(包含110178幅图像)。按照与[67]相同的测试协议,使用三个增大大小的测试集进行评估(称为small、medium、large),分别包含800个类(7,332幅图像)、1600个类(12,995幅图像)和2400个类(20,038幅图像)。
INaturalist[65]是一个大型的动植物物种分类数据集,旨在通过8142个类别的461,939张图像来复制真实世界的场景。它以许多视觉上相似的物种为特色,拍摄于各种各样的环境中。根据与现有基准测试相同的测试协议,我们从这个数据集中构建了一个新的图像检索任务,通过保留5,690个类用于训练,以及2,452个不可见类用于测试时评估图像检索[70]。我们将公开训练/测试split。
VGGFace2[7]是一个大规模的人脸数据集,拥有9131个受试者的331万张图像。这些照片在姿势、年龄、光照、种族和职业(如演员、运动员、政治家)方面有很大的变化。对于训练,我们使用带有8,631个身份的预定义训练集,对于测试,我们使用带有500个身份的测试集,总共有169K张测试图像。
IJB-C[39]是一种具有挑战性的人脸识别公开基准,它包含静态帧和视频中受试者的图像。通过将每帧CNN产生的向量平均为单个向量,每个视频都被视为单个实例。少于5个实例(图像或视频)的身份将被删除。
5.2 Test Protocol
在这里,我们描述了评估检索性能的协议,Average Precision (mAP)和Recall@K (R@K)。对于所有数据集,按序使用每个类的每个实例作为查询![]() ,检索Ω由所有剩余的实例形成。我们确保每个类数据集包含几个图片(表1),这样如果使用类的一个实例的查询,这样在检索集中也能有一些剩余正例。对于对象/动物的检索评估,为了与现有的其他工作作比较,我们还使用Recall@K度量。对于人脸检索,AP是根据每个查询的结果输出排名计算的,而mAP得分是通过对数据集中每个实例的AP进行平均计算的,从而得到一个值。
,检索Ω由所有剩余的实例形成。我们确保每个类数据集包含几个图片(表1),这样如果使用类的一个实例的查询,这样在检索集中也能有一些剩余正例。对于对象/动物的检索评估,为了与现有的其他工作作比较,我们还使用Recall@K度量。对于人脸检索,AP是根据每个查询的结果输出排名计算的,而mAP得分是通过对数据集中每个实例的AP进行平均计算的,从而得到一个值。
