标签:浮点运算 模型 就是 command 挑战 ble 程序 引入 lin
用NVIDIA NsightcComputeRoofline分析加速高性能HPC的应用
编写高性能的软件不是一件简单的任务。当有了可以编译和运行的代码之后,当您尝试并理解它在可用硬件上的执行情况时,将引入一个新的挑战。不同的平台,无论是cpu、gpu还是其他平台,都会有不同的硬件限制,比如可用内存带宽和理论计算限制。Roofline性能模型帮助您了解应用程序使用可用硬件资源的情况,以及哪些资源可能会限制应用程序的性能。在劳伦斯伯克利国家实验室,国家能源研究科学计算中心(NERSC)和计算研究部(CRD)一直在使用该模型来分析和优化NVIDIA gpu上运行的HPC代码。
传统的Roofline模型依赖于两个特征来描述工作量:
算力:计算工作(FLOPs)和数据移动(字节)之间的比率
FLOP/s:每秒浮点运算
有了这些信息,可以在一个包含性能限制的Roofline和顶层的图形上绘制一个内核,并将它们对内核的影响可视化。
Roofline模型是在伯克利实验室发明的。一种用于收集NVIDIA GPU Roofline分析的相关性能数据的方法,该方法已经被原型化和验证:
基于Roofline模型的GPU加速应用性能分析
高性能HPC和深度学习应用的Roofline性能建模
gpu的分层Roofline分析:加速NERSC-9 Perlmutter系统的性能优化
鉴于Roofline分析在高性HPC中的普及,NVIDIA已经与伯克利实验室合作,并将其集成到NVIDIA Nsight Compute中。随着其2020.1版本的发布,Nsight Compute为HPC应用程序的Roofline分析提供了一种更为简化的方式,并且更容易与Nsight Compute中的其他功能集成,以便进行性能分析。
Using Nsight Compute to collect roofline data
Nsight Compute是一个CUDA内核分析器,它提供详细的性能度量和优化建议。现在,它还可以收集和显示Roofline分析数据。要在报告中启用Roofline图,请确保在从GUI进行分析时选择了GPU Speed of Light roofline Chart部分。提供的详细或完整的集合包括此部分(图1)。
Figure 1. Detailed section set in Nsight Compute.
If you are profiling from the command-line, use the flag --set detailed or --set full. You can also manually select individual sections with the --section flag. The name of this new section is SpeedOfLight_RooflineChart.
Understanding the application
在本文中,将使用一个基于BerkeleyGW代码的小型应用程序。以独立的方式实现该应用程序的关键科学工作负载之一。为了简单起见,这个小应用程序抽象了部分BerkeleyGW代码,只运行一个内核。可以在GitLab上找到这个小应用程序,以及更详细的说明,提供试用。
Using roofline analysis step-by-step
GitLab存储库中使用了一些优化技术。为了演示NsightCompute中的所有功能(包括新添加的Roofline分析)如何相互补充以进行全面的性能分析,只讨论其中的两个步骤,步骤1和步骤3。
Baseline
在最初的串行CPU实现中,核心工作负载在三层嵌套的Fortran循环中表示:
do n1_loc = 1, ntband_dist ! O(1000)
do igp = 1, ngpown ! O(1000)
do ig = 1, ncouls ! O(10000)
注释表示每个回路的行程计数的近似长度。选择这种循环顺序是为了以优化的模式访问Fortran使用的列主内存布局的内存,因为代码中的许多数组都是以ig作为第一个索引,igp或n1_loc作为第二个索引来访问的。带有OpenACC的初始并行端口是GitLab存储库中提供的基线代码,如下所示,它折叠了三个循环,试图利用GPU上的大规模并行硬件。结果如下所示:
!$ACC PARALLEL LOOP GANG VECTOR reduction(+:...)
