标签:维护 同事 rgba cli 运行 info drive 精简 lazy
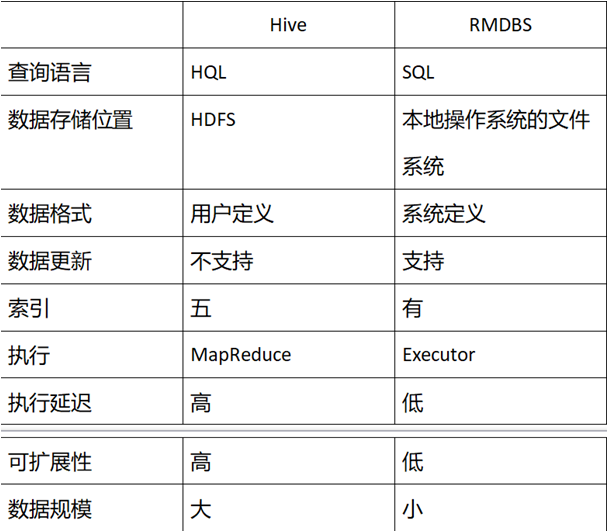
前面我们讲到了mapreduce计算框架,各位需要通过java编码的形式来实现设计运算过程,Hive的设计目的就是为了让精通sql技能而java较弱的分析师能够利用hadoop进行各种分析,HiveSQL和SQL非常相似,只需要对SQL熟练即可
Hive的特点:

Hive与Hadoop的HDFS和Mapreduce计算框架不同,Hive并不是分布式,他是独立在集群之外,可以看做是一个单独的Hadoop的客户端
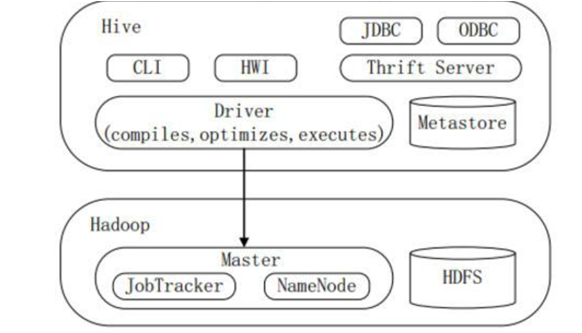
可以ton过CLI(命令接口),HWI(hive网络界面)以及Thrift Server提供的JDBC和ODBC的方式访问Hive,其中最常见的是Hive命令是Hive命令行接口。用户通过以上方式向Hive提交查询命令,而命令会进入Driver模块,通过模块进行解释和变异对需求进行优化完成作业。
Metastore是Hive的元数据的集中存放地,他保存了Hive的元数据信息,也就是表的信息和列的信息。
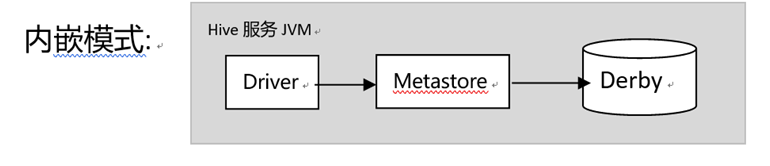
4-1:内嵌模式
这是最简单的模式,元数据服务和Hive服务运行在同一个JVM中,同事使用内嵌的Derby数据库作为元数据存储,该模式支持同事最多一个用户打开hive会话
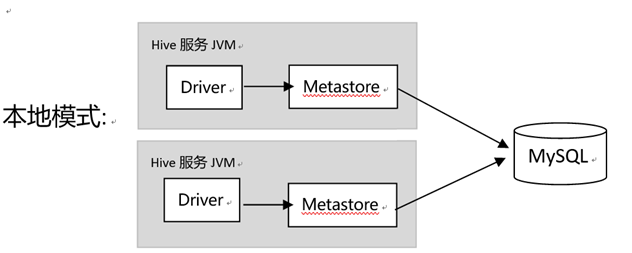
4-2:本地模式
元数据服务和hive服务仍在一个JVM中,不同的是采用了外置的MySQL数据库作为元数据存储,该方法支持多个用户同事访问Hive
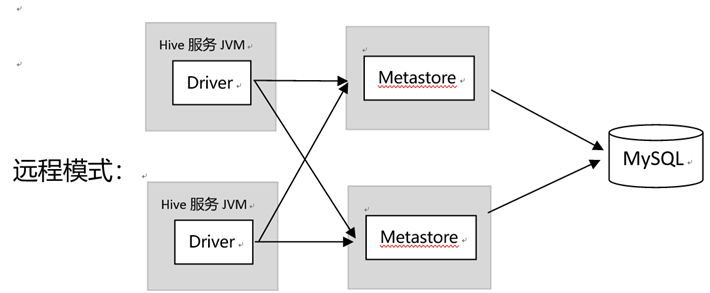
4-3:远程模式
元数据服务和Hive服务运行在不同的进程内,这样的好处是数据库完全置于防火墙之外,客户端登录不需要验证。
标签:维护 同事 rgba cli 运行 info drive 精简 lazy
原文地址:https://www.cnblogs.com/wyk1/p/13996106.html