5.3 Implementation Details
Object/animal retrieval (SOP, VehicleID, INaturalist). 与之前的工作一样[5,5,56,58,72,74],我们使用ResNet50[21]作为主干架构,它是在ImageNet[57]上预先训练的。我们将最后的softmax层替换为一个线性层(如[5,54],维度设置为512)。所有图像大小调整为256×256。在训练时,我们使用随机裁剪和翻转作为数据增强,在测试时,使用单一中心裁剪,大小为224×224。对于所有实验,我们都将设置为0.01(6.4节)。
Face retrieval datasets (VGGFace2, IJB-C). 我们使用两个高性能人脸验证网络:该方法使用SENet-50架构[7][27]和最先进的ArcFace[14](使用ResNet-50),都在VGGFace2训练集上训练。对于SENet-50,我们遵循[7]和使用相同的人脸裁剪(延长建议的量),大小为224×224,我们L2-normalize最后的256维嵌入。对于ArcFace,我们使用提供的人脸检测器[14]生成归一化的人脸裁剪(112×112),并将其与预测的5个人脸关键点进行对齐,然后对最终的512维嵌入进行l2-归一化。对于这两种模型,我们将批大小设置为224,将设置为0.01(章节6.4)。
Mini-batch training. 在训练过程中,我们通过对类进行随机抽样,形成每个小batch,使每个出现的类每个类都有|P|个样本。在所有实验中,我们对嵌入进行L2-normalize,使用余弦相似度计算查询和检索集之间的相关性得分,将|P|设为4,使用学习率为10?5,权值递减为4e?5的Adam[33]优化器。我们仅对Online Products数据集采用了与[5,54]相同的hard negative mining技术。否则,我们不使用特殊的抽样策略。
6 Results
在这一节中,我们首先通过检查不同模型在五个检索数据集上的性能来探讨所提出的Smooth-AP的有效性。具体来说,我们比较了最近在标准基准SOP和vehicleID上的AP优化和更广泛的度量学习方法(章节6.1),然后转向进一步的大规模实验,例如用于动物/植物检索的INaturalist,用于人脸检索的IJB-C和VGGFace2(章节6.2-6.3)。然后,我们对影响Smooth-AP性能的各种超参数进行了ablation研究:sigmoid温度、正集的大小和batch size(6.4节)。最后,我们将讨论各种发现并分析各种模型之间的性能差异(第6.5节)。