collapse(3)
do n1_loc = 1, ntband_dist ! O(1000)
do igp = 1, ngpown ! O(1000)
do ig = 1, ncouls ! O(10000)
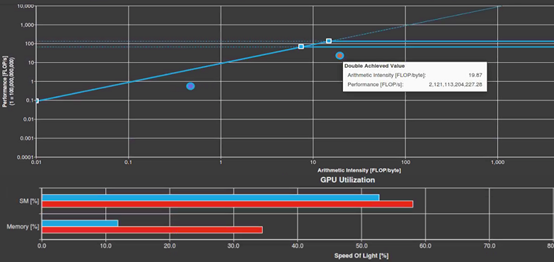
图2中的初始roofline分析表明,内核的算术强度很低,足以低于图表中的倾斜内存限制roofline。实现的运算强度为7.39 FLOP/byte,但V100双精度机器平衡点的算术强度为7.5。在这一点上,做了足够多的准备工作,使之成为计算界compute-bound。可能希望将算术强度增加到足以低于某个水平计算限制的上限。提供了一个更好的机会来最大化这个内核的计算性能。
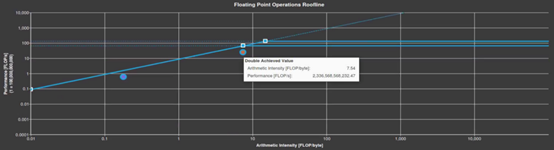
Figure 2. Baseline roofline analysis chart.
roofline图表还显示了单精度浮点运算的数据点。编译器会为这个内核生成一些这样的代码。它显示单个精确Roofline的水平线,即两条水平线中较高的一条。
Step 1: Unroll certain loops to gain arithmetic intensity
第三个循环的核心循环是连续运行的,这是第三个循环的循环。因为任何一对循环都会暴露至少一百万个自由度,所以仍然应该有足够的并行性来饱和高端GPU。要选择哪一个,可注意代码的内存访问模式。对于所有多维数组,n1_loc在访问之间的跨距最大,这也是由于column-major Fortran layout布局造成的。有效地使用GPU内存带宽需要合并访问,其中连续线程访问内存中的连续位置。所以,这都意味着n1_loc循环是这个实验最符合逻辑的目标。
!$ACC PARALLEL LOOP GANG VECTOR reduction(+:...)
collapse(2) do igp = 1, ngpown ! O(1000)
do ig = 1, ncouls ! O(10000)
!$ACC LOOP SEQ
do n1_loc = 1, ntband_dist ! O(1000)
当进行此更改时,内核实际上并没有加速。事实上,运行时的速度下降了10%,从1.74秒降到了1.92秒,但是,现在已经确定了内核的计算极限,双倍精度的算术强度大约为20当您进行此更改时,内核实际上并没有加速。事实上,运行时的速度下降了10%,从1.74秒降到了1.92秒,但是,你现在已经确定了内核的计算极限,双倍精度的算术强度大约为20浮点/字节(图3)。图4显示了Nsight计算光速部分的内存利用率也低得多,基线(红色)为34%,第1步优化后为11%(蓝色)。这意味着,如果你能使计算更有效,你也许能更接近峰值(图3)。图4显示了Nsight计算Speed of Light光速部分的内存利用率也低得多,基线(红色)为34%,第1步优化后为11%(蓝色)。这意味着,如果能使计算更有效,也许能更接近峰值。
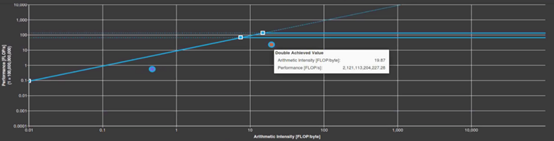
Figure 3. Roofline chart after Step 1.

Figure 4. Comparison of SM and memory utilization between baseline and step 1.
Step 3: Avoid high-latency instructions
高延迟指令可以显著降低warp问题的发生率并降低计算并发性,特别是当没有足够的线程来隐藏延迟时。但是,可以应用某些技巧来用较低延迟的指令替换这些指令。这里,演示两个,其中两个复数的除法wtilde和wdiff替换为倒数,ssx和I_eps_数组的绝对值计算被指数计算代替,因为只用于if/else条件评估。
! before delw = wtilde / wdiff
! after wdiffr = wdiff * CONJG(wdiff)
rden = 1.0d0 / wdiffr delw = wtilde * CONJG(wdiff) * rden
! before
ssxcutoff = sexcut * abs(I_eps_array(ig,igp))
if (abs(ssx) .gt. ssxcutoff .and. wx_array_t(iw,n1_loc) .lt. 0.0d0) ssx=0.0d0 !