注意,虽然有丰富的论文使用这些图像检索基准去研究度量学习方法[15,17,20,32,34,37,42,43,45,49,54,61,62,64,68,70,71,72,74,75,77],我们只列出了最近最先进的方法,并试图与他们尽可能公平地比较,如没有模型集合,且使用相同的骨干网络和图像分辨率。然而,在一些小的实验细节上仍然存在差异,比如嵌入维度、优化器和学习率。INaturalist数据集的定性结果如图3所示。

6.1 Evaluation on Stanford Online Products (SOP)
我们将其与各种最先进的图像检索方法进行比较,例如深度度量学习方法[56,58,72,74]和AP近似方法[5,54]。如表2所示,我们观察到Smooth-AP在SOP基准测试中获得了最先进的结果。特别是,我们最好的模型比最近的AP近似方法(Blackbox AP和FastAP)在Recall@1上的表现高出1.5%。此外,Smooth-AP的执行与并发工作(Cross-Batch Memory [72])相当。这是特别令人印象深刻的,因为[72]利用内存技术同时从许多小批次中采样来更新每个权值,而Smooth-AP只在每个训练迭代中使用单个小批。
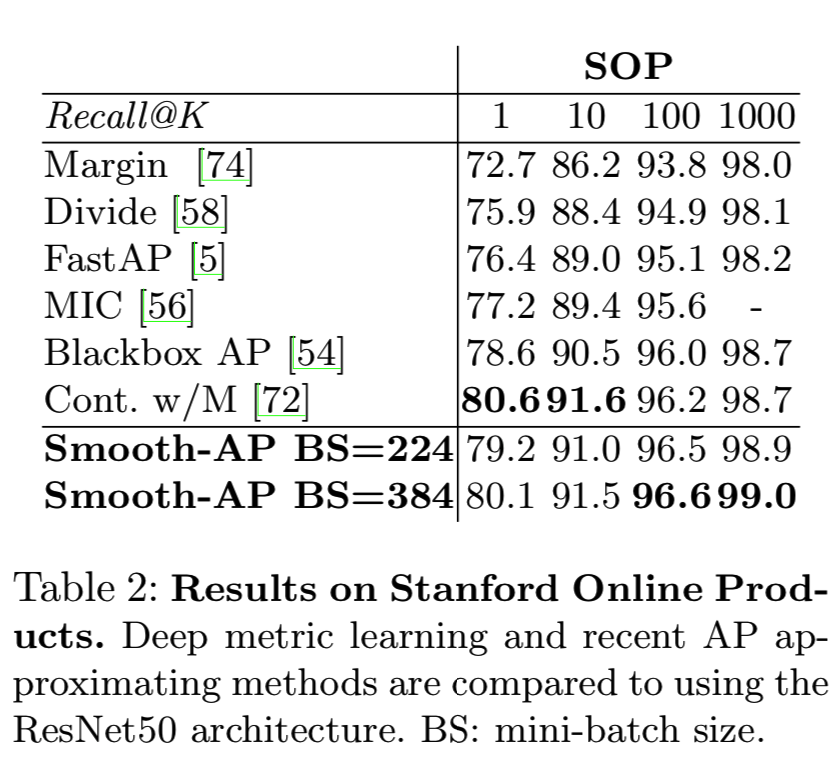
图4定量分析了sigmoid温度指标对AP近似紧密性的影响,其可通过AP近似误差绘制出:
![]()
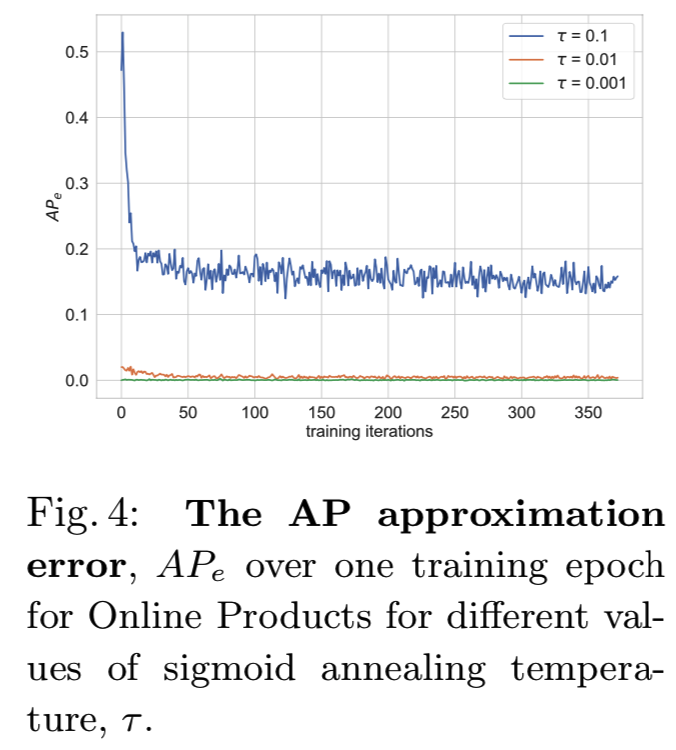
其中,当用sigmoid代替公式5中的指示函数时,APpred是预测的近似AP,而AP是真实的AP。正如预期的那样,由上图低的近似误差说明,较低的值会导致更接近AP。
6.2 Evaluation on VehicleID and INaturalist
在表3中,我们显示了在VehicleID和INaturalist数据集上的结果。我们观察到Smooth-AP在具有挑战性和大规模的VehicleID数据集上实现了最先进的结果。特别是,对于small protocal Recall@1,我们的模型的性能显著优于FastAP 3%。此外,Smooth-AP在6个召回指标中的4个方面都优于[72]。
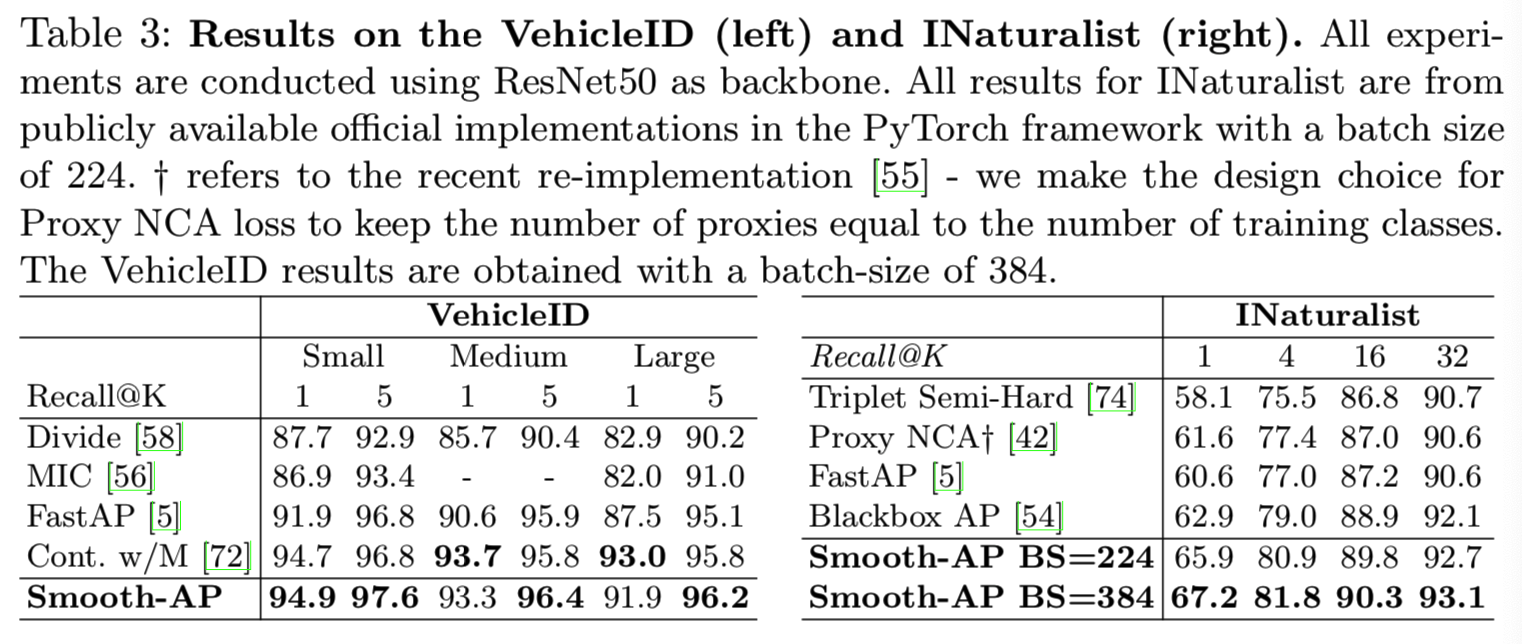
因为我们是第一个报告INaturalist图像检索结果的,除了Smooth-AP,我们重新训练了最先进的度量学习和AP近似方法,使用各自的官方代码,如Triplet和ProxyNCA [55], FastAP [6]和Blackbox AP[66]。如表3所示。在使用相同批量大小(224)的实验中,Smooth-AP在Recall@1上比所有方法的性能都好2 - 5%。如果将Smooth-AP的批大小增加到384,那么Recall@1的批大小将进一步增加1.4%至66.6。这些结果表明Smooth-AP特别适合于大规模检索数据集,从而显示了它在实际检索问题中的可扩展性。我们在这里注意到,这些大型数据集(>100k图像)受超参数调优的影响较小,因此为演示改进的图像检索技术提供了理想的测试环境。
6.3 Evaluation on Face Retrieval
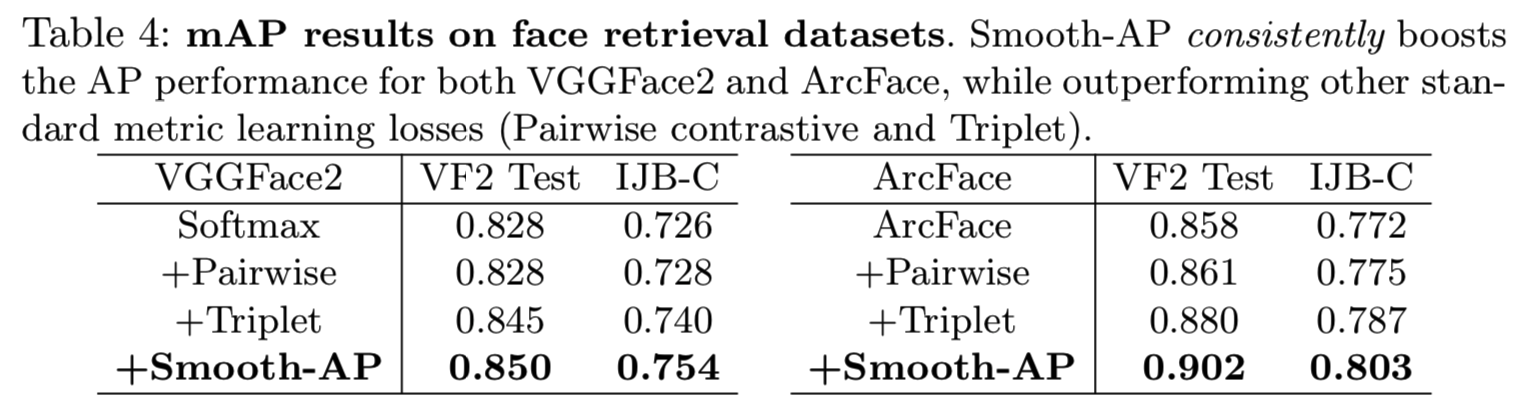
由于[7,14]结果令人印象深刻,人脸检索被认为是饱和的。然而,我们在此证明Smooth-AP可以进一步提高人脸检索性能。具体来说,我们在现代方法(VGGFace2和ArcFace)的基础上添加了Smooth-AP,并对IJB-C和VGGFace2上的mAP进行评估,即最大的人脸识别数据集之一。
如表4所示,当添加Smooth-AP损失时,两个数据集的检索指标,如mAP,可以在基线模型上有显著改善。这是非常令人印象深刻的,因为这两个基线在人脸验证和识别任务上都已经显示出了非常强的性能,而Smooth-AP在VGGFace2和ArcFace上的mAP分别提高了4.4%和3.1%。此外,Smooth-AP的表现强于pairwise[12]和triplet[59]损失,即两个最受欢迎的排名损失。正如4.1节中所讨论的,这些损失优化了距离度量而不是排名度量,结果表明后者对AP来说是最优的。
6.4 Ablation study
调查不同的超参数设置的影响,例如,sigmoid温度![]() 、正集|P|的大小和批量大小B(表5),我们使用VGGFace2和使用SE-Net50的IJB-C [7],因为大规模数据集不太可能导致过拟合,因此可以对这些超参数提供一个公平的理解。注意,我们每次只改变一个参数。