after
ssxcutoff = sexcut**2 * I_eps_array(ig,igp) * CONJG(I_eps_array(ig,igp))
rden = ssx * CONJG(ssx)
if (rden .gt. ssxcutoff .and. wx_array_t(iw,n1_loc) .lt. 0.0d0) ssx=0.0d0
通过应用这些技巧,计算性能从2.5tflop/s提高到2.9tflop/s,代码的运行速度提高了一倍。运算强度已经下降到6.3 FLOP/byte,使得GPP重新回到带宽限制区域。这不是一个严重的问题,因为它在性能优化过程中经常发生。随着计算并发性的增加,需要读写更多的数据来满足计算需求。这可能会增加内存带宽的使用,从而导致带宽限制更大的Roofline图。
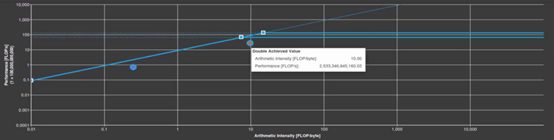
Figure 5. Roofline chart of GPP before applying tricks in Step 3.

Figure 6. Roofline chart of GPP after Step 3.
NsightCompute中丰富的特征集是相辅相成的,这种优化的效果也可以通过其他度量来验证。图7和图8显示,由于将delw=wtilde/wdiffr替换为rden=1.0d0/wdiffr,sampled active warps(全部或未发出)的数量和状态为wait(绿色条)的warp数量都显著下降。第三步的abs trick技巧也有同样的效果。
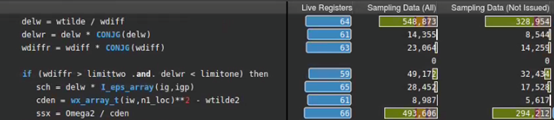
Figure 7. Change in sampling data after optimization transformations.
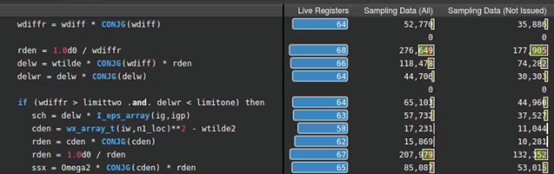
Figure 8. Another change in sampling data after optimization transformations.
Introducing hierarchical roofline analysis
到目前为止,文章展示了传统的Roofline模型,它只为GPU DRAM内存使用一个内存Roofline。然而,内存子系统比这更复杂,可以扩展Roofline模型来合并GPU的L1和L2缓存。这种分层Roofline模型在前面链接的论文中有详细描述。目前,Nsight Compute不支持分层Roofline模型,但它提供了一个可扩展的接口,允许创建自己的实现(图9)。使用GitLab存储库中的SpeedOfLight_HierarchicalDoubleRooflineChart部分文件,可以为步骤3创建一个分层的Roofline图表。

Figure 9. Hierarchical Roofline created with customized section files for Nsight Compute.
附加的对角线ceilings顶层表示给定算术强度的L1和L2性能限制。在这个图中,每个圆表示内存子系统(L1、L2或DRAM)的不同级别,并使用来自该级别的流量来计算其算术强度。例如,红点代表一级缓存,用内核的总浮点数除以一级缓存中移入和移出的字节数绘制。分层Roofline更详细地说明内存层次结构的哪个级别可能是瓶颈。此信息允许调整内存布局或访问模式以减少这些性能问题。
Summary
提高应用程序性能是一个迭代过程。了解内核所在的roofline图表部分是指导后续开发工作的关键技能。例如,如果看到明显地处于roofline图表中内存带宽受限的部分,那么最重要的事情就是内存访问模式,这样就可以避免浪费时间查看那些不会实质性地改变运行时的内核部分。此外,了解在每个迭代中的位置对于知道何时停止并继续下一个工作项非常重要。Roofline分析,结合Nsight Compute提供的其他分析部分,可以帮助了解内核相对于可达到的峰值系统限制的性能,因此值得将此工具添加到工具箱中。
对于那些对更深入感兴趣的人,文章只触及了roofline分析所能达到的表面。NERSC网站上有更多关于Roofline模型的详细信息,以及他们如何使用它来分析和提高性能。GitLab repo描述了另外两个优化步骤,可以使用最新版本的Nsight Compute进行实验。
用NVIDIA NsightcComputeRoofline分析加速高性能HPC的应用
标签:浮点运算 模型 就是 command 挑战 ble 程序 引入 lin
原文地址:https://www.cnblogs.com/wujianming-110117/p/14014560.html