、正集|P|的大小和批量大小B(表5),我们使用VGGFace2和使用SE-Net50的IJB-C [7],因为大规模数据集不太可能导致过拟合,因此可以对这些超参数提供一个公平的理解。注意,我们每次只改变一个参数。
Effect of sigmoid temperature . 如4.1节所述,在Smooth-AP损失中,![]() 支配着用于近似指标函数的sigmoid的平滑。ablation结果显示,0.01值的mAP 分数为最佳,这是AP近似与提供梯度的足够大的操作区域之间的最佳权衡。令人惊讶的是,这个值(0.01)对应的是一个很小的操作区域。我们推测,对真实AP的紧密逼近是关键,当与足够大的batch size合作时,为了诱导足够的重新排序梯度,足够的差分矩阵元素将位于操作区域内。sigmoid温度可以进一步从边界的角度来看(类间margins通常用于度量学习以帮助归纳[12,44,73])。Smooth-AP仅停止提供梯度,去将一个正例推到一个负例之上,一旦它们距离等于操作区域的宽度时,这个
支配着用于近似指标函数的sigmoid的平滑。ablation结果显示,0.01值的mAP 分数为最佳,这是AP近似与提供梯度的足够大的操作区域之间的最佳权衡。令人惊讶的是,这个值(0.01)对应的是一个很小的操作区域。我们推测,对真实AP的紧密逼近是关键,当与足够大的batch size合作时,为了诱导足够的重新排序梯度,足够的差分矩阵元素将位于操作区域内。sigmoid温度可以进一步从边界的角度来看(类间margins通常用于度量学习以帮助归纳[12,44,73])。Smooth-AP仅停止提供梯度,去将一个正例推到一个负例之上,一旦它们距离等于操作区域的宽度时,这个![]() 的选择将强制margin大约等于为0.1。
的选择将强制margin大约等于为0.1。
Effect of positive set |P|. 在此设置中,正集表示在训练期间来自同一类的mini-batch实例。我们观察到一个小值(4)导致最高的mAP分数,这是因为mini-batches是在类级别上采样形成的,一个较低的值 |P|意味着更多的样本类和更高的概率抽样到违反正确的排名顺序的hard-negative实例。增加batch中类的数量可以使批处理更接近真实的类分布,从而使每次训练迭代都能强制得到结构更优化的嵌入空间。
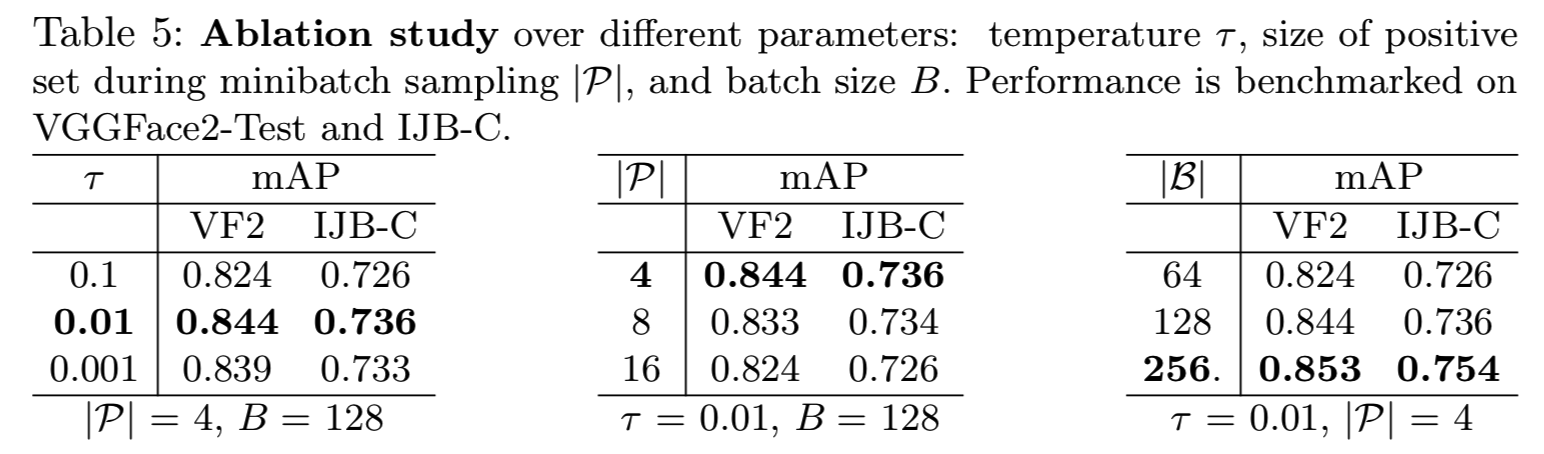
Effect of batch size B. 表5显示,较大的批处理大小会产生更好的mAP,特别是对于VGGFace2。这是意料之中的,因为它再次增加了在batch中得到hard-negative实例的机会。
6.5 Further discussion
在上述结果中有几个重要的观察结果。Smooth-AP在三个图像检索基准(SOP、VehicleID、Inaturalist)上优于所有以前的AP近似方法,以及度量学习技术(pairwise、triplet和list-wise),在大规模的Inaturalist数据集上,性能差距尤其明显。同样,当扩展到包含数百万张图像的人脸数据集时,Smooth-AP能够提高最先进的人脸验证网络的检索指标。我们假设,相对于其他现有的AP近似方法,这些性能增益来自于对AP的更紧密的近似,从而证明了Smooth-AP的有效性和可扩展性。此外,深度度量学习损失手动加入到他们各自方法中的许多属性(如基于距离的加权[61,74]、类间边界[12,59,61,70]、类内边界[70]),都被自然地构建到我们的AP公式中,并导致改进的泛化能力。
7 Conclusions
我们引入了Smooth-AP,这是一种新的损失,直接优化了AP的平滑近似。这与现代contrastive、triplet和list-wise的深度度量学习损失形成对比,后者作为鼓励排序的替代品。我们说明了Smooth-AP优于最近的AP优化方法,以及深度度量学习方法,并使用了简单优雅的即插即用风格的方法。我们提供了Smooth-AP优于其他损失的原因分析,即Smooth-AP保持了AP的目标,即优化嵌入空间中的排名而不是距离。此外,我们还证明了通过附加Smooth-AP损失来微调人脸验证网络可以显著提高性能。最后,为了缩小实验设置和真实检索场景之间的差距,我们在几个大规模数据集上进行了实验,结果显示Smooth-AP损失比以前的近似方法具有更大的可扩展性。
标签:arc 内存 问题 spl 例子 google 转换 产品 不可
原文地址:https://www.cnblogs.com/wanghui-garcia/p/13959190.html